将图片上传至 BeConverter,让它的视觉语言模型(VLM)将视觉元素分解为风格令牌,再将提取出来的提示词粘贴到 Midjourney、Stable Diffusion 或 FLUX 中——这就是将任何图片转化为可复现 AI 提示词的完整工作流,无需任何凭空猜测。
什么是逆向提示词?BeConverter 的工作原理是什么?
逆向提示词(Reverse Prompting)是将像素还原为生成模型能够理解的文本描述的过程。与其从零开始编写提示词、然后祈祷输出结果与参考图一致,不如直接从成品图片出发,提取定义其视觉风格的关键词、光照条件和美学标签。
BeConverter 使用视觉语言模型(VLM)来分析图片的艺术属性。模型会将你的图片与其训练数据进行比对,从而分类出渲染风格(3D 还是油画)、光照设置(体积光还是环境光)以及构图方式等特征。最终输出的是一段结构化的文本提示词,可直接用于任何图像生成器。
VLM 与 OCR 的区别:为什么普通扫描无法解读艺术
光学字符识别(OCR)读取的是文字——字母、数字、收据。而 VLM 读取的是艺术指导。正如 PromptsEra 所解释的:OCR 看到的是路牌上的”STOP”字样,而 VLM 能检测到八角形形状、褪色的红色油漆、景深效果以及太阳的角度——这些正是视觉复现所必需的细节。
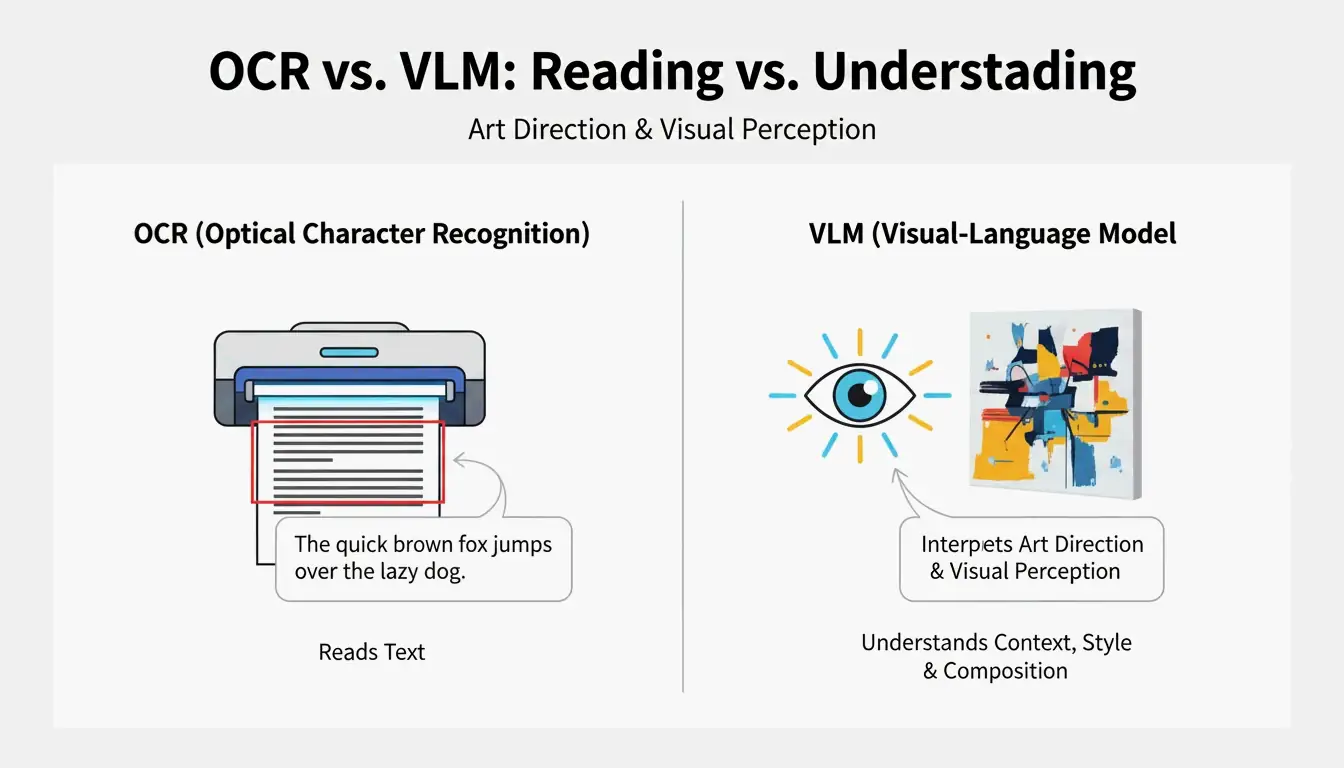
| 能力 | OCR | VLM |
|---|---|---|
| 读取文字 | 是 | 有限 |
| 识别光照 | 否 | 是 |
| 检测构图风格 | 否 | 是 |
| 提取调色信息 | 否 | 是 |
| 输出可直接使用的提示词 | 否 | 是 |
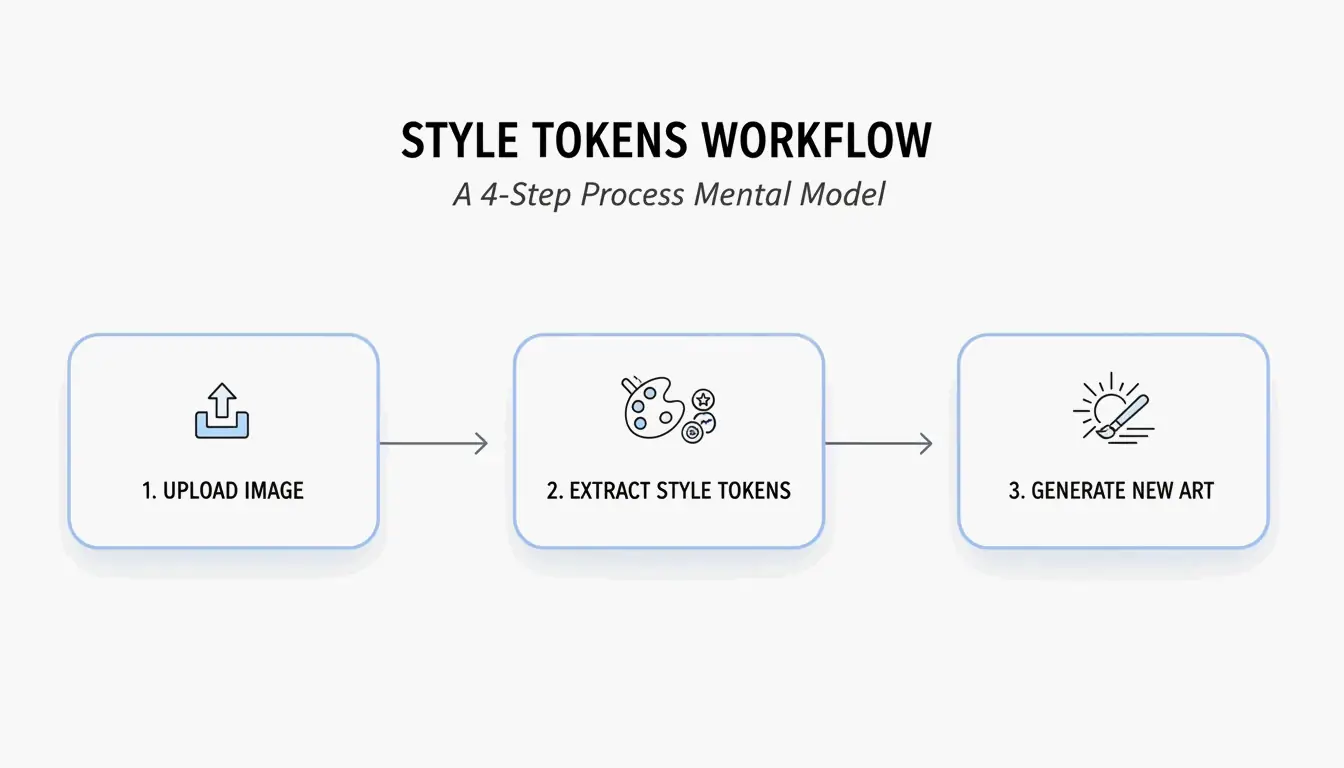
四步工作流:如何使用 BeConverter 进行 AI 提示词逆向
基于 PromptsEra 的风格令牌隔离策略,按以下步骤操作:
- 上传源图片 — 使用高分辨率文件。VLM 需要清晰的像素才能检测到”体积光”或”35mm 镜头颗粒感”等细微属性。
- 选择解析器 — 选择 CLIP Interrogator 可获得描述性的诗意提示词(适合 Midjourney),或选择 DeepDanbooru 获取逗号分隔的标签(适合 Stable Diffusion)。
- 隔离风格令牌 — 删除主体令牌(如”a cat”),仅保留风格标记(如”cyberpunk, neon rim lighting, 8k, cinematic depth of field”)。
- 粘贴到生成器中 — 将清理后的令牌复制到 Midjourney v7、Stable Diffusion 或 FLUX 中进行生成。
适配 2026 年模型的提示词策略:FLUX 与 Midjourney 的差异
每个模型对提示词的解读方式不同。PromptsEra 指出,”忧郁氛围”这类抽象描述在 Midjourney 中效果很好,但在 FLUX 中则效果不佳——FLUX 需要的是字面化的空间描述,例如”黑暗的房间,雨水打在窗户上,头顶荧光灯投射出长长的阴影”。
| 提示词风格 | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| 抽象/诗意 | 强 | 弱 | 中等 |
| 具象/空间 | 中等 | 强 | 中等 |
| 逗号分隔标签 | 中等 | 中等 | 强 |
| 反向提示词 | 支持(--no) |
支持 | 支持 |
科学怪人策略:从多张图片中融合风格
最有效的逆向工程技术是从不同来源融合风格令牌。使用 BeConverter 从图片 A 中提取光照,从图片 B 中提取主体渲染方式,然后将它们合并为一段提示词。
实现一致性融合的关键控制要素:
- 宽高比 — 必须明确设置(如 Midjourney 中使用
--ar 16:9),因为逆向工具无法推断你期望的画布比例。 - 反向提示词 — 始终添加排除项,如”blurry, deformed, low quality”。逆向工具只能检测图片中存在的元素,无法识别应该排除什么。
正如 MIT 金融工程实验室主任 Andrew Lo 所建议的:”始终要问大语言模型:你对什么不确定?你缺少什么信息?”将同样的原则应用到提示词重构中——在生成之前,先识别出重构提示词中的空白点。
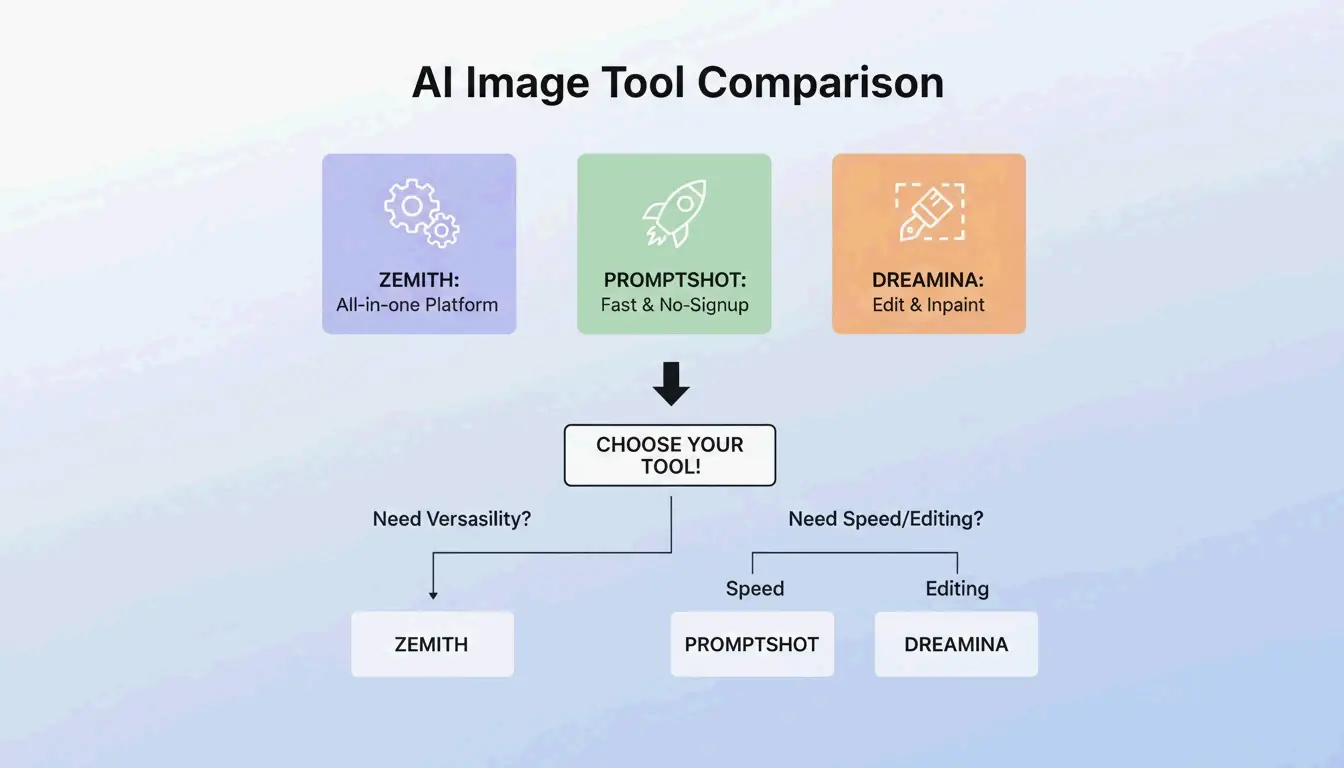
BeConverter vs. Zemith vs. PromptShot:工具横向对比(2026)
| 功能 | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| 解析器模式 | CLIP + DeepDanbooru | 多模型(25+) | 单次扫描 |
| 每日免费额度 | 有 | 100 次 | 无限制 |
| 是否需要注册 | 否 | 是 | 否 |
| 最适合 | 令牌隔离 | 一站式工作流 | 快速提取 |
| 输出格式 | 描述性文本 + 标签 | 按模型定制 | 提示词字符串 |
其他值得关注的选择:
- Zemith — 截至 2026 年已有超过 30,000 名用户。据 Zemith 介绍,它支持包括 GPT-5.5 在内的 25+ 模型,每日提供 100 次免费额度。
- PromptShot AI — 无需账号。PromptShot AI 提供了一个 5 步流程,专为需要快速”复刻和优化”AI 艺术作品的创作者设计。
- Dreamina(GPT Image 2) — 在同一窗口中生成和编辑。据 Dailyhunt 报道,GPT Image 2 模型支持在生成提示词后直接进行局部重绘和光照调整。
总结
使用 BeConverter 进行逆向提示词提取,可以在数秒内将任何参考图片转化为结构化的可复用 AI 提示词。上传图片,通过 CLIP 或 DeepDanbooru 提取风格令牌,隔离出艺术属性,然后粘贴到你选择的生成器中。为获得最佳效果,请根据目标模型调整提示词格式——Midjourney 用抽象描述、FLUX 用具象描述、Stable Diffusion 用标签格式——并始终添加反向提示词以保持输出质量。
常见问题
逆向提示词能否还原其他创作者使用的原始提示词?
不能。它是基于视觉分析重建的描述性近似结果。不同的 VLM 模型关注的属性各不相同,因此输出的是高质量的重构结果,而非隐藏的元数据或按键记录。
图片转提示词技术能否用于真实的手机照片?
可以。PromptsEra 指出,VLM 能够识别”黄金时刻光照”等真实世界属性或特定相机镜头,并将这些质感转化为用于艺术再创作的提示词。
使用从受版权保护的艺术作品中提取的提示词是否合法?
提示词是简短的文本字符串,通常不受版权保护。道德的做法是提取风格令牌来为自己的原创作品提供灵感。正如 PromptsEra 所指出的,试图精确复制受保护的角色可能引发法律问题——使用这些工具来学习技术,而非照搬作品。
发表回复