在商店里随手拿起任意一件商品,包装上总能找到一条条码。大多数情况下,它是一条 EAN-13——13 位数字横跨熟悉的黑白条带。但偶尔,在口香糖或润唇膏这类小物件上,你会看到一条更短、更紧凑的条码:EAN-8。
两种格式承担同样的任务——为每件产品分配一个唯一、可扫描的 ID——但它们面向不同的使用场景。本指南将系统讲解 EAN-13 与 EAN-8 之间的真实差异、各自的适用场景,以及它们如何融入更广泛的 GS1 条码生态。
EAN-13 与 EAN-8:核心差异一览
这两种格式最根本的区别在于它们承载多少位数字以及它们在标签上占据多大物理空间。
| 特性 | EAN-13 | EAN-8 |
|---|---|---|
| 位数 | 13 | 8 |
| 模块宽度 | 95 modules | 67 modules |
| 最小打印宽度 | ~1.5 inches (38 mm) | ~1 inch (26 mm) |
| 典型用途 | 标准零售产品 | 极小包装 |
| 管理机构 | GS1 | GS1 |
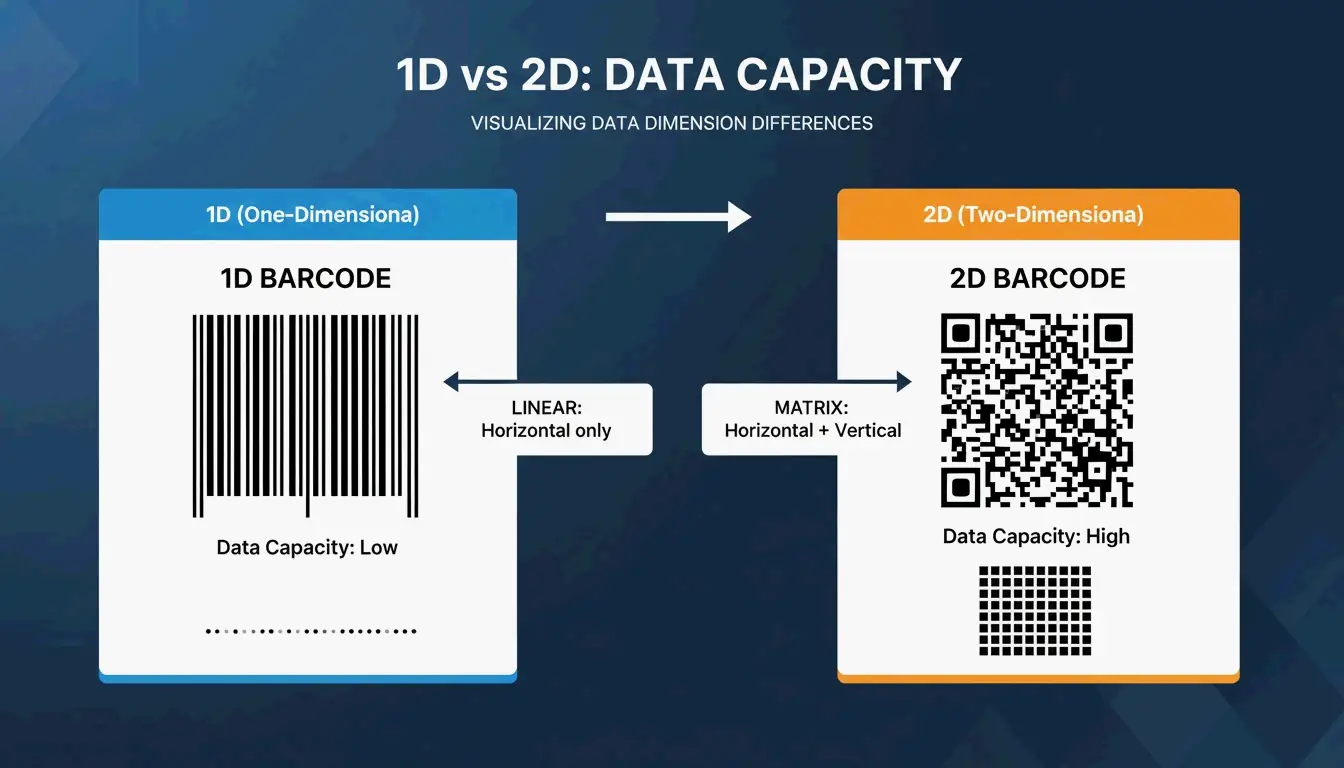
根据 Wikipedia,EAN-13 条码编码 13 位数字,由 95 个等宽模块组成。EAN-8 仅编码 8 位数字,因此条码要窄得多——宽度大约只有前者的三分之二。
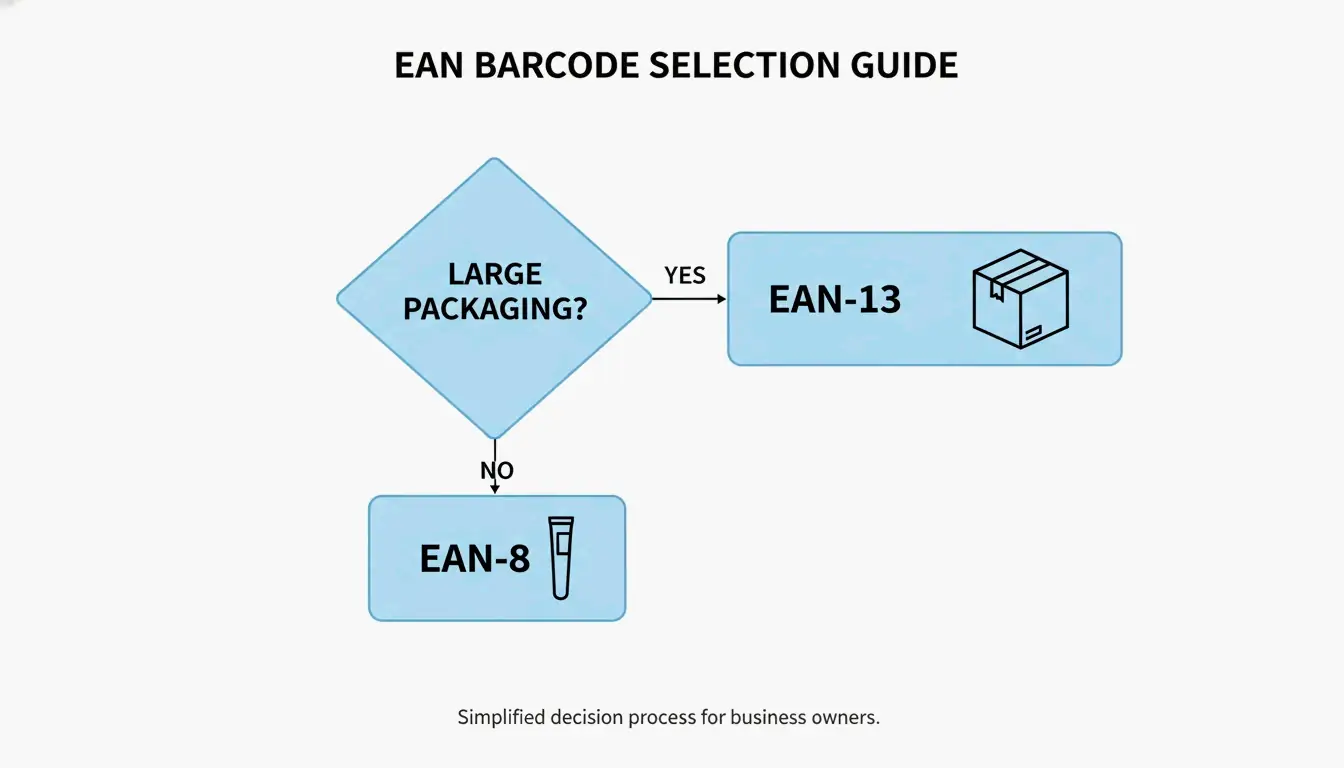
如何选择:一个简单的决策树
对于任何在两种格式间犹豫的人,逻辑其实很简单:
- 标准产品 —— 如果你的包装能容纳至少 1.5 inches 宽的条码,就选 EAN-13。它是全球零售的默认要求。
- 小物件 —— 如果产品上的可打印区域对 EAN-13 来说太挤,你可以申请 EAN-8。
容易被忽略的一个细节是 Quiet Zone——条码两侧的空白区域。根据 Wikipedia,EAN-13 条码通常在右侧带有一个 > 标识,用于标记 Quiet Zone 的起点。这个视觉标记帮助扫描仪识别条码边界,避免被相邻的图形或文字干扰。
何时该用 EAN-8:表面积法则
EAN-8 并不是免费的替代方案——它是专为那些确实放不下标准条码的产品而设的特殊格式。正如 Barcodes South Africa 所解释的,由于只有 8 位可用(远少于 13 位所能组合的唯一编码数量),GS1 成员组织只会向能够证明其包装太小、无法容纳 EAN-13 的厂商分配 EAN-8 号码。
实际中,你会在以下产品上看到 EAN-8:
– 单粒糖果或口香糖小包装
– 小型化妆品(润唇膏、睫毛膏)
– 种子或香料小包装
– 微型电子配件
如果你的产品有足够空间,EAN-13 始终是默认选择。
技术规范:EAN 格式是如何构成的?
黑白条带的背后,EAN 格式遵循一套精确的结构,通过 GS1(Global Standards 1) 体系确保每件产品获得全球唯一的 ID。
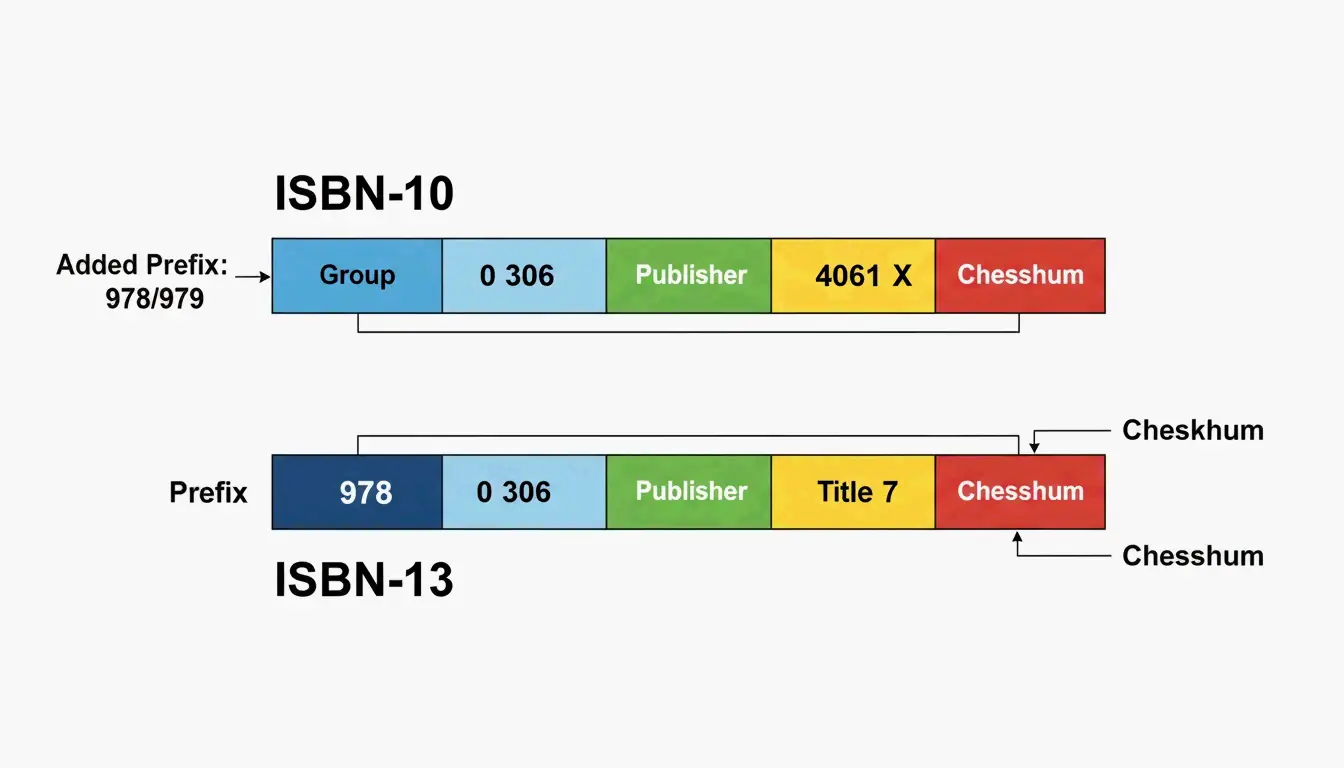
EAN-13 结构:
- GS1 前缀(3 位): 标识由哪个 GS1 成员组织发放该编码。例如,
590是波兰,400–440是德国。 - 厂商代码(长度可变): 分配给某家公司的唯一标识。
- 产品代码(长度可变): 公司为某件具体产品分配的编号(本质上即 SKU)。
- 校验码(1 位): 最后一位数字,由前面所有数字计算得出,用于捕捉扫描错误。
EAN-8 结构:
EAN-8 的运作方式不同——没有长度可变的厂商代码。编号机构直接分配产品代码。根据 Oracle,任何公司即便已持有 EAN-13 前缀,也可以申请 EAN-8,但这两个号码之间没有任何数学关联。

两种格式在捕捉错误方面都极为可靠。Wikipedia 指出,EAN-13 能检测出 100% of single-digit errors 和 90% of transposition errors(即相邻两位数字被对调的情形)。也就是说,即便扫描仪仅读错一条,校验码也几乎总能将其识别出来。
EAN-13 在美国能用吗?与 UPC-A 的对比
从事国际贸易的公司经常担心 EAN-13 能否在美国使用,因为美国历史上一直使用自己 12 位的 UPC-A 格式。
简短回答:完全可以。 名为“2005 Sunrise”的倡议——如今早已是长期生效的政策——要求美国和加拿大的每一台 POS 系统同时接受 EAN-13 与 UPC-A。事实上,EAN-13 在技术上就是 UPC-A 的超集。一条 UPC-A 条码不过是首位数字为 0 的 EAN-13。
在实际操作中这意味着:
– 如果你是全球化品牌,可以到处使用 EAN-13——无需单独的 UPC-A 码。
– 美国零售商无需任何配置改动即可扫描你的 EAN-13 产品。
EAN-13 体系内还有几个值得了解的特殊前缀。Bookland 前缀(978 和 979)将 ISBN 直接嵌入 EAN-13,使图书无论在何处出版,都能在任何标准零售结账台上扫描。
GTIN 整合与数据库归一化
EAN-13 与 EAN-8 都属于 Global Trade Item Number (GTIN) 家族。当不同长度的条码产品进入同一个数据库——比如仓储管理系统——时,就需要一种统一的格式。这正是 GTIN-14 的用武之地。
归一化的规则很简单:用前导零把较短的编码补齐。
| 条码 | GTIN-14 |
|---|---|
EAN-13: 4006381333931 |
04006381333931(补 1 个前导零) |
EAN-8: 96385074 |
00000096385074(补 6 个前导零) |
在 Oracle WMS 这类系统中,所有 GTIN 都右对齐并补齐至 14 位,这样单个数据库字段就能统一处理从一支润唇膏到一整托盘的所有商品。

如何计算校验码(Modulo-10,分步讲解)
任何 EAN 条码的最后一位都不是随机的——它是用 Modulo-10 算法算出来的。现代软件会自动完成这一步,但如果你需要编程生成条码或排查扫描问题,理解这套数学逻辑很有用。
示例:验证 EAN-13 400638133393? 的校验码
第 1 步——从右(不含校验位)开始,交替赋予 3 和 1 的权重:
| Position | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Digit | 4 | 0 | 0 | 6 | 3 | 8 | 1 | 3 | 3 | 3 | 9 | 3 |
| Weight | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 |
| Product | 4 | 0 | 0 | 18 | 3 | 24 | 1 | 9 | 3 | 9 | 9 | 9 |
第 2 步——将所有乘积相加:4 + 0 + 0 + 18 + 3 + 24 + 1 + 9 + 3 + 9 + 9 + 9 = 89
第 3 步——找到下一个 10 的倍数(即 90)。相减:90 − 89 = 1。
校验码即为 1,完整条码为 4006381333931。
在标签设计阶段做一次这样的核对很有价值——在打印成千上万张标签前发现一个错误的校验码,能为你节省时间和金钱。
结论
EAN-13 是零售条码化的全球主力——绝大多数产品用的都是它。EAN-8 是紧凑的替代方案,专门留给那些包装空间确实太挤、放不下标准条码的产品。两种格式都由 GS1 管理,都采用同一套 Modulo-10 校验码系统,并且都能被全球每一台现代 POS 系统可靠扫描——包括美国和加拿大。
最终的选择取决于表面积。如果你的包装能容纳至少 1.5 inches 宽的条码,就用 EAN-13。如果不行,就通过你所在地区的 GS1 办公室申请 EAN-8。无论哪种选择,你的产品都能在整个供应链中被正确扫描。
FAQ
我可以把 EAN-8 码转换为 EAN-13 码吗?
不行——它们是完全独立的标识符。EAN-8 号码由 GS1 直接分配,与你持有的 EAN-13 厂商前缀没有任何关联。如果你需要 EAN-13 码,就得使用你被分配的 EAN-13 号段中的号码。
EAN-13 在美国和加拿大被接受吗?
是的。自 2005 Sunrise 协议以来,北美每一台现代 POS 系统都能毫无障碍地扫描 UPC-A 和 EAN-13。如今大多数全球品牌都只用 EAN-13,以便在所有市场中保持简单统一。
如果我在期望 14 位编码的系统中扫描了一条 EAN-8 条码,会怎样?
系统会通过添加 6 个前导零的方式对该 8 位编码进行 zero-pad(零填充),以填满 GTIN-14 字段(例如 000000XXXXXXXX)。这是 Oracle WMS 等系统中的标准做法,用以在不同尺寸的产品之间保持数据库记录一致。