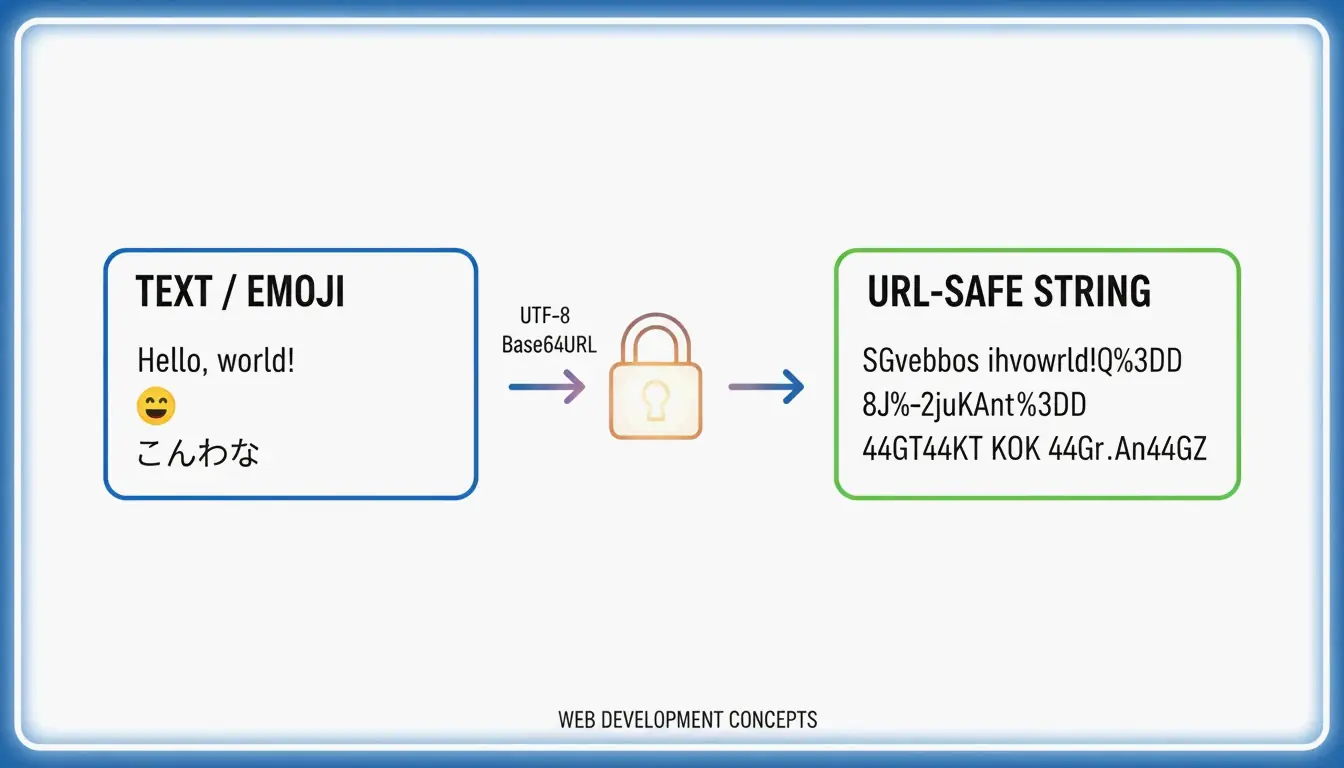
Para convertir UTF-8 a Base64URL, siga 4 pasos: (1) codifique el texto en bytes UTF-8, (2) aplique Base64 estándar, (3) reemplace + → - y / → _, (4) elimine el relleno = final. Esto produce una cadena segura para URL conforme a la RFC 4648, utilizada en JWT y cabeceras de API.
Base64 estándar vs. Base64URL
| Carácter | Base64 estándar | Base64URL | Motivo |
|---|---|---|---|
| 62.º carácter | + |
- |
+ significa espacio en las URL |
| 63.º carácter | / |
_ |
/ es un separador de ruta en las URL |
| Relleno | = obligatorio |
Omitido | = se convierte en %3D en las URL |
| Seguro para URL | No | Sí | Uso directo en cadenas de consulta y nombres de archivo |
Según la RFC 4648 §5, este “alfabeto seguro para URL y nombres de archivo” garantiza la compatibilidad entre sistemas.

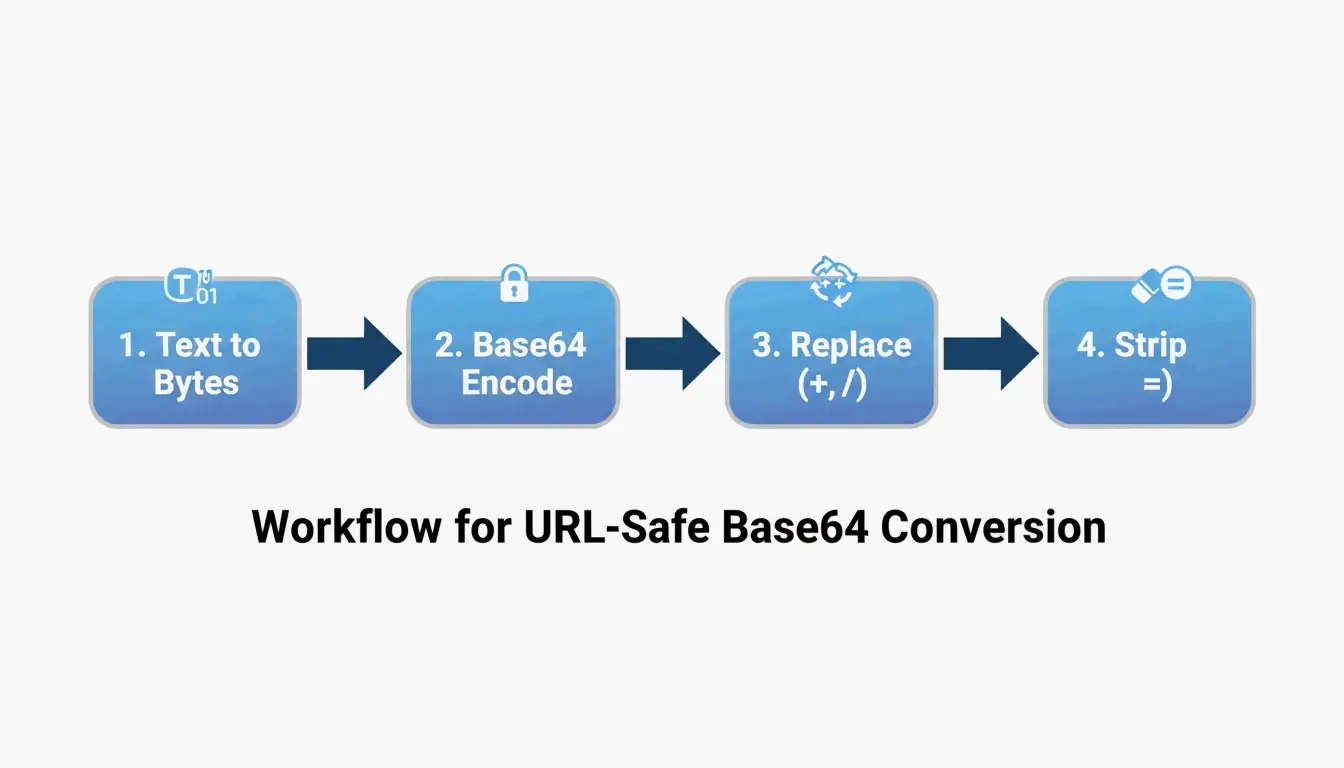
Proceso de conversión en 4 pasos
| Paso | Operación | Ejemplo (“Hello”) |
|---|---|---|
| 1 | Texto UTF-8 → bytes | H e l l o → matriz de bytes |
| 2 | Bytes → Base64 estándar | SGVsbG8= |
| 3 | Reemplazar + → -, / → _ |
No se necesitan cambios aquí |
| 4 | Eliminar el relleno = final |
SGVsbG8 |
La codificación Base64 aumenta el tamaño de los datos en un ~33 % según Wikipedia.
Gestión de Unicode y emojis
Según NextUtils, Base64 es una codificación, no un cifrado: transmite datos a través de canales exclusivamente textuales. Para gestionar Unicode y emojis sin distorsiones (“Mojibake”), utilice siempre TextEncoder para convertir primero a bytes UTF-8.
| Entrada | Sin TextEncoder | Con TextEncoder |
|---|---|---|
Hello 世界! 🌍 |
Mojibake / TypeError | Base64URL correcto |
Ejemplos de código
JavaScript (navegador) — compatible con Unicode
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3 — biblioteca estándar
Según AskPython:
import base64
data = "Hello 世界! 🌍"
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js — conversión mediante Buffer
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
Solución de problemas: errores de relleno
| Error | Causa | Solución |
|---|---|---|
binascii.Error: Incorrect padding |
Falta el relleno = |
Añada = hasta que la longitud sea múltiplo de 4 |
TypeError con atob() |
Caracteres no ASCII | Use TextEncoder primero |
| Salida ilegible | Codificación UTF-8 omitida | Siempre codifique a bytes antes de Base64 |
Según AskPython, calcule el relleno faltante: padding_needed = (4 - len(data) % 4) % 4, y luego añada esa cantidad de caracteres =.
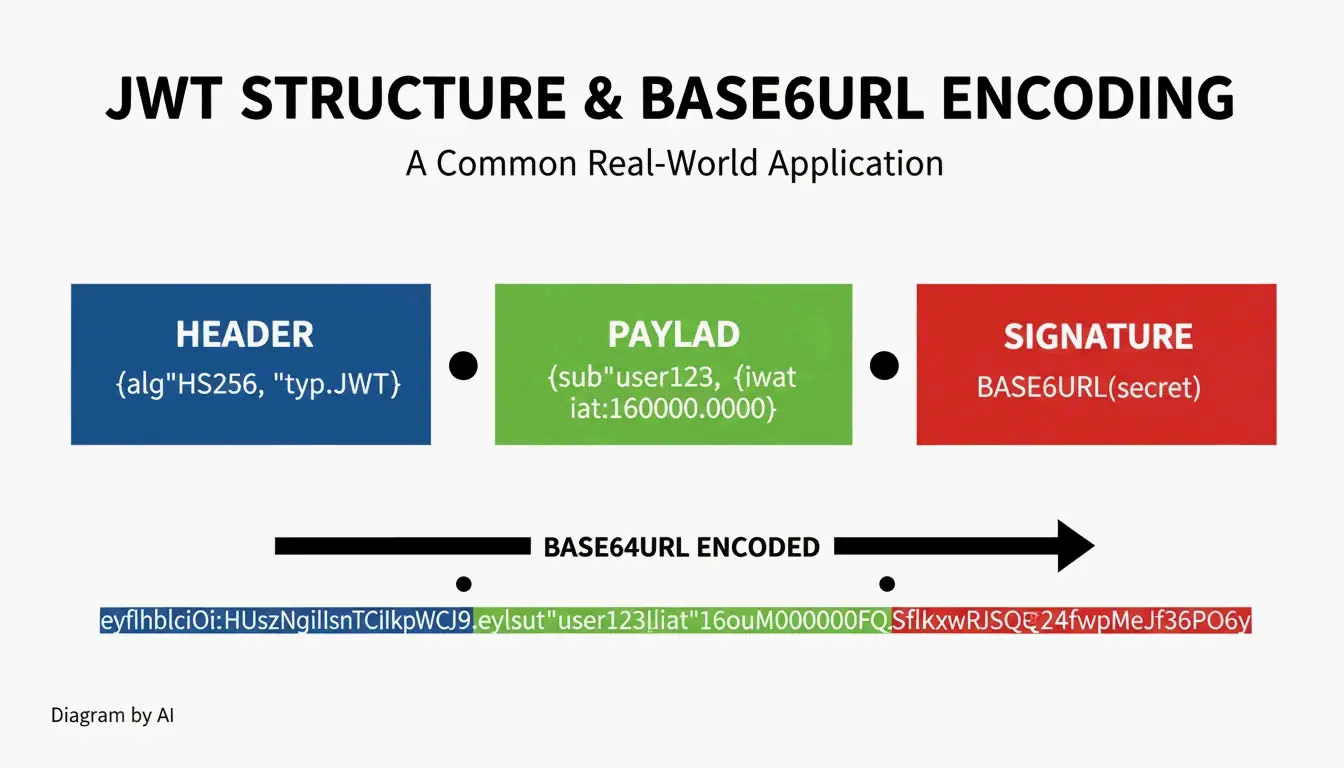
Casos de uso: JWT y Data URI
Estructura del JWT (JSON Web Token)
| Parte | Contenido | Codificación |
|---|---|---|
| Cabecera | Algoritmo + tipo de token | Base64URL |
| Payload | Claims (datos de usuario, expiración) | Base64URL |
| Firma | Firma HMAC o RSA | Base64URL |
Los JWT suelen comenzar con eyJ: la codificación Base64URL de { (llave de apertura JSON).
Base64 vs. Base64URL según el caso de uso
| Caso de uso | Codificación | Relleno |
|---|---|---|
| Tokens JWT | Base64URL | Omitido |
| Data URI (imágenes incrustadas) | Base64 estándar | Obligatorio |
| HTTP Basic Auth | Base64 estándar | Obligatorio |
| Parámetros de consulta URL | Base64URL | Omitido |
Conclusión
4 pasos: bytes UTF-8 → Base64 → reemplazar +/ por -_ → eliminar relleno. Use TextEncoder en JavaScript, base64.urlsafe_b64encode() en Python, Buffer en Node.js. Siga la RFC 4648 para la compatibilidad entre sistemas. Base64URL es una codificación, no un cifrado: use AES-256 o TLS para la seguridad.
Preguntas frecuentes
¿Es Base64URL lo mismo que cifrado?
No. Base64URL es una codificación reversible: cualquiera puede decodificarlo sin clave. Use AES-256 o TLS/SSL para proteger datos sensibles.
¿Por qué Base64URL falla en un decodificador Base64 estándar?
Los decodificadores estándar esperan +, / y el relleno =. Base64URL usa -, _ y omite el relleno. Invierta los reemplazos de caracteres y restaure el relleno antes de decodificar.
¿Por qué se omite el relleno en los JWT?
El carácter = se convierte en %3D en las URL, lo que alarga las cadenas y dificulta su lectura. La RFC 4648 permite su omisión porque los decodificadores pueden reconstruir la longitud original sin marcadores de relleno.
Deja una respuesta