Sube una imagen a BeConverter, deja que su Vision-Language Model (VLM) descomponga el visual en tokens de estilo y luego pega el prompt extraído en Midjourney, Stable Diffusion o FLUX. Ese es el flujo de trabajo completo para convertir cualquier imagen en un prompt de IA reproducible, sin necesidad de prueba y error.
Qué es el Reverse Prompting y cómo funciona BeConverter
El reverse prompting convierte píxeles en texto que un modelo generativo puede entender. En lugar de escribir un prompt desde cero esperando que el resultado coincida con una referencia, se parte de la imagen terminada y se extraen las palabras clave exactas, las condiciones de iluminación y las etiquetas estéticas que definen su aspecto.
BeConverter utiliza un Vision-Language Model (VLM) para analizar las propiedades artísticas de una imagen. El modelo compara tu foto con sus datos de entrenamiento para clasificar atributos como el estilo de renderizado (3D vs. pintura al óleo), la configuración de iluminación (volumétrica vs. ambiental) y la composición. El resultado es un prompt de texto estructurado que puedes introducir en cualquier generador de imágenes.
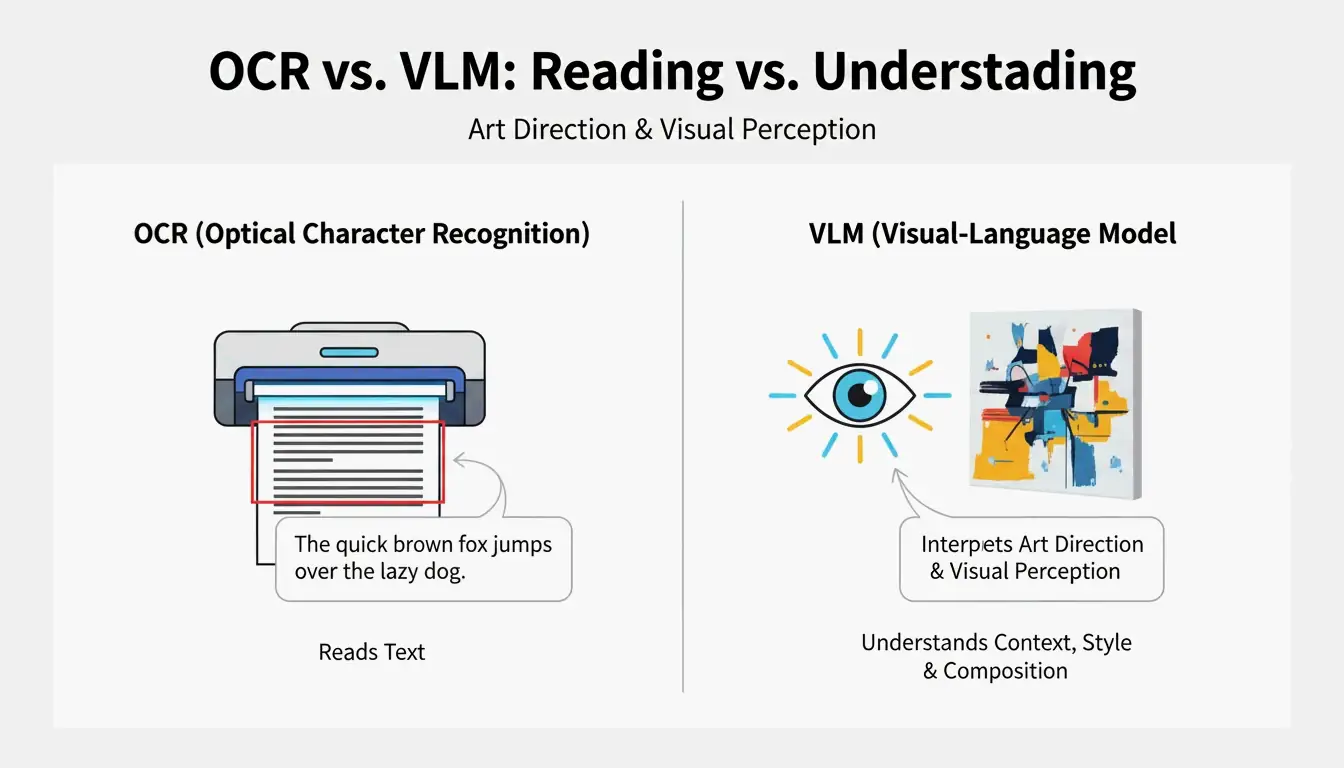
VLM vs. OCR: Por qué el escaneo tradicional no puede leer arte
El reconocimiento óptico de caracteres (OCR) lee texto: letras, números, recibos. Un VLM lee la dirección de arte. Como explica PromptsEra, donde el OCR lee la palabra «STOP» en una señal, un VLM detecta la forma octagonal, la pintura roja descolorida, la profundidad de campo y el ángulo del sol, detalles esenciales para la reproducción visual.
| Capacidad | OCR | VLM |
|---|---|---|
| Lee texto | Sí | Limitado |
| Identifica iluminación | No | Sí |
| Detecta estilo de composición | No | Sí |
| Extrae gradación de color | No | Sí |
| Genera texto listo para prompt | No | Sí |
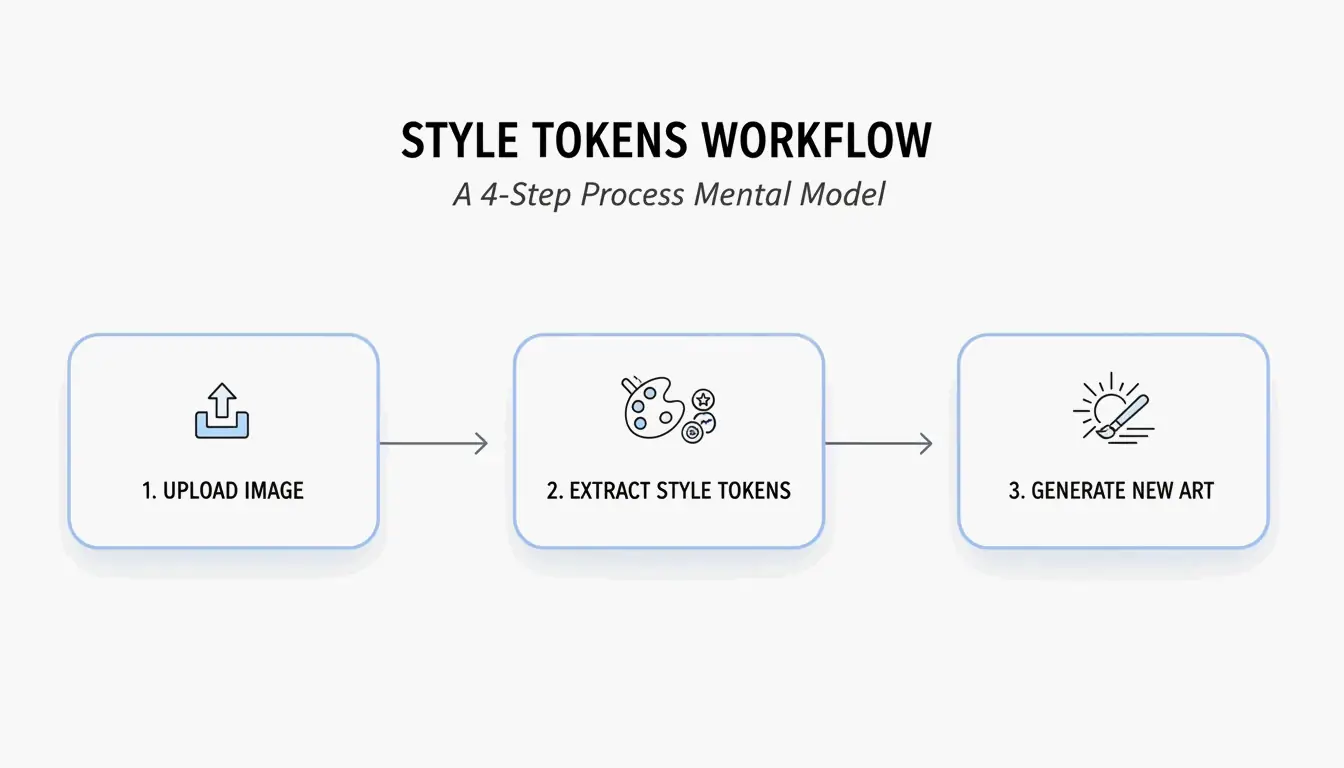
Flujo de trabajo en 4 pasos: Cómo crear prompts de IA con BeConverter
Basado en la Estrategia de Aislamiento de Tokens de Estilo de PromptsEra, sigue esta secuencia:
- Sube tu imagen de origen — Usa un archivo de alta resolución. El VLM necesita píxeles claros para detectar atributos sutiles como «iluminación volumétrica» o «grano de lente de 35mm.»
- Elige tu interrogador — Selecciona CLIP Interrogator para prompts descriptivos y poéticos (ideal para Midjourney) o DeepDanbooru para etiquetas separadas por comas (ideal para Stable Diffusion).
- Aísla los tokens de estilo — Elimina los tokens del sujeto (por ejemplo, «un gato») y conserva solo los marcadores de estilo (por ejemplo, «cyberpunk, iluminación de borde neón, 8k, profundidad de campo cinematográfica»).
- Pega en tu generador — Copia los tokens limpios en Midjourney v7, Stable Diffusion o FLUX y genera.
Adaptación de prompts para modelos de 2026: FLUX vs. Midjourney
Cada modelo interpreta los prompts de forma diferente. PromptsEra señala que las descripciones abstractas como «atmósfera melancólica» funcionan bien en Midjourney pero fracasan en FLUX, que requiere descripciones espaciales literales como «habitación oscura con lluvia golpeando la ventana, luz fluorescente superior proyectando sombras largas.»
| Estilo de Prompt | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| Abstracto/poético | Fuerte | Débil | Moderado |
| Literal/espacial | Moderado | Fuerte | Moderado |
| Etiquetas separadas por comas | Moderado | Moderado | Fuerte |
| Prompts negativos | Soportado (--no) |
Soportado | Soportado |
La estrategia Frankenstein: Fusionar estilos de múltiples imágenes
La técnica de ingeniería inversa más efectiva combina tokens de estilo de diferentes fuentes. Usa BeConverter para extraer la iluminación de la Imagen A y el renderizado del sujeto de la Imagen B, y luego fusiónalos en un solo prompt.
Controles clave para una fusión consistente:
- Relación de aspecto — Establécela explícitamente (por ejemplo,
--ar 16:9para Midjourney) ya que las herramientas de ingeniería inversa no pueden inferir el lienzo deseado. - Prompts negativos — Siempre añade exclusiones como «borroso, deformado, baja calidad.» Las herramientas de ingeniería inversa solo detectan lo que está presente; no pueden identificar lo que debería estar ausente.
Como aconseja Andrew Lo, Director del Laboratorio de Ingeniería Financiera del MIT: «Siempre pregúntale al LLM, ¿sobre qué tienes incertidumbre? ¿Qué información te falta?» Aplica el mismo principio: identifica las lagunas en tu prompt reconstruido antes de generar.
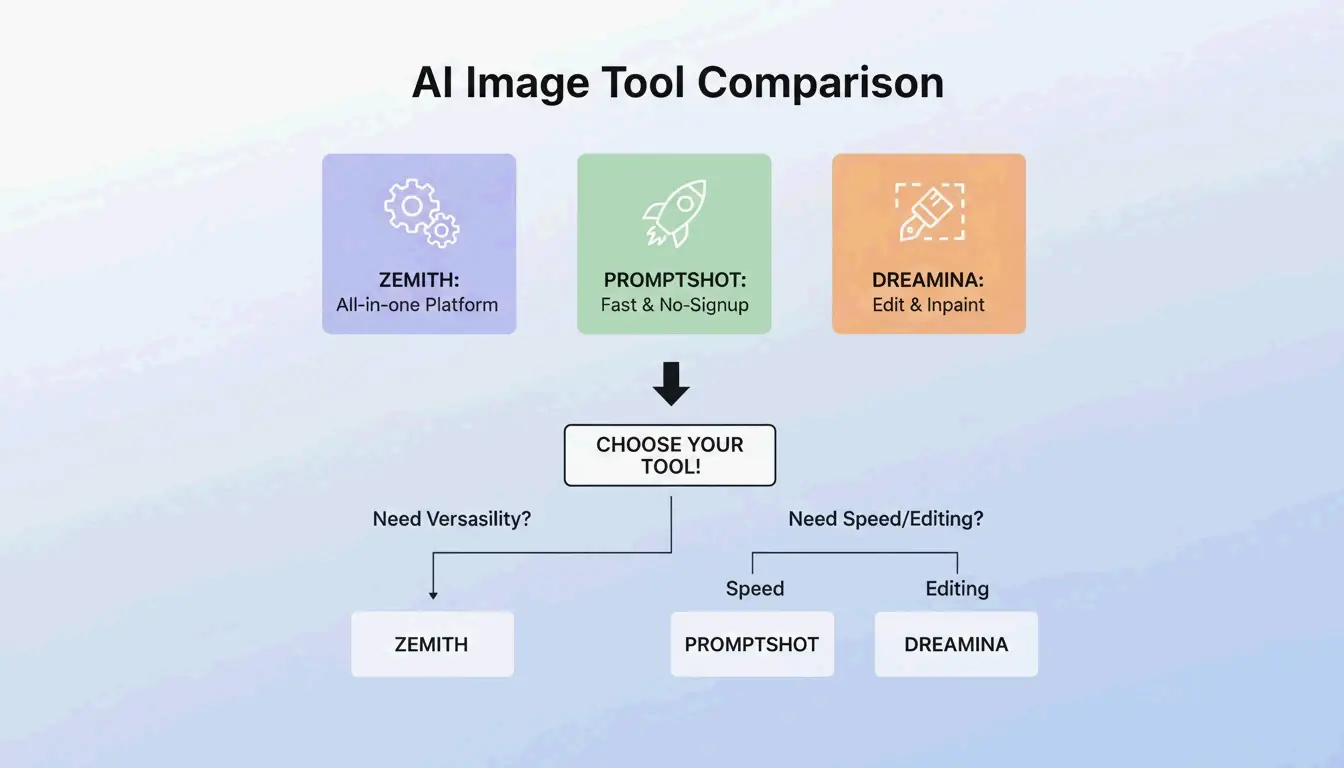
BeConverter vs. Zemith vs. PromptShot: Comparativa de herramientas (2026)
| Característica | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| Modos de interrogador | CLIP + DeepDanbooru | Multi-modelo (25+) | Pase único |
| Créditos gratuitos diarios | Sí | 100 | Ilimitados |
| Registro requerido | No | Sí | No |
| Mejor para | Aislamiento de tokens | Flujo de trabajo todo en uno | Extracciones rápidas |
| Formato de salida | Descriptivo + etiquetas | Específico por modelo | Cadena de prompt |
Opciones adicionales destacables:
- Zemith — Más de 30.000 usuarios a fecha de 2026. Según Zemith, es compatible con más de 25 modelos incluyendo GPT-5.5 con 100 créditos diarios.
- PromptShot AI — No necesita cuenta. PromptShot AI ofrece un proceso de 5 pasos diseñado para creadores que necesitan «recrear y mejorar» arte de IA rápidamente.
- Dreamina (GPT Image 2) — Genera y edita en una sola ventana. Según Dailyhunt, el modelo GPT Image 2 permite inpainting y ajustes de iluminación directamente después de la generación del prompt.
Conclusión
El reverse prompting con BeConverter convierte cualquier imagen de referencia en un prompt de IA estructurado y reutilizable en segundos. Sube tu imagen, extrae los tokens de estilo con CLIP o DeepDanbooru, aísla los atributos artísticos y pégalos en tu generador preferido. Para obtener los mejores resultados, adapta el formato del prompt a tu modelo de destino: abstracto para Midjourney, literal para FLUX, basado en etiquetas para Stable Diffusion, y siempre incluye prompts negativos para mantener la calidad del resultado.
Preguntas frecuentes
¿El reverse prompting puede recuperar el prompt original exacto usado por otro creador?
No. Reconstruye una aproximación descriptiva basada en el análisis visual. Diferentes modelos VLM priorizan diferentes atributos, por lo que el resultado es una reconstrucción de alta calidad, no metadatos ocultos ni recuperación de pulsaciones de teclas.
¿La tecnología de imagen a prompt funciona con fotografías reales de smartphone?
Sí. PromptsEra señala que los VLM pueden identificar atributos del mundo real como «iluminación de hora dorada» o lentes de cámara específicas y traducir esas texturas en prompts para reinterpretación artística.
¿Es legal usar prompts extraídos de obras de arte con derechos de autor?
Los prompts son cadenas de texto cortas y normalmente no están cubiertos por derechos de autor. El enfoque ético es extraer tokens de estilo para informar tu propio trabajo original. Como señala PromptsEra, intentar replicar exactamente un personaje protegido puede generar problemas legales. Usa estas herramientas para aprender técnicas, no para copiar.
Deja una respuesta