需要把电子表格、CSV 或 JSON 文件转换成干净的 Markdown 表格吗?在 2026 年,这个过程很直接——选择合适的工具取决于你是在做一次性快速转换,还是在大规模自动化文档。
本指南涵盖每种场景下的最佳工具:用于手工操作的可视化编辑器、用于自动化的 CLI 工具,以及让文档与代码库保持同步的 CI/CD 集成。
顶级工具一览
| 工具 | 最适合 | 类型 | 关键优势 |
|---|---|---|---|
| TableGenerator.com | 快速可视化编辑 | 网页(客户端) | 网格编辑器、对齐控制 |
| AnywayData | 混乱的 JSON 文件 | 网页 / 库 | 扁平化嵌套结构、AST 解析 |
| MarkItDown(微软) | Excel/Word 自动化 | Python CLI | 保留 Office 文件的表头和表格网格 |
| Pandoc | 多格式转换 | CLI | 支持数十种格式,大规模下稳定 |
| EaseCloud | Excel → GFM | 网页 | 简单的浏览器端转换器 |
| GoConverter | Excel → GFM | 网页 | 带对齐选项的快速转换 |
据 DasRoot(2026),现代 Markdown 工具对中等规模数据集可以 每秒处理 15–30 个表格——而且最好的工具使用客户端处理,意味着你的数据永远不会离开浏览器。
为什么 GFM 合规很重要
GitHub Flavored Markdown(GFM) 是 GitHub、GitLab 和 Discord 使用的特定方言。最初的 Markdown 规范根本不支持表格——是 GFM 加上了熟悉的”竖线和破折号”语法。一个合规 GFM 的生成器能确保你的表格以粗体表头和对齐列正确渲染,而不是显示为原始文本。

如何把 Excel 和 CSV 转为 GFM
过程分两步:
- 导出为 CSV —— 把 Excel 或 Google Sheets 文件保存为 CSV。这会剥离繁重的格式,同时保留数据网格。
- 转换 —— 使用像 EaseCloud 或 GoConverter 这样的浏览器端工具生成 GFM 代码。
列对齐
GFM 通过分隔行(表头下方的那一行)控制对齐:
| 语法 | 对齐方式 |
|---|---|
:--- |
左对齐(默认) |
---: |
右对齐 |
:---: |
居中对齐 |
转义竖线字符
Markdown 用 | 标记列的边界。如果你的数据包含竖线(例如在代码片段或公式中),它会破坏表格。用以下方式转义:
- HTML 实体:
| - 反斜杠:
\| - 代码反引号:
|
处理大型数据集(100+ 行)
对于超过 100 行的数据集,基于网页的可视化编辑器可能会卡顿。现代转换器使用增量解析来保持响应。据 AnywayData,使用”成对组合数据逻辑”可以把必需的测试用例减少 90–99%,这在记录复杂配置时很有帮助。
对于真正大型的数据集,考虑拆分成多个表格,或在 Markdown 版本旁边提供一个可下载的 CSV 链接。
把 JSON 转为 GFM:扁平化嵌套数据
JSON 是层级结构——数据像俄罗斯套娃一样嵌套。Markdown 表格是扁平的二维网格。转换需要扁平化逻辑:
user.address.city → "User Address City"(单列表头)
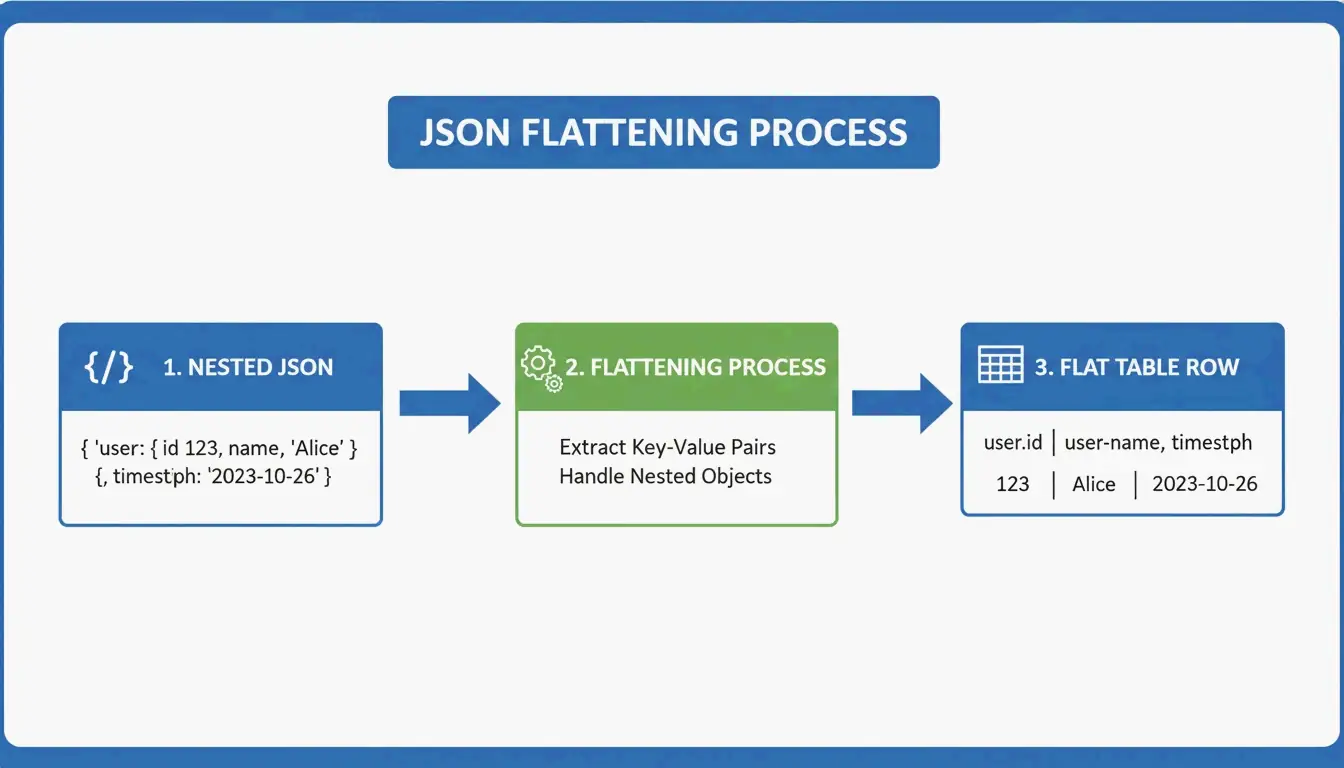
AnywayData 的 Grid Table Editor 在这方面表现出色——它让你导入 JSON 并手动控制嵌套层如何被扁平化。转换的质量取决于工具是否使用 AST(抽象语法树)构建,而不是简单的文本模式匹配。基于 AST 的解析器会构建数据结构的逻辑映射,处理更深的嵌套和不一致的 schema 时准确得多。
用 CI/CD 自动化
对于工程团队来说,手工转换是浪费时间。把表格生成集成到你的 CI/CD 流水线中,能确保 README 文件自动保持最新:
- 在构建过程中把 JSON API 响应转换为 GFM
- 把文档当代码对待——数据变化时它就更新
- 防止代码库中出现信息陈旧或不正确的常见问题
像 Terraform-docs v0.17.0(2026)这样的工具会自动把资源表格直接注入 README 文件——证明在基础设施级文档方面,CLI 工具往往胜过网页界面。
MarkItDown vs. Pandoc:你该用哪个?
| 因素 | MarkItDown(微软) | Pandoc |
|---|---|---|
| 针对优化 | Office 文件(Excel、Word) | 通用文档转换 |
| Markdown 方言 | 以 GFM 为重点 | CommonMark、GFM 及许多其他 |
| 最适合 | 快速 XLSX → GitHub 表格 | 多格式、大批量 CLI 工作 |
| 最新版本 | 2026 | 3.9.0.2(稳定) |
| 速度 | 对单个 Office 文件更快 | 更适合批量处理 |
| 使用时机 | 你需要转换一个 Excel 文件 | 你需要在数十种格式间转换 |
对大多数开发者来说,MarkItDown 在常见场景(Excel → GitHub 表格)下更快。当你需要处理多种文档格式或运行大规模批量转换时,Pandoc 是更好的选择。
结论
在 2026 年把数据转换为 GFM 表格,归结起来就是数据量和工作流:
- 一次性编辑 → 用 TableGenerator.com 或 AnywayData 进行可视化控制
- 重复的 Office 转换 → 把 MarkItDown 集成到你的 Python 工作流中
- 多格式或大批量 → 用 Pandoc 进行 CLI 批量处理
- 基础设施文档 → 用 terraform-docs 或自定义脚本进行 CI/CD 自动化
关键原则:文档应该随数据更新而更新。 自动化转换能防止表格过时,并让你的项目文档保持可信。
常见问题
如何在 Markdown 表格单元格内转义竖线字符(|)?
使用 HTML 实体 | 而不是字面竖线。或者,如果你的 GFM 解析器支持,使用反斜杠转义 \|,或者把内容包裹在代码反引号中。这三种方法都能防止竖线被解释为列分隔符。
GFM 支持合并单元格或多行内容吗?
不支持。 标准 GFM 不支持 colspan 或 rowspan。每个单元格必须独立。对于单元格内的多行内容,使用 HTML <br> 标签强制换行,同时把数据保持在单行中。
对于超过 100 行的数据集,最佳方法是什么?
跳过基于网页的可视化编辑器(它们会卡顿)。改用像 MarkItDown 或 Pandoc 这样的 CLI 工具。如果生成的表格对单个页面来说太大,把它拆分成多个表格,或者提供一个可下载 CSV 文件的链接,以保持可读性。
发表回复