Upload een afbeelding naar BeConverter, laat het Vision-Language Model (VLM) de visual ontleden in stijltokens, en plak de geëxtraheerde prompt vervolgens in Midjourney, Stable Diffusion of FLUX. Dat is de volledige workflow om elke visual om te zetten in een reproduceerbare AI-prompt — zonder giswerk.
Wat Is Reverse Prompting en Hoe Werkt BeConverter?
Reverse prompting zet pixels terug om naar tekst die een generatief model kan begrijpen. In plaats van een prompt vanaf nul te schrijven en te hopen dat de uitvoer overeenkomt met een referentie, begin je met het uiteindelijke beeld en extraheer je de exacte trefwoorden, lichtomstandigheden en esthetische tags die het uiterlijk definiëren.
BeConverter gebruikt een Vision-Language Model (VLM) om de artistieke eigenschappen van een afbeelding te analyseren. Het model vergelijkt je foto met zijn trainingsdata om attributen te classificeren zoals renderstijl (3D vs. olieverf), lichtopstelling (volumetrisch vs. omgevingslicht) en compositie. Het resultaat is een gestructureerde tekstprompt die je in elke beeldgenerator kunt gebruiken.
VLM vs. OCR: Waarom Standaard Scanning Geen Kunst Kan Lezen
Optical Character Recognition (OCR) leest tekst — letters, cijfers, bonnetjes. Een VLM leest kunstregie. Zoals PromptsEra uitlegt: waar OCR het woord “STOP” op een bord ziet, detecteert een VLM de achthoekige vorm, de verbleekte rode verf, de scherptediepte en de stand van de zon — details die essentieel zijn voor visuele reproductie.
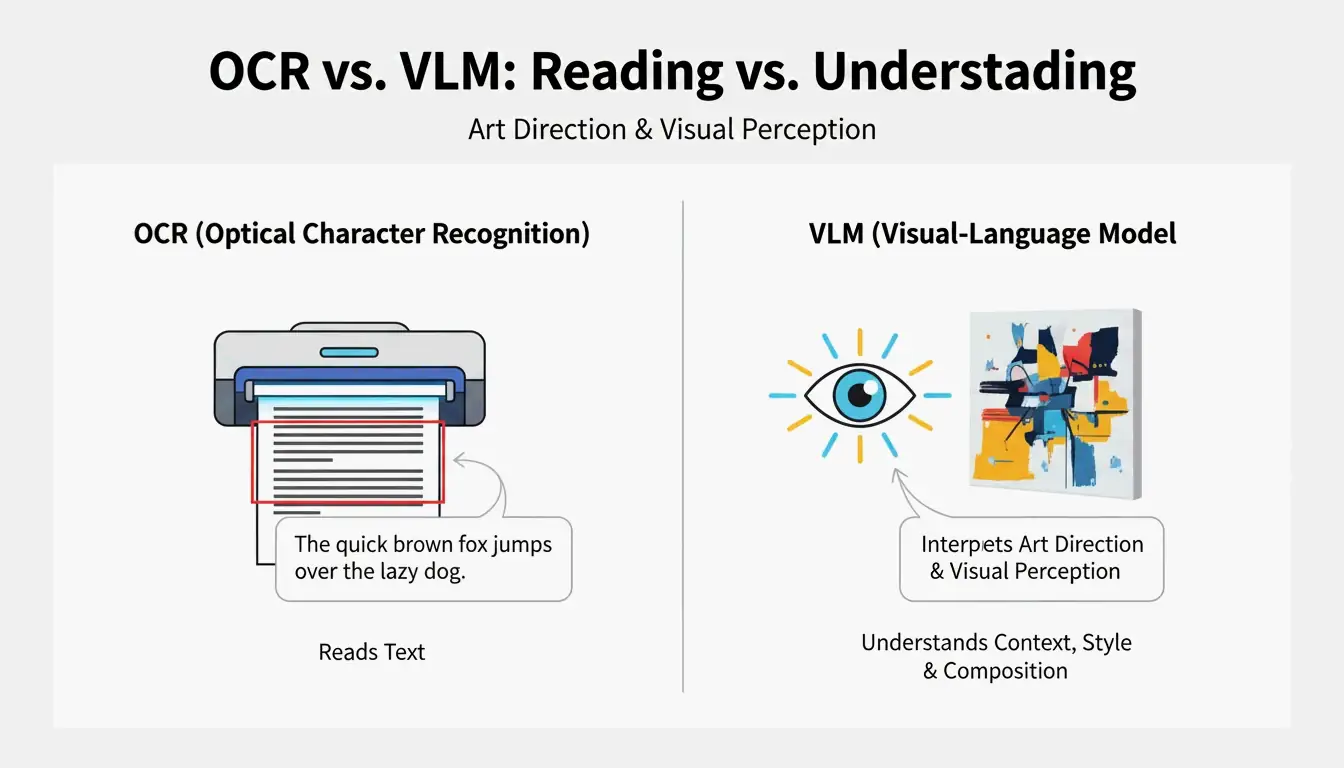
| Mogelijkheid | OCR | VLM |
|---|---|---|
| Leest tekst | Ja | Beperkt |
| Identificeert belichting | Nee | Ja |
| Detecteert compositiestijl | Nee | Ja |
| Extraheert kleurgrading | Nee | Ja |
| Levert prompt-gereede tekst | Nee | Ja |
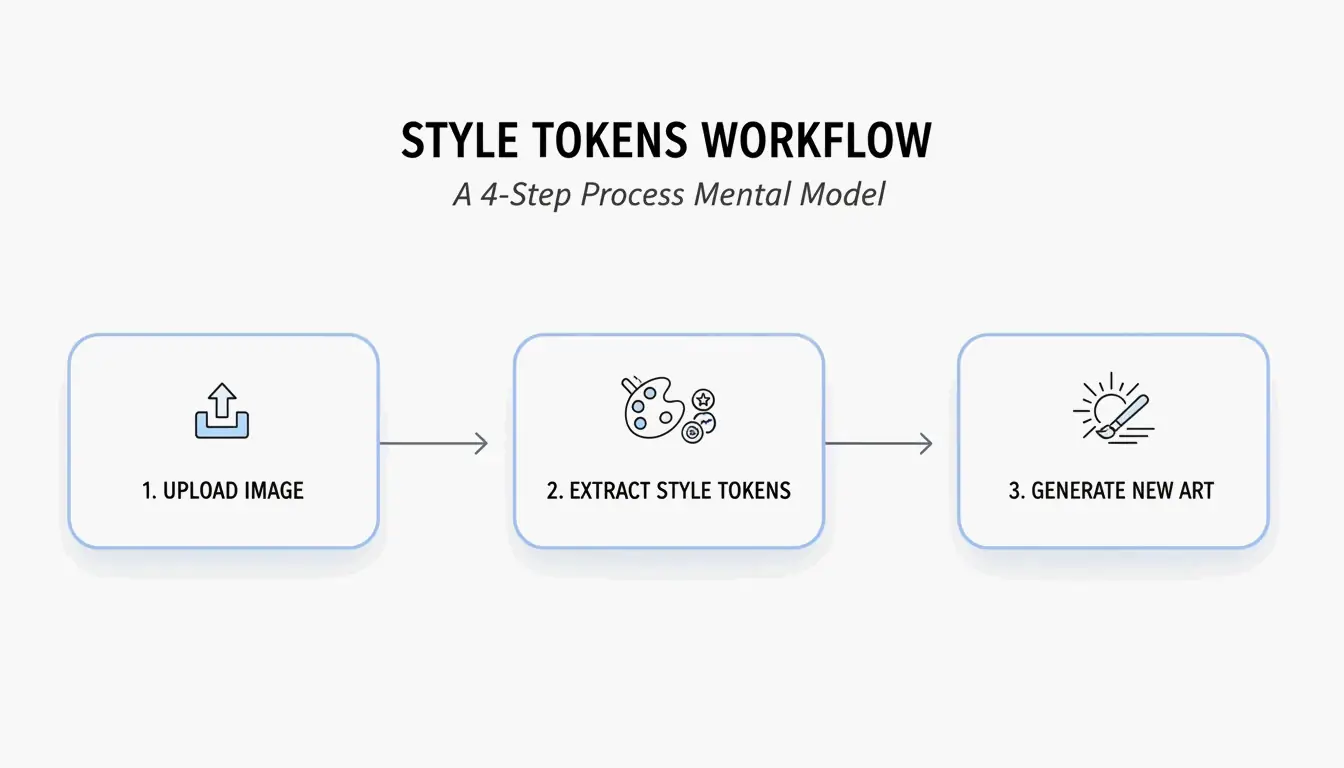
Workflow in 4 Stappen: AI-Prompting met BeConverter
Gebaseerd op de Style Token Isolation Strategy van PromptsEra, volg deze volgorde:
- Upload je bronafbeelding — Gebruik een bestand met hoge resolutie. Het VLM heeft duidelijke pixels nodig om subtiele attributen te detecteren zoals “volumetric lighting” of “35mm lens grain.”
- Kies je interrogator — Selecteer CLIP Interrogator voor beschrijvende, poëtische prompts (ideaal voor Midjourney) of DeepDanbooru voor door komma’s gescheiden tags (ideaal voor Stable Diffusion).
- Isoleer stijltokens — Verwijder de onderwerptokens (bijv. “een kat”) en behoud alleen de stijlmarkeringen (bijv. “cyberpunk, neon rim lighting, 8k, cinematic depth of field”).
- Plak in je generator — Kopieer de opgeschoonde tokens naar Midjourney v7, Stable Diffusion of FLUX en genereer.
Prompts Aanpassen voor 2026-modellen: FLUX vs. Midjourney
Elk model interpreteert prompts anders. PromptsEra merkt op dat abstracte beschrijvingen zoals “melancholische sfeer” goed werken in Midjourney maar falen in FLUX, dat letterlijke ruimtelijke beschrijvingen vereist zoals “donkere kamer met regen tegen het raam, overhead tl-verlichting die lange schaduwen werpt.”
| Promptstijl | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| Abstract/poëtisch | Sterk | Zwak | Matig |
| Letterlijk/ruimtelijk | Matig | Sterk | Matig |
| Door komma’s gescheiden tags | Matig | Matig | Sterk |
| Negatieve prompts | Ondersteund (--no) |
Ondersteund | Ondersteund |
De Frankenstein-strategie: Stijlen Samenvoegen uit Meerdere Afbeeldingen
De meest effectieve reverse engineering-techniek combineert stijltokens uit verschillende bronnen. Gebruik BeConverter om belichting uit Afbeelding A en onderwerprendering uit Afbeelding B te extraheren, en voeg ze vervolgens samen tot één prompt.
Belangrijke instellingen voor consistente samenvoeging:
- Beeldverhouding — Stel expliciet in (bijv.
--ar 16:9voor Midjourney) aangezien reverse tools niet kunnen afleiden wat je bedoelde canvas is. - Negatieve Prompts — Voeg altijd uitsluitingen toe zoals “blurry, deformed, low quality.” Reverse tools detecteren alleen wat aanwezig is; ze kunnen niet identificeren wat ontbrekend zou moeten zijn.
Zoals Andrew Lo, directeur van MIT’s Laboratory for Financial Engineering, adviseert: “Vraag de LLM altijd: waar ben je onzeker over? Welke informatie mis je?” Pas hetzelfde principe toe — identificeer de hiaten in je gereconstrueerde prompt voordat je genereert.
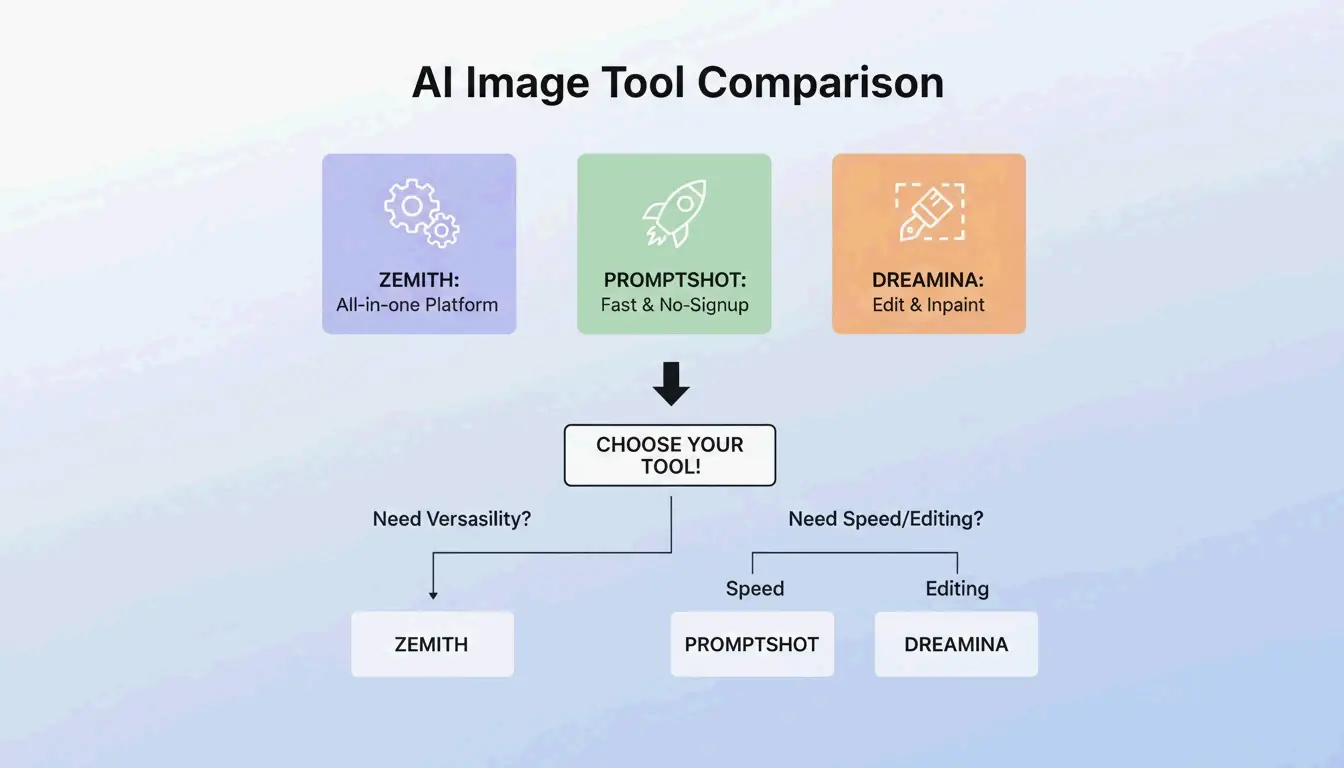
BeConverter vs. Zemith vs. PromptShot: Toolvergelijking (2026)
| Functie | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| Interrogator-modi | CLIP + DeepDanbooru | Multi-model (25+) | Enkele passage |
| Dagelijkse gratis credits | Ja | 100 | Onbeperkt |
| Registratie vereist | Nee | Ja | Nee |
| Het beste voor | Token-isolatie | Alles-in-één workflow | Snelle extracties |
| Uitvoerformaat | Beschrijvend + tags | Modelspezifiek | Prompt-string |
Aanvullende opties die de moeite waard zijn om te vermelden:
- Zemith — Meer dan 30.000 gebruikers per 2026. Volgens Zemith ondersteunt het 25+ modellen inclusief GPT-5.5 met 100 dagelijkse credits.
- PromptShot AI — Geen account nodig. PromptShot AI biedt een proces in 5 stappen, ontworpen voor makers die AI-kunst snel willen “recreëren en verbeteren.”
- Dreamina (GPT Image 2) — Genereer en bewerk in één venster. Volgens Dailyhunt ondersteunt het GPT Image 2-model inpainting en lichtaanpassingen direct na promptgeneratie.
Conclusie
Reverse prompting met BeConverter zet elke referentieafbeelding in seconden om in een gestructureerde, herbruikbare AI-prompt. Upload je afbeelding, extraheer stijltokens met CLIP of DeepDanbooru, isoleer de artistieke attributen, en plak ze in de generator van je keuze. Voor het beste resultaat pas je het promptformaat aan op je doelmodel — abstract voor Midjourney, letterlijk voor FLUX, tag-gebaseerd voor Stable Diffusion — en voeg altijd negatieve prompts toe om de uitvoerkwaliteit te waarborgen.
Veelgestelde Vragen
Kan reverse prompting de exacte originele prompt terugvinden die door een andere maker is gebruikt?
Nee. Het reconstrueert een beschrijvende benadering op basis van visuele analyse. Verschillende VLM-modellen prioriteren verschillende attributen, dus de uitvoer is een hoogwaardige reconstructie — geen verborgen metadata of toetsaanslagherstel.
Werkt afbeelding-naar-prompt-technologie op echte smartphonefoto’s?
Ja. PromptsEra merkt op dat VLM’s real-world attributen kunnen identificeren zoals “golden hour lighting” of specifieke cameralenzen en die texturen kunnen vertalen naar prompts voor artistieke herinterpretatie.
Is het legaal om prompts te gebruiken die uit auteursrechtelijk beschermd kunstwerk zijn geëxtraheerd?
Prompts zijn korte tekststrings en worden doorgaans niet gedekt door auteursrecht. De ethische aanpak is om stijltokens te extraheren ter informatie voor je eigen originele werk. Zoals PromptsEra aangeeft, kan het proberen om een beschermd personage exact te kopiëren juridische problemen opleveren — gebruik deze tools om technieken te leren, niet om te kopiëren.
Geef een reactie