
すべてのモダンなデータベース、分散システム、APIは一意識別子を使用しています——そして2026年、それらを規定する標準は根本的に変わりました。UUID(Universally Unique Identifier、汎用一意識別子) は、中央の調整なしにコンピュータシステム間で情報を識別できる128ビットのラベルです。新しい RFC 9562(2024年5月にRFC 4122を置き換え)の下で状況は変わりました:UUID v4 はランダムIDの定番ですが、UUID v7 は時間順の構造がBツリーインデックスの断片化を防ぐため、データベースの主キーとして推奨される標準になりました。
本ガイドでは全体像を扱います:UUIDの仕組み、いつどのバージョンを使うか、正しい実装方法。
RFC 9562の理解:モダンなUUID標準
UUIDは128ビットの数値で、実質的に一意であることが保証されています——中央機関は不要です。Wikipedia によると、2つのUUIDが衝突する確率はゼロに近く、現実のアプリケーションでは不可能とみなされます。異なるチームが独立してデータにラベルを付け、IDが衝突しないと確信できます。
2024年5月、IETFは RFC 9562 を発表し、古いRFC 4122を引退させました。この更新は、一意 かつ 時間でソート可能なIDを必要とするモダンな分散システムの要求に応えるものでした。3つの新しいバージョンが導入されました:v6、v7、v8。
UUIDの解剖:バージョンとバリアント
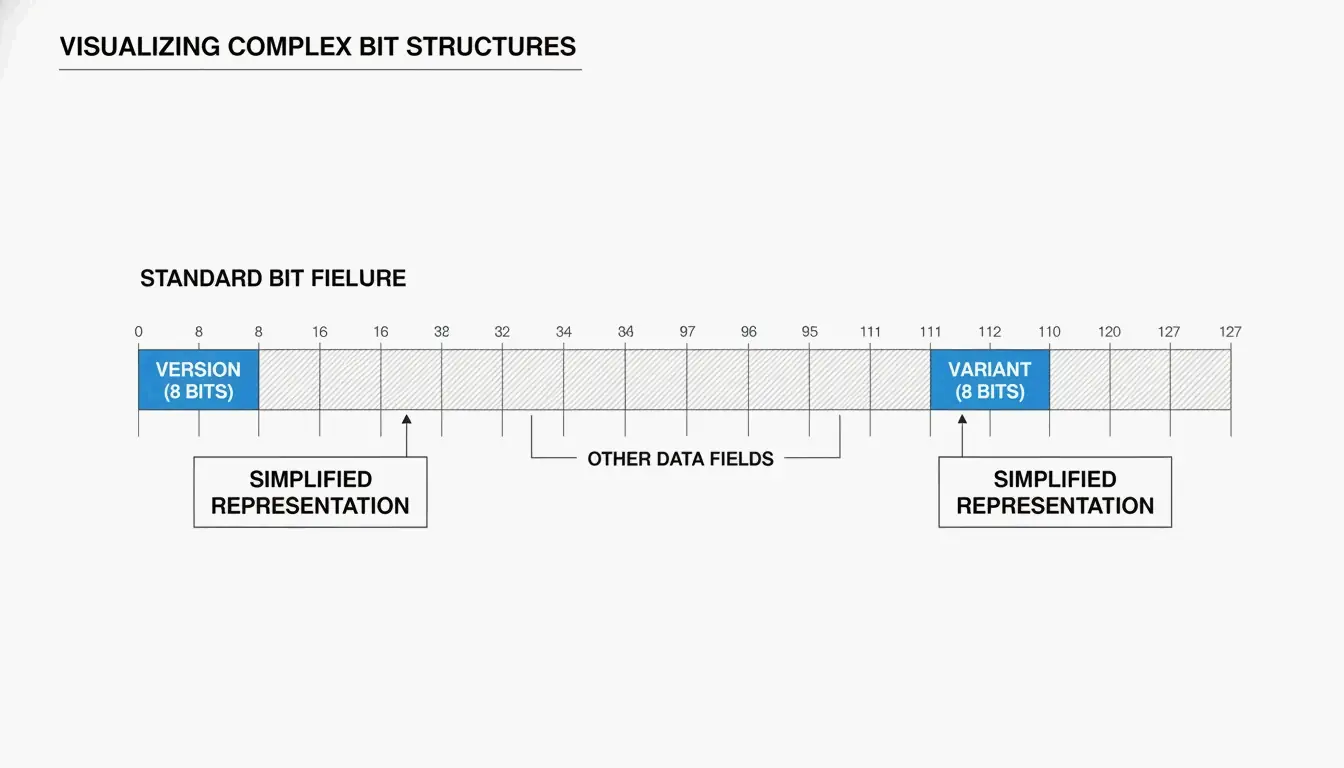
UUIDは通常、32個の16進文字がハイフンで5つのグループに分けられた形(8-4-4-4-12)で見られます:
550e8400-e29b-41d4-a716-446655440000
^
version
2つの重要なフィールドが、UUIDがどう生成されたかを教えてくれます:
| フィールド | 位置 | 教えてくれること |
|---|---|---|
| バージョンビット | 7バイト目の先頭4ビット(3つ目のグループの先頭文字) | どのアルゴリズムが使われたか(例:”4″ = v4、”7″ = v7) |
| バリアントビット | 9バイト目 | UUIDのバリアント——RFC 9562は 10 ビットパターンを使用 |
SnapUtils が説明するように、バリアントビットはモダンなRFC 9562のUUIDを、古いApolloやMicrosoftのフォーマットから区別します。
なぜUUID v7がデータベースの新たなゴールドスタンダードなのか
UUID v4 の最大の欠点は、完全にランダムなことです。Bツリーインデックス の主キーとして使うと、データベースは予測不能な位置に新しい行を挿入しなければなりません。CreateUUID によると、これは 「ページ分割」 を引き起こします——データベースはスペースを空けるためにデータを絶えず再編成しなければならず、書き込みが遅くなりメモリが無駄になります。
UUID v7 は、IDの先頭に 48ビットのUnixエポックタイムスタンプ(ミリ秒精度)を置くことでこれを解決します。これによりIDは単調増加になります——新しいものは常に古いものより大きくなります。データベースはインデックスの末尾に追加するだけで済み、シーケンシャルな整数のパフォーマンスとUUIDのグローバルな一意性を同時に得られます。
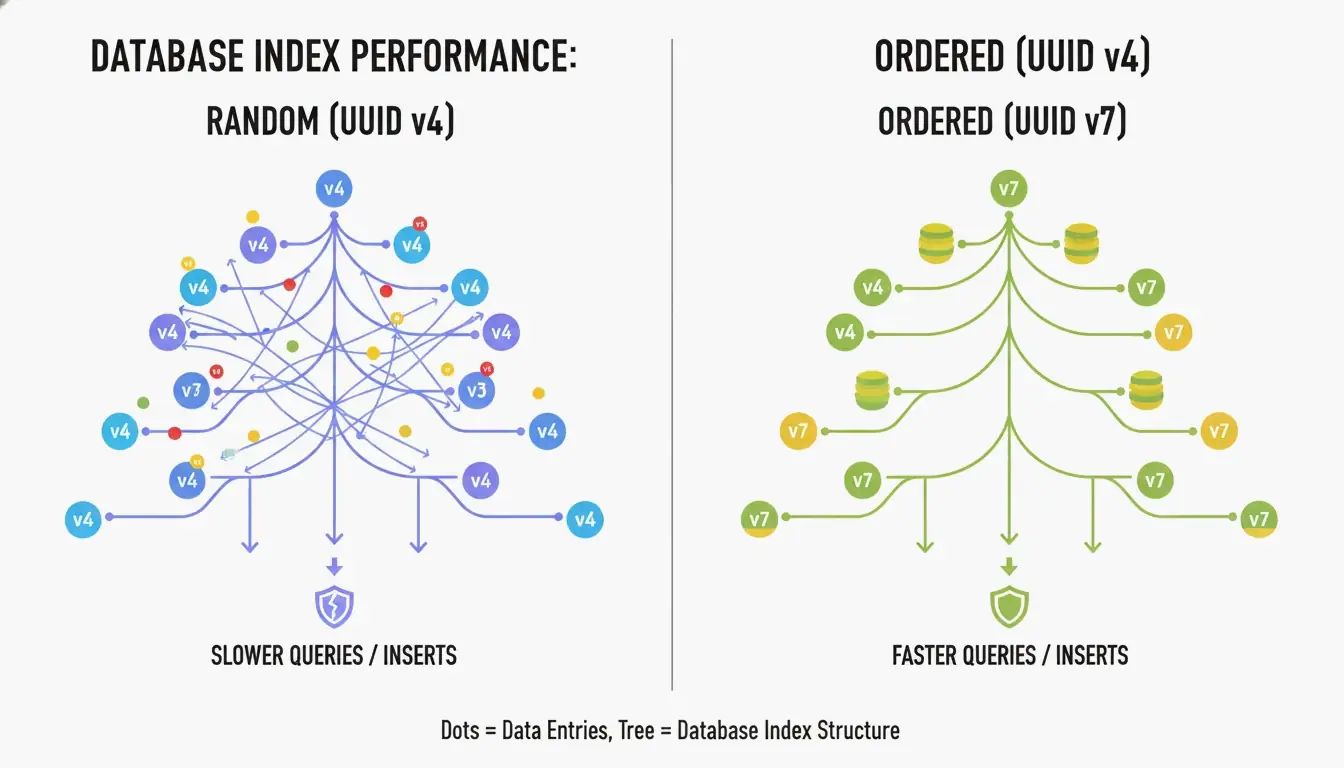
UUID v7が時間とエントロピーをどうバランスさせるか
UUID v7は残り74ビットを CSPRNG(暗号論的に安全な擬似乱数生成器) で埋めます。Wikipedia によると、50%の衝突確率に達するには 1秒間に約10億個のUUIDを85年間 生成し続ける必要があります。現実のアプリケーションにおいて、UUID v7は事実上衝突しません。
保存のベストプラクティス:Binary(16) vs String(36)
UUIDをどう保存するかは、どのバージョンを使うかと同じくらい重要です:
| 保存形式 | サイズ | インデックス性能 | 推奨 |
|---|---|---|---|
| Binary(16) | 16バイト | 高(コンパクト) | ベストプラクティス |
| ネイティブUUID型 | 16バイト | 高(最適化済み) | PostgreSQLに最適 |
| 文字列(Char 36) | 36–72バイト | 低(断片化) | 避ける |
SnapUtils は、文字列ではなく常にネイティブ型を使うことを推奨しています。PostgreSQL では、ネイティブの uuid 型が標準的な文字列ベースのクエリをサポートしながら、データをコンパクトな16バイトのバイナリ形式で保存します。
UUID vs GUID:違いはあるのか?
GUID(Globally Unique Identifier) は、UUID標準のMicrosoftによる実装です。歴史的にはバイト順(エンディアン)に違いがありました——初期のMicrosoft GUIDは最初の3つのフィールドにリトルエンディアンを使用し、標準UUIDはビッグエンディアン(ネットワークバイト順)を使用していました(SnapUtils)。
2026年までに、これは主に命名規約の話です。RFC 9562の下では、両者は同一に動作します。.NETの Guid.NewGuid() はPythonの uuid.uuid4() と完全に互換性があります。Windows/Azureの界隈では「GUID」、Linuxやオープンソースコミュニティでは「UUID」と聞くでしょう。
モダンなUUIDの実装:言語別
| 言語 | UUID v4 | UUID v7 |
|---|---|---|
| Python | 組み込み uuid モジュール |
uuid6 または uuid7 パッケージ |
| JavaScript | crypto.randomUUID() |
uuid npmパッケージ(v10以降) |
| PostgreSQL | gen_random_uuid()(PG 13以降) |
ネイティブ uuidv7()(PG 17以降)または拡張 |
| .NET | Guid.NewGuid() |
コミュニティパッケージ |
| Rust | uuid クレート(v1.7以降) |
v7機能を有効化した uuid クレート |
決定論的ID:UUID v5
同じ入力(URLやユーザー名など)に対して 毎回同じID が必要な場合は、UUID v5 を使います。これは名前空間UUIDと名前文字列をSHA-1でハッシュします——中央データベースを照会できない場合の重複排除に最適です。
UUID v1のプライバシー教訓
UUID v1 はタイムスタンプとコンピュータのMACアドレスを使用します。ハードウェア情報を漏洩するため、ほぼ廃止されました。有名な例:Melissaウイルスの作成者は、感染したWord文書のUUIDに彼固有のMACアドレスが含まれていたため特定されました。
高度なRFC 9562:v6、v8、特殊UUID
RFC 9562は、ニッチな分散システムのニーズに特化したバージョンを追加しました:
| バージョン | 目的 | 使うべき時 |
|---|---|---|
| v6 | 並べ替えたv1タイムスタンプ——ソート可能でv1の精度を維持 | レガシーのv1システムの移行 |
| v8 | カスタム——122ビットを開発者定義データに使用 | 実験的またはベンダー固有のスキーム |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Nullプレースホルダ |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
範囲エンドポイントマーカー |
結論
RFC 9562は、モダンなクラウド時代に向けて一意識別子を更新しました。実用的な指針:
- データベースの主キー → UUID v7 を使い、時間順で断片化のない挿入を実現
- 一般的なランダム性 → UUID v4は引き続き問題なし
- 重複排除 → UUID v5が決定論的IDを提供
- 保存 → 常にBinary(16)かネイティブUUID型を使い、文字列は使わない
アクション項目: データベーススキーマを確認してください。数百万行のテーブルでUUID v4を主キーとして使っている場合、UUID v7への移行は簡単な変更であり、インデックスの断片化を大幅に減らし、クエリを高速化できます。
よくある質問
UUIDとGUIDは同じですか?
機能的には同じです。GUIDはUUID標準のMicrosoftによる実装です。RFC 9562の下では、動作は同一で——.NET、Java、Pythonのアプリケーション間で相互に使用できます。
現実のシナリオで2つのUUIDが衝突することはありますか?
数学的には可能ですが、現実的には不可能です。UUID v4の場合、50%の衝突確率に達するには約 2.71クインティリオン 個のIDを生成する必要があります。Generate-Random.org によると、1秒間に10億個のUUIDを85年間生成しても、単一の衝突が起きる確率は50%にしかなりません。
データベースでUUIDは文字列とバイナリのどちらで保存すべきですか?
常に Binary(16) または ネイティブUUID型(PostgreSQLで利用可能)を優先してください。36文字の文字列は2倍以上のスペースを消費し、インデックスのルックアップと結合を著しく遅くします。SnapUtils は、保存をコンパクトに保つことでRFC 9562の性能メリットが最大化されると指摘しています。
UUID v4の代わりにUUID v5を使うべきなのはいつですか?
決定論的IDが必要な場合、つまり同じ入力が常に同じUUIDを生成し、データベースを照会せずに済ませたい場合は v5 を使います。完全なランダム性が必要で、識別子をその出所へ逆算できないようにしたい場合は v4 を使います。
コメントを残す