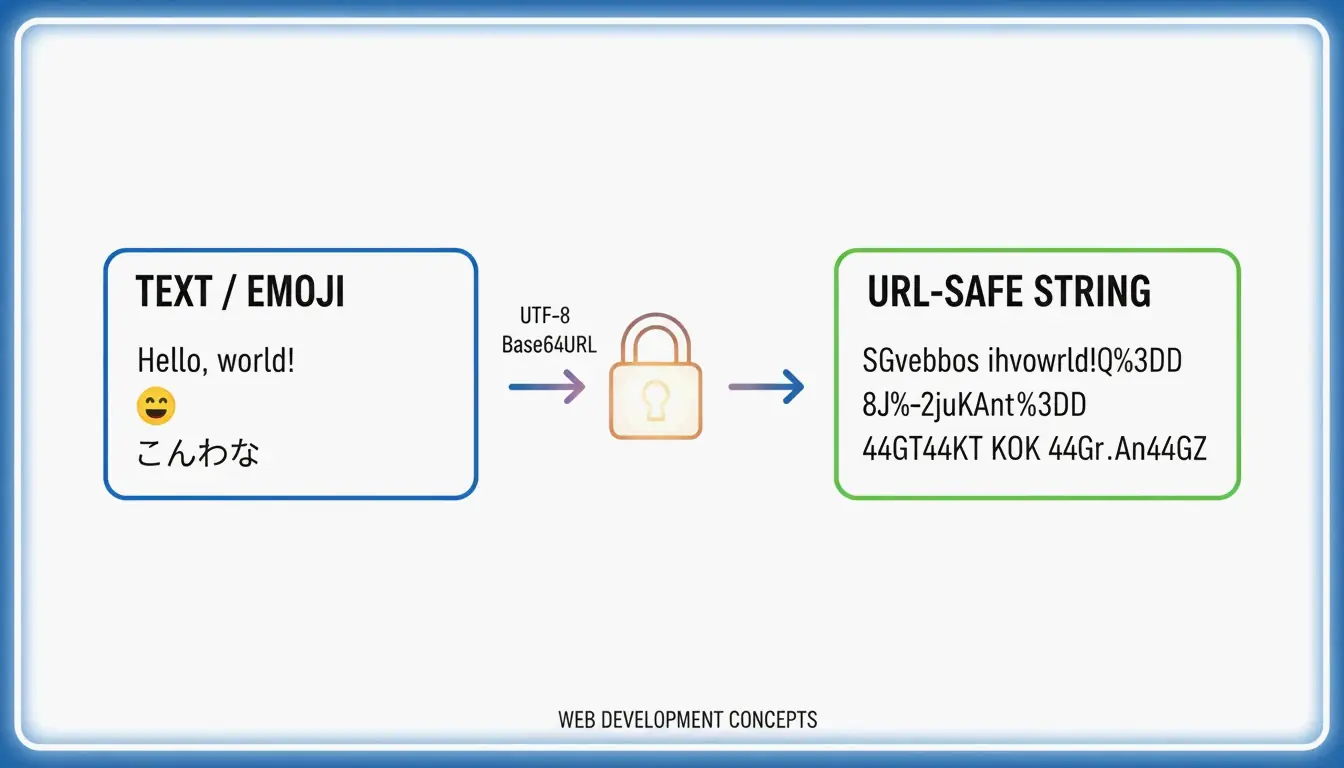
Pour convertir de l’UTF-8 en Base64URL, suivez 4 étapes : (1) encodez le texte en octets UTF-8, (2) appliquez le Base64 standard, (3) remplacez + → - et / → _, (4) supprimez le remplissage = final. Cela produit une chaîne sûre pour les URL conformément à la RFC 4648, utilisée dans les JWT et les en-têtes d’API.
Base64 standard vs Base64URL
| Caractère | Base64 standard | Base64URL | Raison |
|---|---|---|---|
| 62e caractère | + |
- |
+ signifie un espace dans les URL |
| 63e caractère | / |
_ |
/ est un séparateur de chemin dans les URL |
| Remplissage | = requis |
Omis | = devient %3D dans les URL |
| Sûr pour les URL | Non | Oui | Utilisation directe dans les chaînes de requête et les noms de fichiers |
Conformément à la RFC 4648 §5, cet “alphabet sûr pour les URL et les noms de fichiers” assure la compatibilité entre les systèmes.

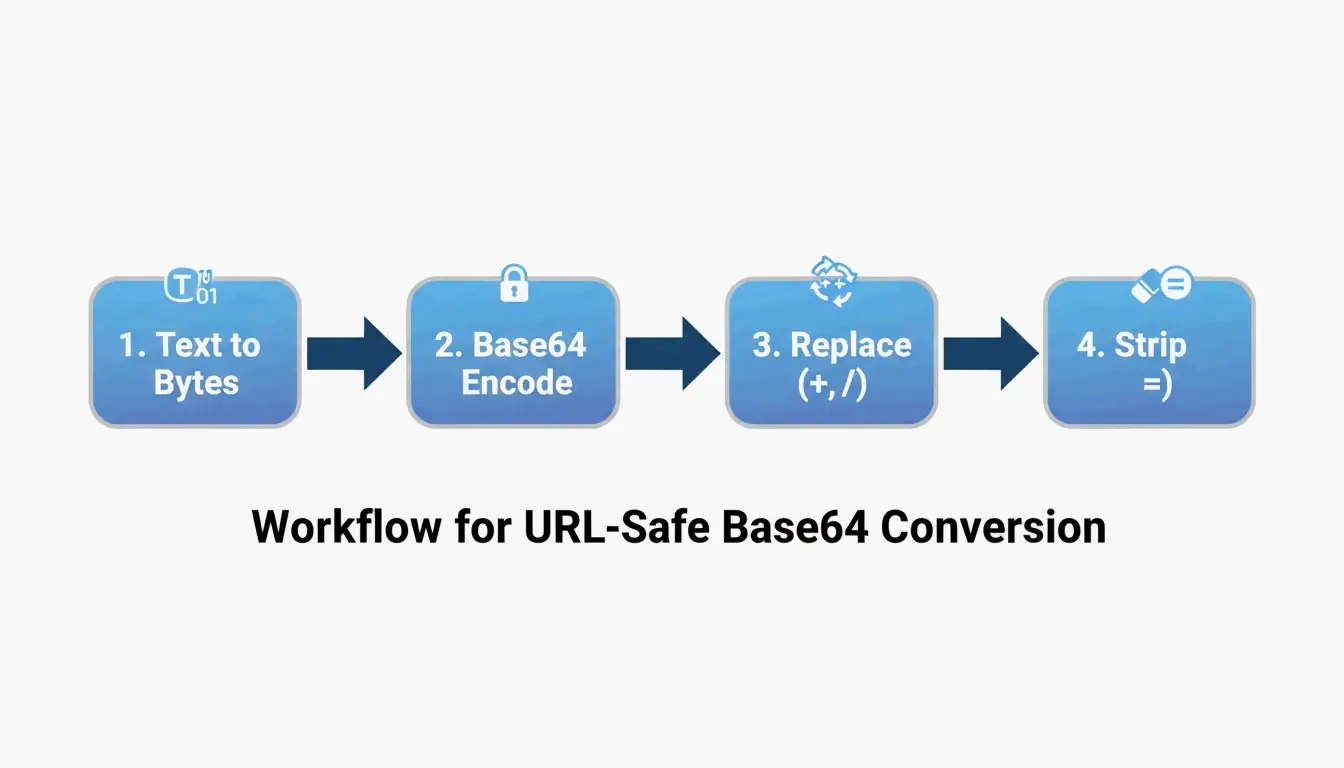
Processus de conversion en 4 étapes
| Étape | Opération | Exemple (“Hello”) |
|---|---|---|
| 1 | Texte UTF-8 → octets | H e l l o → tableau d’octets |
| 2 | Octets → Base64 standard | SGVsbG8= |
| 3 | Remplacement + → -, / → _ |
Aucun changement nécessaire ici |
| 4 | Suppression du remplissage = final |
SGVsbG8 |
L’encodage Base64 augmente la taille des données d’environ ~33 % selon Wikipédia.
Gestion d’Unicode et des emojis
Selon NextUtils, le Base64 est un encodage, pas un chiffrement — il fait transiter des données via des canaux textuels. Pour gérer Unicode et les emojis sans altération (“Mojibake”), utilisez toujours TextEncoder pour convertir d’abord en octets UTF-8.
| Entrée | Sans TextEncoder | Avec TextEncoder |
|---|---|---|
Hello 世界! 🌍 |
Mojibake / TypeError | Base64URL correct |
Exemples de code
JavaScript (navigateur) — compatible Unicode
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3 — bibliothèque standard
Selon AskPython :
import base64
data = "Hello 世界! 🌍"
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js — conversion via Buffer
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
Dépannage : erreurs de remplissage
| Erreur | Cause | Solution |
|---|---|---|
binascii.Error: Incorrect padding |
Remplissage = manquant |
Ajoutez des = jusqu’à ce que la longueur soit un multiple de 4 |
TypeError avec atob() |
Caractères non ASCII | Utilisez d’abord TextEncoder |
| Résultat illisible | Encodage UTF-8 ignoré | Encodez toujours en octets avant le Base64 |
Selon AskPython, calculez le remplissage manquant : padding_needed = (4 - len(data) % 4) % 4, puis ajoutez autant de caractères =.
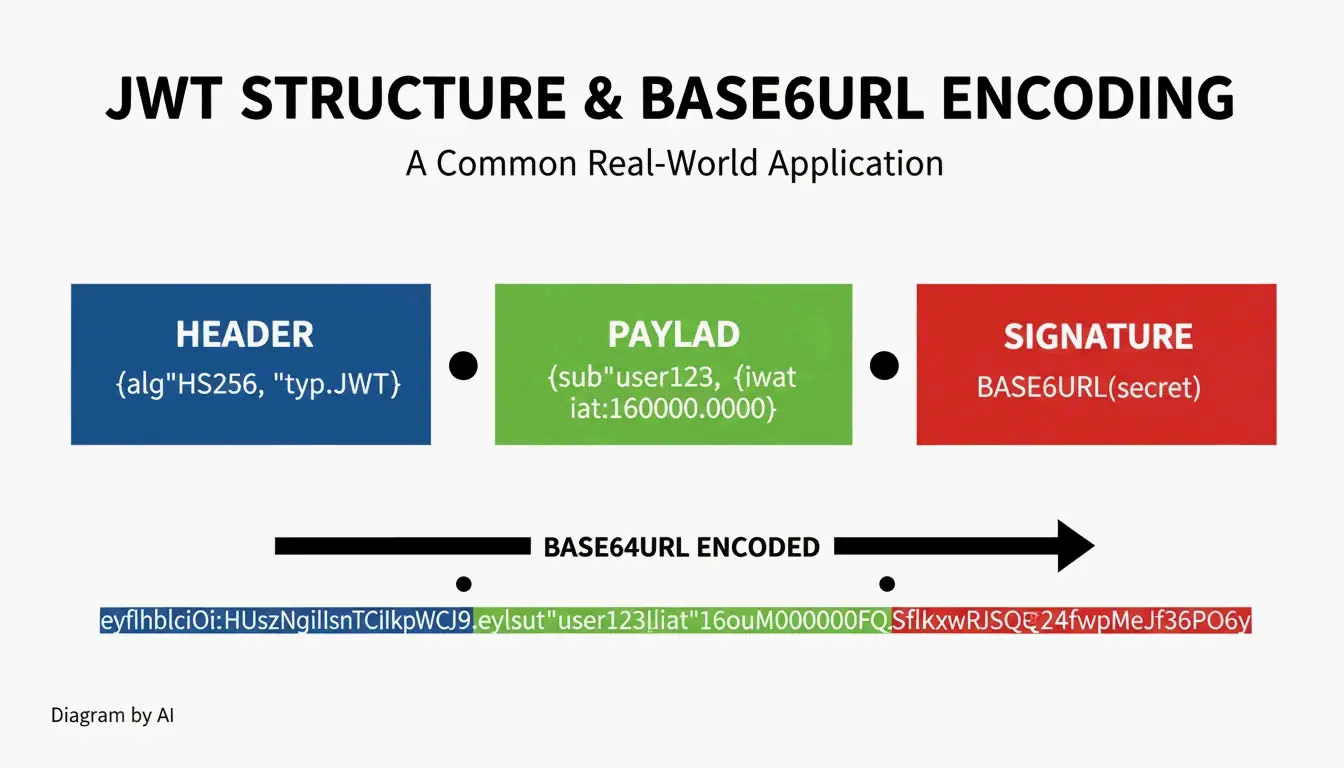
Cas d’utilisation : JWT et Data URI
Structure du JWT (JSON Web Token)
| Partie | Contenu | Encodage |
|---|---|---|
| En-tête | Algorithme + type de jeton | Base64URL |
| Charge utile | Revendications (données utilisateur, expiration) | Base64URL |
| Signature | Signature HMAC ou RSA | Base64URL |
Les JWT commencent souvent par eyJ — l’encodage Base64URL du caractère { (accolade ouvrante JSON).
Base64 vs Base64URL par cas d’utilisation
| Cas d’utilisation | Encodage | Remplissage |
|---|---|---|
| Jeton JWT | Base64URL | Omis |
| Data URI (images intégrées) | Base64 standard | Requis |
| HTTP Basic Auth | Base64 standard | Requis |
| Paramètres de requête URL | Base64URL | Omis |
Conclusion
4 étapes : octets UTF-8 → Base64 → remplacement de +/ par -_ → suppression du remplissage. Utilisez TextEncoder en JavaScript, base64.urlsafe_b64encode() en Python, Buffer dans Node.js. Suivez la RFC 4648 pour la compatibilité inter-systèmes. Le Base64URL est un encodage, pas un chiffrement — utilisez AES-256 ou TLS pour la sécurité.
FAQ
Le Base64URL est-il identique au chiffrement ?
Non. Le Base64URL est un encodage réversible — n’importe qui peut le décoder sans clé. Utilisez AES-256 ou TLS/SSL pour protéger les données sensibles.
Pourquoi le Base64URL échoue-t-il dans un décodeur Base64 standard ?
Les décodeurs standard s’attendent à +, / et au remplissage =. Le Base64URL utilise -, _ et omet le remplissage. Inversez les remplacements de caractères et restaurez le remplissage avant le décodage.
Pourquoi le remplissage est-il omis dans les JWT ?
Le caractère = devient %3D dans les URL, ce qui allonge les chaînes et les rend moins lisibles. La RFC 4648 autorise l’omission car les décodeurs peuvent reconstruire la longueur d’origine sans marqueurs de remplissage.
Laisser un commentaire