Importez une image dans BeConverter, laissez son modele Vision-Language (VLM) decomposer le visuel en tokens de style, puis collez le prompt extrait dans Midjourney, Stable Diffusion ou FLUX. C’est l’integralite du processus permettant de transformer n’importe quel visuel en un prompt IA reproductible, sans aucun travail d’approximation.
Qu’est-ce que le reverse prompting et comment fonctionne BeConverter ?
Le reverse prompting convertit les pixels en texte comprehensible par un modele generatif. Au lieu de rediger un prompt de zero en esperant que le resultat corresponde a une reference, vous partez de l’image finale et extrayez les mots-cles exacts, les conditions d’eclairage et les balises esthetiques qui definissent son apparence.
BeConverter utilise un modele Vision-Language (VLM) pour analyser les proprietes artistiques d’une image. Le modele compare votre photo a ses donnees d’entrainement afin de classifier des attributs tels que le style de rendu (3D contre peinture a l’huile), la configuration d’eclairage (volumetrique contre ambiant) et la composition. Le resultat est un prompt textuel structure que vous pouvez injecter dans n’importe quel generateur d’images.
VLM contre OCR : pourquoi la numerisation classique ne sait pas lire l’art
La reconnaissance optique de caracteres (OCR) lit du texte, des lettres, des chiffres, des recus. Un VLM lit la direction artistique. Comme l’explique PromptsEra, la ou l’OCR voit le mot « STOP » sur un panneau, un VLM detecte la forme octogonale, la peinture rouge ternie, la profondeur de champ et l’angle du soleil, des details essentiels pour la reproduction visuelle.
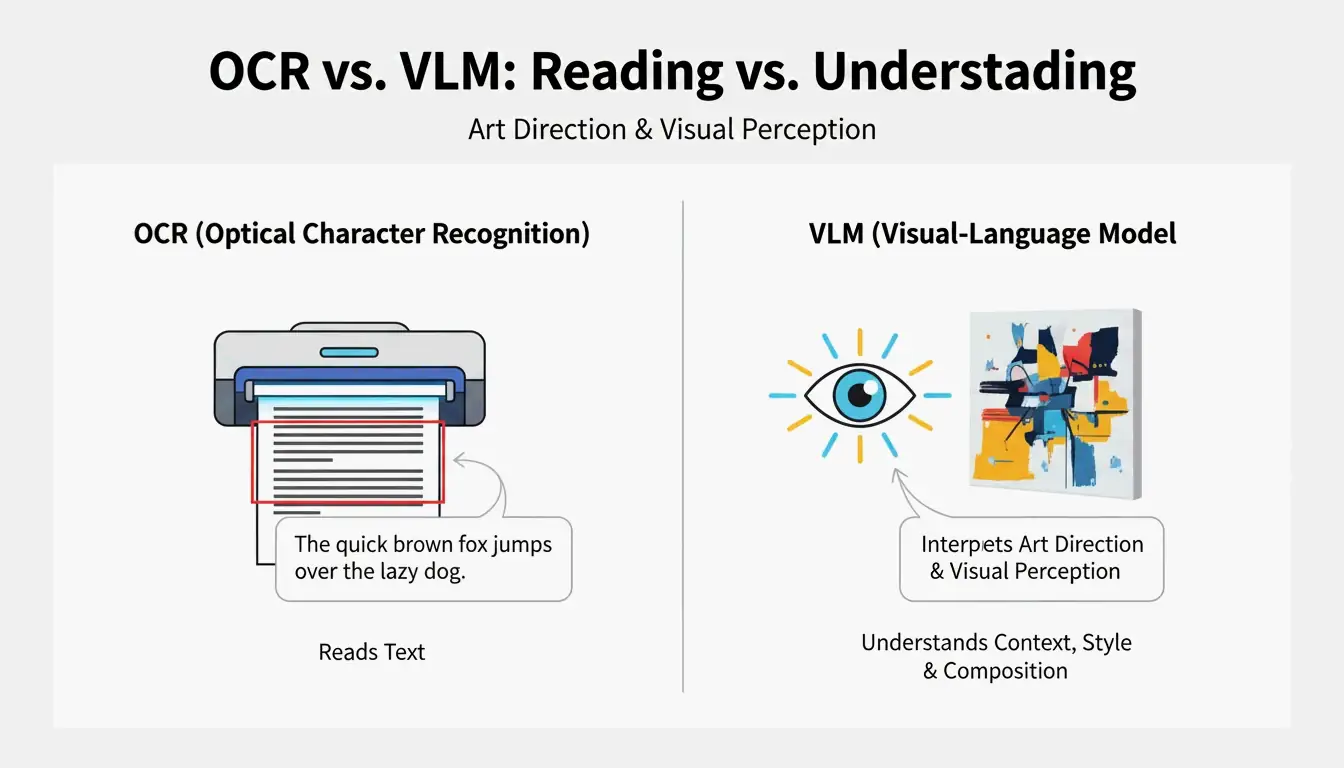
| Capacite | OCR | VLM |
|---|---|---|
| Lit le texte | Oui | Limite |
| Identifie l’eclairage | Non | Oui |
| Detecte le style de composition | Non | Oui |
| Extrait l’etalonnage des couleurs | Non | Oui |
| Produit du texte utilisable en prompt | Non | Oui |
Processus en 4 etapes : comment creer des prompts IA avec BeConverter
Base sur la strategie d’isolation des tokens de style de PromptsEra, suivez cette sequence :
- Importez votre image source — Utilisez un fichier haute resolution. Le VLM a besoin de pixels nets pour detecter des attributs subtils comme « eclairage volumetrique » ou « grain d’objectif 35 mm ».
- Choisissez votre interrogateur — Selectionnez CLIP Interrogator pour des prompts descriptifs et poetiques (ideal pour Midjourney) ou DeepDanbooru pour des balises separees par des virgules (ideal pour Stable Diffusion).
- Isolez les tokens de style — Supprimez les tokens de sujet (par exemple « un chat ») et conservez uniquement les marqueurs de style (par exemple « cyberpunk, eclairage neon en contour, 8k, profondeur de champ cinematographique »).
- Collez dans votre generateur — Copiez les tokens nettoyes dans Midjourney v7, Stable Diffusion ou FLUX et lancez la generation.
Adapter les prompts aux modeles 2026 : FLUX contre Midjourney
Chaque modele interprete les prompts differemment. PromptsEra note que les descriptions abstraites comme « atmosphere melancolique » fonctionnent bien dans Midjourney mais echouent dans FLUX, qui necessite des descriptions spatiales litterales comme « piece sombre avec la pluie frappant la fenetre, lumiere fluorescente au plafond projetant de longues ombres ».
| Style de prompt | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| Abstrait/poetique | Fort | Faible | Moyen |
| Litteral/spatial | Moyen | Fort | Moyen |
| Balises separees par virgules | Moyen | Moyen | Fort |
| Prompts negatifs | Pris en charge (--no) |
Pris en charge | Pris en charge |
La strategie Frankenstein : fusionner les styles de plusieurs images
La technique de retroingenierie la plus efficace combine les tokens de style provenant de sources differentes. Utilisez BeConverter pour extraire l’eclairage de l’image A et le rendu du sujet de l’image B, puis fusionnez-les en un seul prompt.
Controles cles pour une fusion coherente :
- Ratio d’aspect — A definir explicitement (par exemple
--ar 16:9pour Midjourney) car les outils de retroingenierie ne peuvent pas deviner votre canevas souhaite. - Prompts negatifs — Ajoutez toujours des exclusions comme « flou, deformee, basse qualite ». Les outils de retroingenierie detectent uniquement ce qui est present ; ils ne peuvent pas identifier ce qui devrait etre absent.
Comme le conseille Andrew Lo, directeur du Laboratory for Financial Engineering du MIT : « Demandez toujours au LLM : de quoi es-tu incertain ? Quelle information te manque-t-il ? » Appliquez le meme principe : identifiez les lacunes de votre prompt reconstruit avant de generer.
BeConverter contre Zemith contre PromptShot : comparaison des outils (2026)
| Fonctionnalite | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| Modes d’interrogation | CLIP + DeepDanbooru | Multi-modeles (25+) | Passage unique |
| Credits gratuits quotidiens | Oui | 100 | Illimites |
| Inscription requise | Non | Oui | Non |
| Ideal pour | Isolation de tokens | Flux de travail tout-en-un | Extractions rapides |
| Format de sortie | Descriptif + balises | Specifique au modele | Chaine de prompt |
Autres options a noter :
- Zemith — Plus de 30 000 utilisateurs en 2026. Selon Zemith, il prend en charge plus de 25 modeles dont GPT-5.5 avec 100 credits quotidiens.
- PromptShot AI — Aucun compte necessaire. PromptShot AI propose un processus en 5 etapes concu pour les createurs qui souhaitent « recreer et ameliorer » rapidement des oeuvres IA.
- Dreamina (GPT Image 2) — Generez et editez dans une seule fenetre. Selon Dailyhunt, le modele GPT Image 2 prend en charge l’inpainting et les ajustements d’eclairage directement apres la generation du prompt.
Conclusion
Le reverse prompting avec BeConverter convertit n’importe quelle image de reference en un prompt IA structure et reutilisable en quelques secondes. Importez votre image, extrayez les tokens de style avec CLIP ou DeepDanbooru, isolez les attributs artistiques et collez le resultat dans le generateur de votre choix. Pour de meilleurs resultats, adaptez le format du prompt a votre modele cible : abstrait pour Midjourney, litteral pour FLUX, base sur des balises pour Stable Diffusion, et incluez toujours des prompts negatifs pour maintenir la qualite de sortie.
FAQ
Le reverse prompting peut-il retrouver le prompt exact utilise par un autre createur ?
Non. Il reconstruit une approximation descriptive basee sur l’analyse visuelle. Les differents modeles VLM priorisent des attributs differents, le resultat est donc une reconstruction de haute qualite, et non des metadonnees cachees ou la recuperation de frappes.
La technologie image-en-prompt fonctionne-t-elle sur de vraies photographies de smartphone ?
Oui. PromptsEra indique que les VLM peuvent identifier des attributs du monde reel comme « eclairage de l’heure doree » ou des objectifs d’appareil photo specifiques, et traduire ces textures en prompts pour une reinterpretation artistique.
Est-il legal d’utiliser des prompts extraits d’oeuvres protegees par le droit d’auteur ?
Les prompts sont de courtes chaines de texte et ne sont generalement pas couverts par le droit d’auteur. L’approche ethique consiste a extraire les tokens de style pour nourrir votre propre travail original. Comme le souligne PromptsEra, tenter de reproduire exactement un personnage protege peut engendrer des problemes juridiques. Utilisez ces outils pour apprendre des techniques, et non pour copier.
Laisser un commentaire