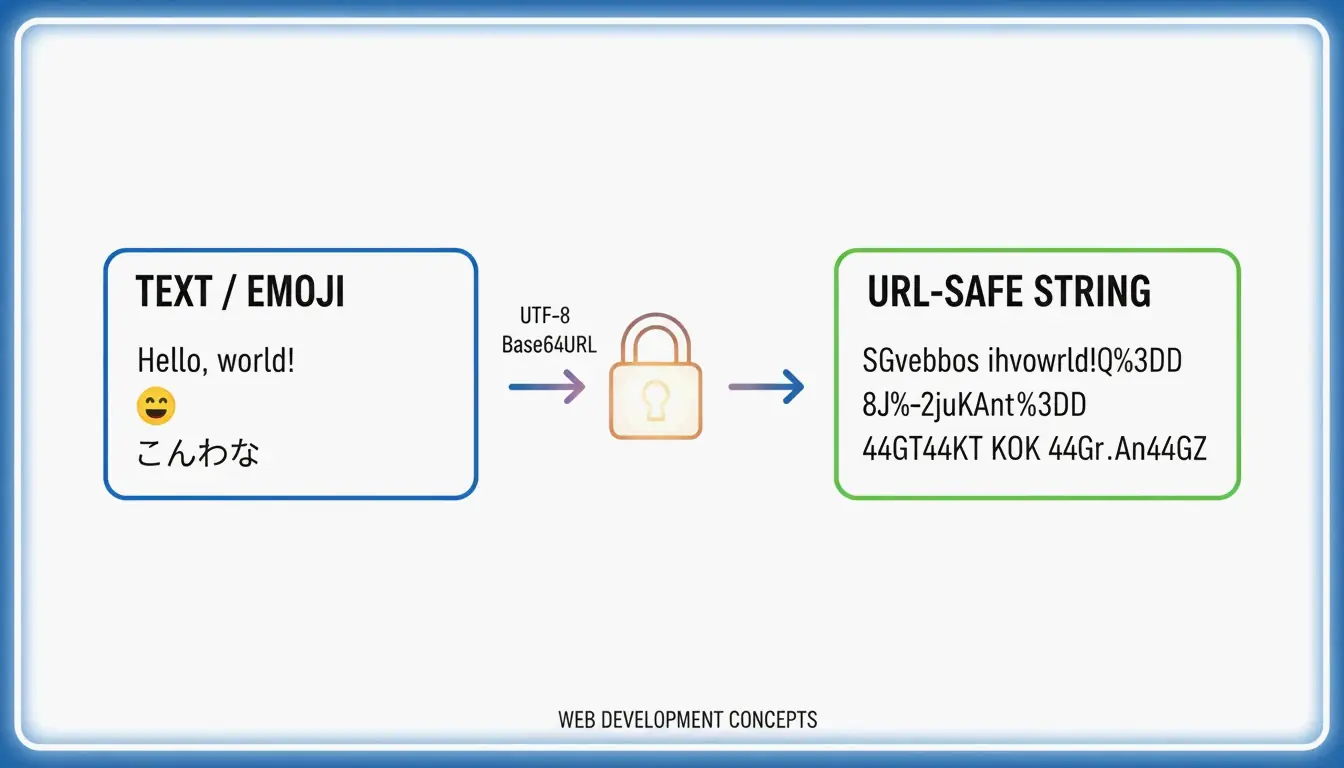
Um UTF-8 in Base64URL umzuwandeln, befolgen Sie 4 Schritte: (1) kodieren Sie den Text in UTF-8-Bytes, (2) wenden Sie Standard-Base64 an, (3) ersetzen Sie + → - und / → _, (4) entfernen Sie das abschließende =-Padding. Dies ergibt eine URL-sichere Zeichenfolge gemäß RFC 4648, die in JWTs und API-Headern verwendet wird.
Standard-Base64 vs. Base64URL
| Zeichen | Standard-Base64 | Base64URL | Grund |
|---|---|---|---|
| 62. Zeichen | + |
- |
+ bedeutet Leerzeichen in URLs |
| 63. Zeichen | / |
_ |
/ ist ein Pfadtrennzeichen in URLs |
| Padding | = erforderlich |
Entfernt | = wird zu %3D in URLs |
| URL-sicher | Nein | Ja | Direkte Verwendung in Query-Strings und Dateinamen |
Gemäß RFC 4648 §5 stellt dieses “URL- und dateinamensichere Alphabet” die systemübergreifende Kompatibilität sicher.

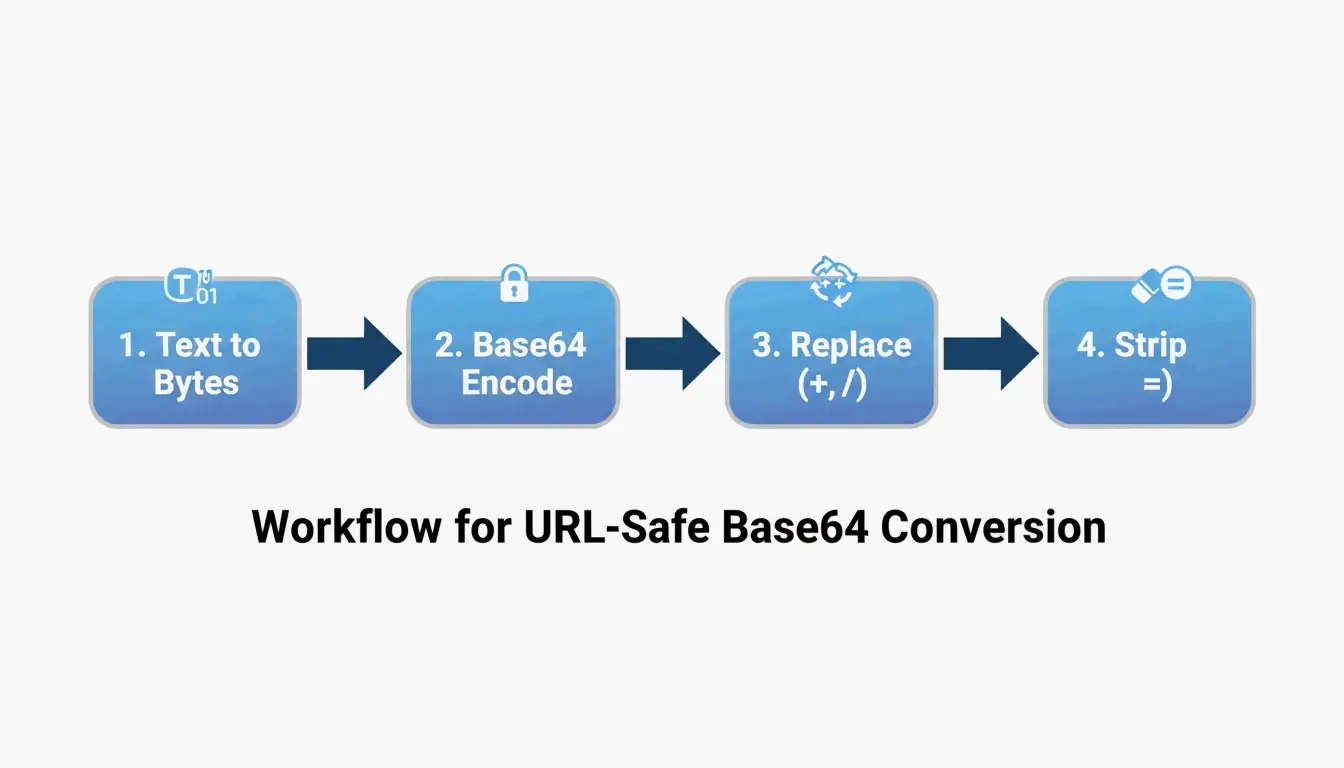
Der 4-Schritte-Umwandlungsprozess
| Schritt | Operation | Beispiel (“Hello”) |
|---|---|---|
| 1 | UTF-8-Text → Bytes | H e l l o → Byte-Array |
| 2 | Bytes → Standard-Base64 | SGVsbG8= |
| 3 | Ersetzung + → -, / → _ |
Hier keine Änderung erforderlich |
| 4 | Entfernung des abschließenden =-Padding |
SGVsbG8 |
Die Base64-Kodierung erhöht die Datengröße um ~33 % laut Wikipedia.
Unicode- und Emoji-Behandlung
Laut NextUtils ist Base64 eine Kodierung, keine Verschlüsselung — es überträgt Daten über rein textbasierte Kanäle. Um Unicode und Emojis ohne Verfälschung (“Mojibake”) zu verarbeiten, verwenden Sie immer TextEncoder, um zunächst in UTF-8-Bytes zu konvertieren.
| Eingabe | Ohne TextEncoder | Mit TextEncoder |
|---|---|---|
Hello 世界! 🌍 |
Mojibake / TypeError | Korrektes Base64URL |
Codebeispiele
JavaScript (Browser) — Unicode-sicher
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3 — Standardbibliothek
Laut AskPython:
import base64
data = "Hello 世界! 🌍"
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js — Buffer-Konvertierung
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
Fehlerbehebung: Padding-Fehler
| Fehler | Ursache | Lösung |
|---|---|---|
binascii.Error: Incorrect padding |
Fehlendes =-Padding |
= hinzufügen, bis die Länge ein Vielfaches von 4 ist |
TypeError bei atob() |
Nicht-ASCII-Zeichen | Zuerst TextEncoder verwenden |
| Unleserliche Ausgabe | UTF-8-Kodierung übersprungen | Immer in Bytes kodieren vor Base64 |
Laut AskPython berechnen Sie das fehlende Padding wie folgt: padding_needed = (4 - len(data) % 4) % 4, und fügen Sie dann die entsprechende Anzahl von =-Zeichen hinzu.
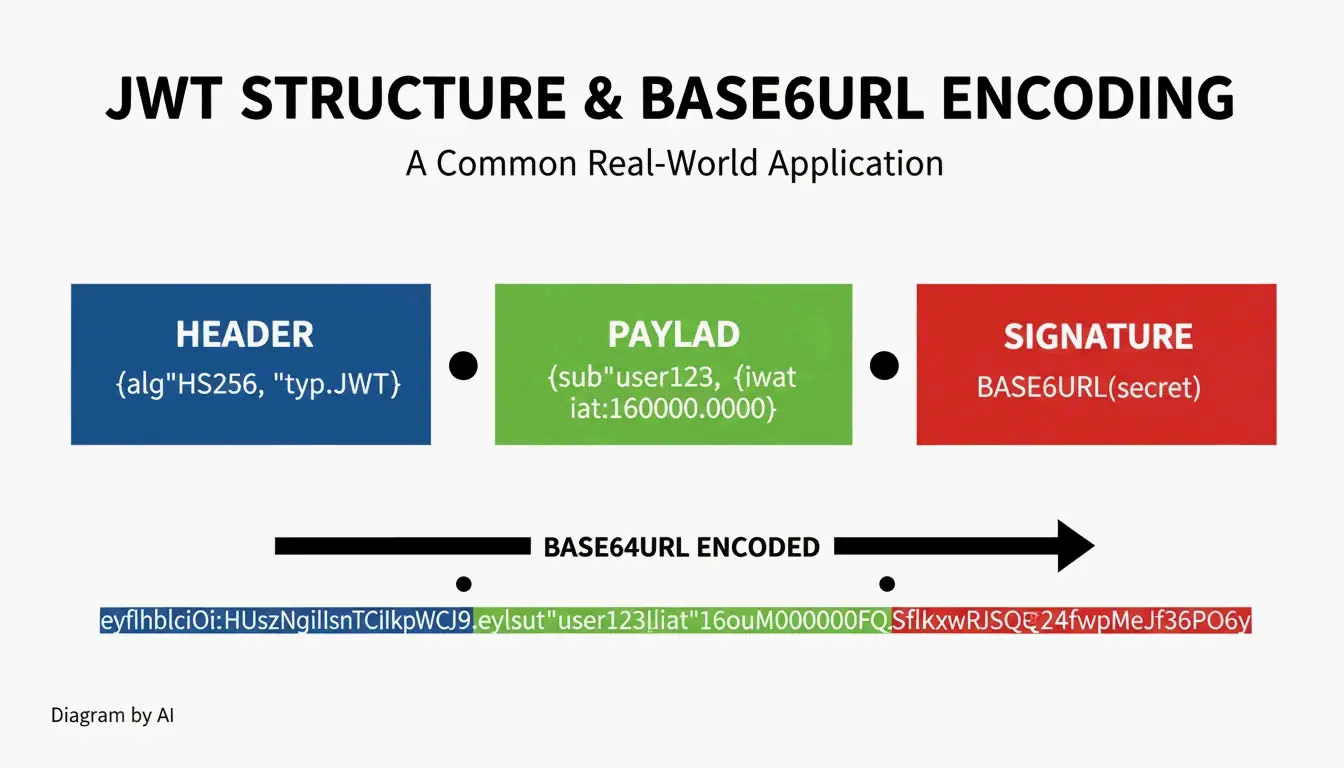
Anwendungsfälle: JWT und Data-URIs
Aufbau eines JWT (JSON Web Token)
| Teil | Inhalt | Kodierung |
|---|---|---|
| Header | Algorithmus + Tokentyp | Base64URL |
| Payload | Claims (Benutzerdaten, Ablaufzeit) | Base64URL |
| Signatur | HMAC- oder RSA-Signatur | Base64URL |
JWTs beginnen oft mit eyJ — der Base64URL-Kodierung von { (öffnende geschweifte Klammer in JSON).
Base64 vs. Base64URL nach Anwendungsfall
| Anwendungsfall | Kodierung | Padding |
|---|---|---|
| JWT-Token | Base64URL | Entfernt |
| Data-URIs (eingebettete Bilder) | Standard-Base64 | Erforderlich |
| HTTP Basic Auth | Standard-Base64 | Erforderlich |
| URL-Query-Parameter | Base64URL | Entfernt |
Fazit
4 Schritte: UTF-8-Bytes → Base64 → +/ durch -_ ersetzen → Padding entfernen. Verwenden Sie TextEncoder in JavaScript, base64.urlsafe_b64encode() in Python, Buffer in Node.js. Befolgen Sie RFC 4648 für systemübergreifende Kompatibilität. Base64URL ist eine Kodierung, keine Verschlüsselung — verwenden Sie AES-256 oder TLS für Sicherheit.
FAQ
Ist Base64URL dasselbe wie Verschlüsselung?
Nein. Base64URL ist eine umkehrbare Kodierung — jeder kann sie ohne Schlüssel dekodieren. Verwenden Sie AES-256 oder TLS/SSL zum Schutz sensibler Daten.
Warum scheitert Base64URL in einem Standard-Base64-Dekoder?
Standard-Dekoder erwarten +, / und =-Padding. Base64URL verwendet -, _ und lässt das Padding weg. Machen Sie die Zeichenersetzungen rückgängig und stellen Sie das Padding vor der Dekodierung wieder her.
Warum wird das Padding in JWTs weggelassen?
Das Zeichen = wird in URLs zu %3D, was die Zeichenfolgen länger und schwerer lesbar macht. RFC 4648 erlaubt das Weglassen, da Dekoder die ursprüngliche Länge ohne Padding-Markierungen rekonstruieren können.
Schreibe einen Kommentar