একটি স্প্রেডশিট, CSV বা JSON ফাইলকে পরিপাটি Markdown টেবিলে রূপান্তর করতে চান? 2026 সালে প্রক্রিয়াটি একদম সহজ — সঠিক টুল নির্বাচন নির্ভর করে আপনি কি দ্রুত একটি একক রূপান্তর করছেন নাকি স্কেলে ডকুমেন্টেশন অটোমেট করছেন তার ওপর।
এই গাইডে প্রতিটি পরিস্থিতির জন্য সেরা টুলগুলো আলোচনা করা হয়েছে: ম্যানুয়াল কাজের জন্য ভিজ্যুয়াল এডিটর, অটোমেশনের জন্য CLI টুল এবং আপনার কোডবেসের সাথে ডকুমেন্টেশন সিঙ্ক রাখার জন্য CI/CD ইন্টিগ্রেশন।
এক নজরে সেরা টুলসমূহ
| টুল | যেখানে সেরা | ধরন | মূল শক্তি |
|---|---|---|---|
| TableGenerator.com | দ্রুত ভিজ্যুয়াল এডিট | Web (ক্লায়েন্ট-সাইড) | গ্রিড-ভিত্তিক এডিটর, অ্যালাইনমেন্ট নিয়ন্ত্রণ |
| AnywayData | অগোছালো JSON ফাইল | Web / লাইব্রেরি | নেস্টেড স্ট্রাকচার ফ্ল্যাট করা, AST পার্সিং |
| MarkItDown (Microsoft) | Excel/Word অটোমেশন | Python CLI | Office ফাইল থেকে হেডার ও টেবিল গ্রিড সংরক্ষণ |
| Pandoc | মাল্টি-ফরম্যাট রূপান্তর | CLI | ডজনখানেক ফরম্যাট সমর্থন, স্কেলে স্থিতিশীল |
| EaseCloud | Excel → GFM | Web | সহজ ব্রাউজার-ভিত্তিক কনভার্টার |
| GoConverter | Excel → GFM | Web | অ্যালাইনমেন্ট অপশনসহ দ্রুত রূপান্তর |
DasRoot (2026) অনুযায়ী, আধুনিক Markdown টুলগুলো মাঝারি আকারের ডেটাসেটের জন্য 15–30 টেবিল প্রতি সেকেন্ড গতিতে কাজ করতে পারে — এবং সেরা টুলগুলো ক্লায়েন্ট-পক্ষীয় প্রক্রিয়াকরণ ব্যবহার করে, অর্থাৎ আপনার ডেটা কখনোই ব্রাউজার ছেড়ে যায় না।
GFM কমপ্লায়েন্স কেন গুরুত্বপূর্ণ
GitHub Flavored Markdown (GFM) হল GitHub, GitLab এবং Discord-এ ব্যবহৃত নির্দিষ্ট ডায়ালেক্ট। মূল Markdown স্পেক আদৌ টেবিল সমর্থন করত না — GFM-ই যুক্ত করেছে সেই পরিচিত “পাইপ-অ্যান্ড-ড্যাশ” সিনট্যাক্স। একটি GFM-কমপ্লায়েন্ট জেনারেটর নিশ্চিত করে যে আপনার টেবিলগুলো বোল্ড হেডার ও অ্যালাইন করা কলামসহ সঠিকভাবে রেন্ডার হবে, কাঁচা টেক্সট হিসেবে দেখাবে না।

Excel এবং CSV থেকে GFM-এ কীভাবে রূপান্তর করবেন
প্রক্রিয়াটি দুটি ধাপে:
- CSV-তে এক্সপোর্ট করুন — আপনার Excel বা Google Sheets ফাইলটি CSV হিসেবে সেভ করুন। এতে ভারী ফরম্যাটিং বাদ দিয়ে ডেটা গ্রিডটি অক্ষত থাকে।
- রূপান্তর করুন — EaseCloud বা GoConverter-এর মতো ব্রাউজার-ভিত্তিক একটি টুল ব্যবহার করে GFM কোড তৈরি করুন।
কলাম অ্যালাইনমেন্ট
GFM সেপারেটর রো (হেডারের নিচের লাইন) দিয়ে অ্যালাইনমেন্ট নিয়ন্ত্রণ করে:
| সিনট্যাক্স | অ্যালাইনমেন্ট |
|---|---|
:--- |
বাম-অ্যালাইনড (ডিফল্ট) |
---: |
ডান-অ্যালাইনড |
:---: |
মাঝখানে-অ্যালাইনড |
পাইপ ক্যারেক্টার এস্কেপ করা
Markdown কলামের প্রান্ত চিহ্নিত করতে | ব্যবহার করে। আপনার ডেটায় যদি কোনো পাইপ থাকে (যেমন কোড স্নিপেট বা ফর্মুলায়), তবে টেবিল ভেঙে যাবে। নিচের উপায়ে এস্কেপ করুন:
- HTML এনটিটি:
| - ব্যাকস্ল্যাশ:
\| - কোড ব্যাকটিক:
`|`
বড় ডেটাসেট হ্যান্ডলিং (100+ rows)
100+ rows ছাড়া ডেটাসেটের জন্য ওয়েব-ভিত্তিক ভিজ্যুয়াল এডিটরগুলো ধীর হয়ে যেতে পারে। আধুনিক কনভার্টারগুলো রেসপন্সিভ থাকার জন্য ক্রমবর্ধমান পার্সিং ব্যবহার করে। AnywayData অনুযায়ী, “জোড়াভিত্তিক সমাবেশজনিত ডেটা লজিক” ব্যবহার করে প্রয়োজনীয় টেস্ট কেস 90–99% পর্যন্ত কমানো সম্ভব, যা জটিল কনফিগারেশন ডকুমেন্ট করার সময় সাহায্য করে।
সত্যিকারের বড় ডেটাসেটের জন্য, একাধিক টেবিলে ভাগ করা বা Markdown ভার্সনের পাশাপাশি একটি ডাউনলোডযোগ্য CSV লিংক দেওয়ার কথা বিবেচনা করুন।
JSON থেকে GFM-এ রূপান্তর: নেস্টেড ডেটা ফ্ল্যাট করা
JSON হায়ারার্কিক্যাল — ডেটা রাশিয়ান পুতুলের মতো নেস্টেড থাকে। কিন্তু Markdown টেবিল হল সমতল 2D গ্রিড। রূপান্তরের জন্য সমতলকরণ লজিক প্রয়োজন:
user.address.city → "User Address City" (একক কলাম হেডার)
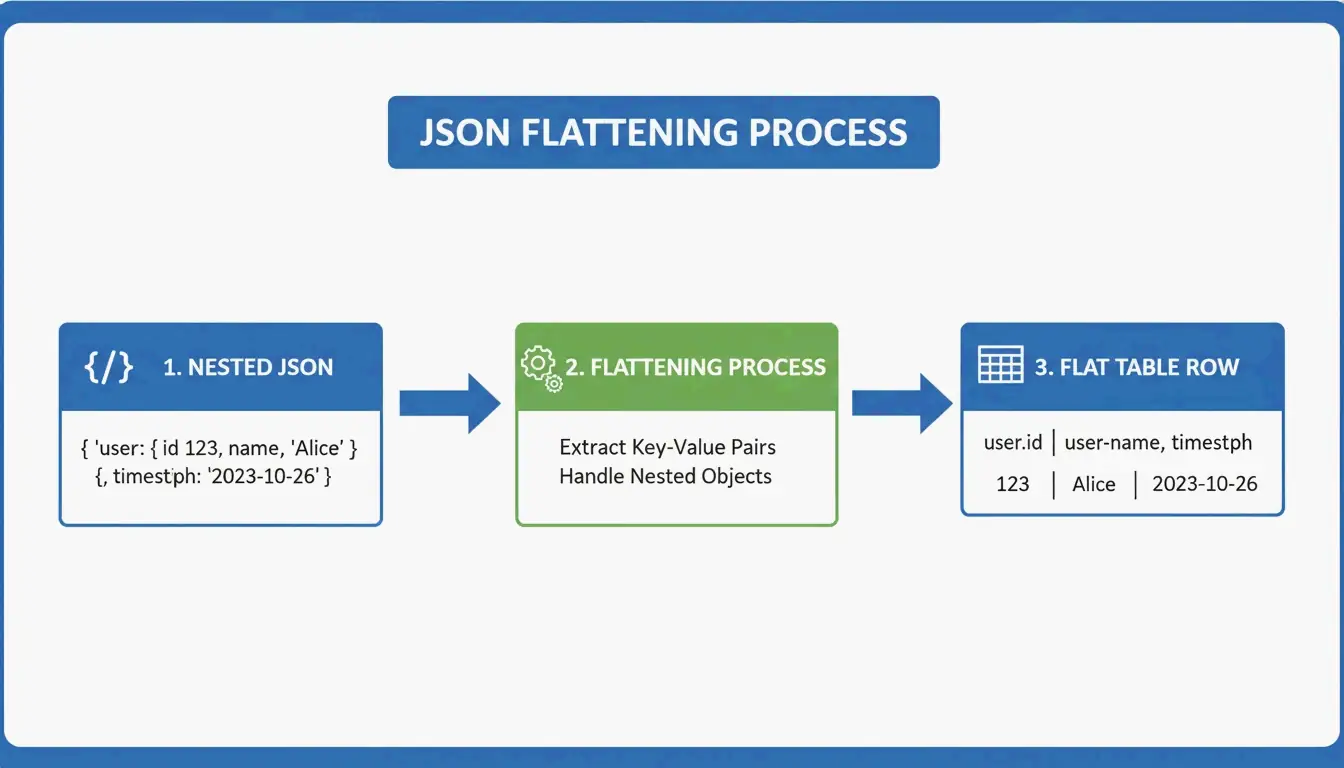
AnywayData-এর Grid Table Editor এখানে দারুণ কাজ করে — এটি আপনাকে JSON ইম্পোর্ট করতে এবং নেস্টেড স্তরগুলো কীভাবে ফ্ল্যাট হবে তা ম্যানুয়ালি নিয়ন্ত্রণ করতে দেয়। রূপান্তরের মান নির্ভর করে টুলটি সাধারণ টেক্সট প্যাটার্ন ম্যাচিংয়ের বদলে AST (Abstract Syntax Tree) কনস্ট্রাকশন ব্যবহার করে কিনা তার ওপর। AST-ভিত্তিক পার্সারগুলো ডেটা স্ট্রাকচারের একটি লজিক্যাল ম্যাপ তৈরি করে, যা গভীর নেস্টিং ও অসঙ্গতিপূর্ণ স্কিমা অনেক বেশি নিখুঁতভাবে হ্যান্ডল করে।
CI/CD দিয়ে অটোমেশন
ইঞ্জিনিয়ারিং টিমের জন্য ম্যানুয়াল রূপান্তর সময়ের অপচয়। আপনার CI/CD pipeline-এ টেবিল জেনারেশন ইন্টিগ্রেট করলে README ফাইলগুলো স্বয়ংক্রিয়ভাবে আপডেট থাকে:
- বিল্ড প্রক্রিয়ার সময় JSON API রেসপন্সকে GFM-এ রূপান্তর করুন
- ডকুমেন্টেশনকে কোড হিসেবে বিবেচনা করুন — ডেটা পরিবর্তনের সাথে সাথে এটি আপডেট হবে
- আপনার রিপোতে পুরোনো বা ভুল তথ্য জমে থাকার সাধারণ সমস্যা প্রতিরোধ করুন
Terraform-docs v0.17.0 (2026)-এর মতো টুলগুলো স্বয়ংক্রিয়ভাবে রিসোর্স টেবিল সরাসরি README ফাইলে ইনজেক্ট করে — যা প্রমাণ করে যে ইনফ্রাস্ট্রাকচার-লেভেল ডকুমেন্টেশনের জন্য CLI টুলগুলো প্রায়শই ওয়েব ইন্টারফেসের চেয়ে এগিয়ে।
MarkItDown বনাম Pandoc: আপনি কোনটি ব্যবহার করবেন?
| ফ্যাক্টর | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| অপ্টিমাইজড | Office ফাইল (Excel, Word) | ইউনিভার্সাল ডকুমেন্ট রূপান্তর |
| Markdown ফ্লেভার | GFM-কেন্দ্রিক | CommonMark, GFM এবং আরও অনেক কিছু |
| সেরা | দ্রুত XLSX → GitHub টেবিল | মাল্টি-ফরম্যাট, হাই-ভলিউম CLI কাজ |
| সর্বশেষ ভার্সন | 2026 | 3.9.0.2 (স্থিতিশীল) |
| গতি | একক Office ফাইলের জন্য দ্রুত | ব্যাচ প্রসেসিংয়ে উন্নত |
| ব্যবহারের সময় | একটি Excel ফাইল রূপান্তর দরকার | ডজনখানেক ফরম্যাটের মধ্যে রূপান্তর দরকার |
বেশিরভাগ ডেভেলপারের জন্য, সাধারণ ক্ষেত্রে (Excel → GitHub টেবিল) MarkItDown দ্রুততর। অনেকগুলো ডকুমেন্ট ফরম্যাট নিয়ে কাজ করলে বা বড় আকারে ব্যাচ রূপান্তর চালালে Pandoc সেরা পছন্দ।
উপসংহার
2026 সালে ডেটাকে GFM টেবিলে রূপান্তর করার বিষয়টি ভলিউম ও ওয়ার্কফ্লোর ওপর নির্ভর করে:
- একক এডিট → ভিজ্যুয়াল নিয়ন্ত্রণের জন্য TableGenerator.com বা AnywayData
- পুনরাবৃত্তিমূলক Office রূপান্তর → আপনার Python ওয়ার্কফ্লোতে ইন্টিগ্রেটেড MarkItDown
- মাল্টি-ফরম্যাট বা হাই-ভলিউম → CLI ব্যাচ প্রসেসিংয়ের জন্য Pandoc
- ইনফ্রাস্ট্রাকচার ডকস → terraform-docs বা কাস্টম স্ক্রিপ্ট দিয়ে CI/CD অটোমেশন
মূল নীতি: আপনার ডেটা আপডেট হলে ডকুমেন্টেশনও আপডেট হওয়া উচিত। রূপান্তর অটোমেট করলে পুরোনো টেবিল জমে থাকে না এবং আপনার প্রজেক্টের ডকুমেন্টেশন নির্ভরযোগ্য থাকে।
প্রশ্নোত্তর
Markdown টেবিল সেলের ভেতরে পাইপ ক্যারেক্টার (|) কীভাবে এস্কেপ করব?
আক্ষরিক পাইপের বদলে HTML এনটিটি | ব্যবহার করুন। বিকল্প হিসেবে, আপনার GFM পার্সার সমর্থন করলে ব্যাকস্ল্যাশ এস্কেপ \| ব্যবহার করুন, অথবা কনটেন্টটিকে কোড ব্যাকটিকে মোড়ান। তিনটি পদ্ধতিই পাইপকে কলাম সেপারেটর হিসেবে ব্যাখ্যা হতে বাধা দেয়।
GFM কি মার্জ করা সেল বা মাল্টি-লাইন কনটেন্ট সমর্থন করে?
না। স্ট্যান্ডার্ড GFM colspan বা rowspan সমর্থন করে না। প্রতিটি সেল স্বাধীন হতে হবে। একটি সেলের ভেতরে মাল্টি-লাইন কনটেন্টের জন্য HTML <br> ট্যাগ ব্যবহার করে লাইন ব্রেক করুন, তাতে ডেটা একই রো-এ থাকবে।
100+ rows ডেটাসেটের জন্য সেরা পদ্ধতি কোনটি?
ওয়েব-ভিত্তিক ভিজ্যুয়াল এডিটর এড়িয়ে যান (ধীর হয়ে যাবে)। এর বদলে MarkItDown বা Pandoc-এর মতো CLI টুল ব্যবহার করুন। ফলস্বরূপ টেবিলটি যদি এক পেজের জন্য অনেক বড় হয়ে যায়, তবে পঠনযোগ্যতা বজায় রাখতে একাধিক টেবিলে ভাগ করুন বা একটি ডাউনলোডযোগ্য CSV ফাইলের লিংক দিন।
মন্তব্য করুন