Нужно превратить электронную таблицу, CSV или JSON в чистую Markdown-таблицу? В 2026 году процесс прост — подходящий инструмент зависит от того, делаете ли вы разовое быстрое преобразование или автоматизируете документацию в масштабе.
Это руководство рассматривает лучшие инструменты для каждого сценария: визуальные редакторы для ручной работы, CLI-инструменты для автоматизации и интеграция с CI/CD для синхронизации документации с кодовой базой.
Лучшие инструменты — обзор
| Инструмент | Для чего лучше всего | Тип | Ключевое преимущество |
|---|---|---|---|
| TableGenerator.com | Быстрые визуальные правки | Веб (на стороне клиента) | Сеточный редактор, управление выравниванием |
| AnywayData | Грязные JSON-файлы | Веб / библиотека | Сведение вложенных структур, AST-разбор |
| MarkItDown (Microsoft) | Автоматизация Excel/Word | Python CLI | Сохраняет заголовки и сетки таблиц из файлов Office |
| Pandoc | Мультиформатная конвертация | CLI | Поддерживает десятки форматов, стабилен в масштабе |
| EaseCloud | Excel → GFM | Веб | Простой браузерный конвертер |
| GoConverter | Excel → GFM | Веб | Быстрое преобразование с настройкой выравнивания |
Согласно DasRoot (2026), современные Markdown-инструменты обрабатывают 15–30 таблиц в секунду для наборов данных среднего размера — а лучшие используют обработку на стороне клиента, что означает, ваши данные никогда не покидают браузер.
Почему соответствие GFM важно
GitHub Flavored Markdown (GFM) — это конкретный диалект, который используют GitHub, GitLab и Discord. Изначальная спецификация Markdown вообще не поддерживала таблицы — GFM добавил привычный синтаксис с «вертикальной чертой и тире». Совместимый с GFM генератор гарантирует, что ваши таблицы корректно отображаются с жирными заголовками и выровненными столбцами, а не выглядят как сырой текст.

Как конвертировать Excel и CSV в GFM
Процесс состоит из двух шагов:
- Экспорт в CSV —— Сохраните файл Excel или Google Sheets как CSV. Это убирает тяжёлое форматирование, сохраняя сетку данных.
- Конвертация —— Используйте браузерный инструмент вроде EaseCloud или GoConverter для генерации GFM-кода.
Выравнивание столбцов
GFM управляет выравниванием через строку-разделитель (строку под заголовком):
| Синтаксис | Выравнивание |
|---|---|
:--- |
По левому краю (по умолчанию) |
---: |
По правому краю |
:---: |
По центру |
Экранирование вертикальной черты
Markdown использует | для обозначения границ столбцов. Если ваши данные содержат вертикальную черту (например, в фрагменте кода или формуле), она сломает таблицу. Экранируйте её:
- HTML-сущность:
| - Обратный слеш:
\| - Обратные кавычки:
|
Обработка больших наборов данных (100+ строк)
Для наборов данных свыше 100 строк веб-визуальные редакторы могут подтормаживать. Современные конвертеры используют инкрементальный разбор, чтобы оставаться отзывчивыми. Согласно AnywayData, использование «попарной комбинаторной логики данных» может сократить необходимые тестовые случаи на 90–99%, что помогает при документировании сложных конфигураций.
Для действительно больших наборов данных рассмотрите разбиение на несколько таблиц или предоставление ссылки на скачиваемый CSV рядом с Markdown-версией.
Конвертация JSON в GFM: сведение вложенных данных
JSON иерархичен — данные вложены как матрёшки. Markdown-таблицы — это плоские 2D-сетки. Преобразование требует логики сведения:
user.address.city → "User Address City" (один заголовок столбца)
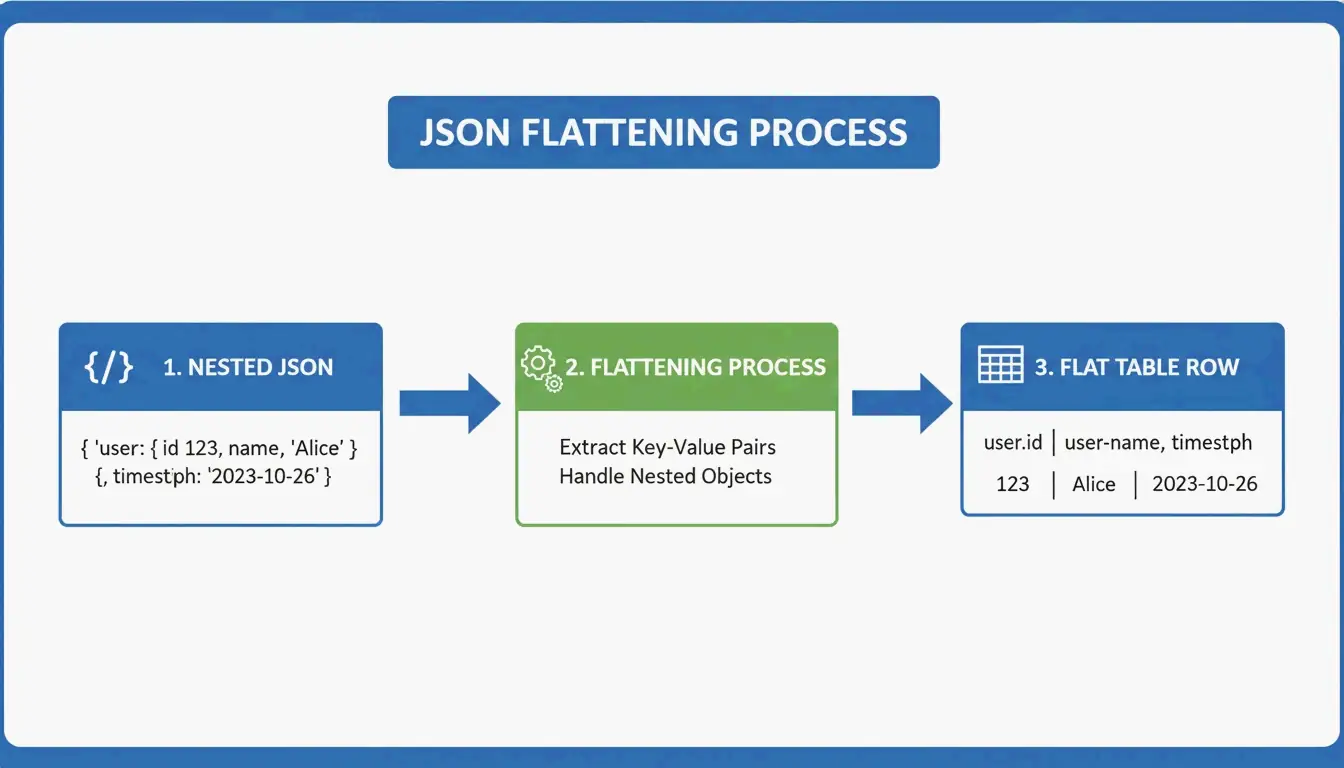
Grid Table Editor от AnywayData здесь великолепен — он позволяет импортировать JSON и вручную управлять тем, как вложенные слои сводятся. Качество преобразования зависит от того, использует ли инструмент построение AST (абстрактного синтаксического дерева), а не простое сопоставление текстовых шаблонов. AST-парсеры строят логическую карту структуры данных, обрабатывая более глубокую вложенность и непоследовательные схемы гораздо точнее.
Автоматизация с CI/CD
Для инженерных команд ручное преобразование — трата времени. Интеграция генерации таблиц в ваш CI/CD-конвейер гарантирует, что файлы README остаются актуальными автоматически:
- Преобразование ответов JSON API в GFM во время сборки
- Отношение к документации как к коду — она обновляется при изменении данных
- Предотвращение распространённой проблемы устаревшей или неверной информации в репозитории
Такие инструменты, как Terraform-docs v0.17.0 (2026), автоматически вставляют таблицы ресурсов прямо в файлы README — доказывая, что CLI-инструменты часто превосходят веб-интерфейсы для инфраструктурной документации.
MarkItDown против Pandoc: что выбрать?
| Фактор | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| Оптимизирован для | Файлов Office (Excel, Word) | Универсальной конвертации документов |
| Варианты Markdown | С фокусом на GFM | CommonMark, GFM и многие другие |
| Лучше всего для | Быстрого XLSX → GitHub-таблицы | Многоформатной, масштабной CLI-работы |
| Последняя версия | 2026 | 3.9.0.2 (стабильная) |
| Скорость | Быстрее для одиночных файлов Office | Лучше для пакетной обработки |
| Когда использовать | Нужно преобразовать один файл Excel | Нужно конвертировать между десятками форматов |
Для большинства разработчиков MarkItDown быстрее в типовом случае (Excel → GitHub-таблица). Pandoc — лучший выбор, когда вы жонглируете множеством форматов документов или выполняете масштабные пакетные преобразования.
Заключение
Преобразование данных в GFM-таблицы в 2026 году сводится к объёму и рабочему процессу:
- Разовые правки → TableGenerator.com или AnywayData для визуального контроля
- Регулярные преобразования Office → MarkItDown, интегрированный в ваш Python-процесс
- Мультиформат или большие объёмы → Pandoc для пакетной CLI-обработки
- Инфраструктурная документация → CI/CD-автоматизация с terraform-docs или пользовательскими скриптами
Ключевой принцип: документация должна обновляться вместе с данными. Автоматизация преобразования предотвращает устаревание таблиц и поддерживает доверие к документации проекта.
Часто задаваемые вопросы
Как экранировать вертикальную черту (|) внутри ячейки Markdown-таблицы?
Используйте HTML-сущность | вместо литеральной вертикальной черты. Либо используйте экранирование обратным слешем \|, если ваш GFM-парсер это поддерживает, либо оберните содержимое в обратные кавычки. Все три метода предотвращают интерпретацию вертикальной черты как разделителя столбцов.
Поддерживает ли GFM объединённые ячейки или многострочное содержимое?
Нет. Стандартный GFM не поддерживает colspan или rowspan. Каждая ячейка должна быть независимой. Для многострочного содержимого внутри ячейки используйте HTML-теги <br> для принудительного переноса строк, сохраняя данные в одной строке.
Какой подход лучше всего для наборов данных свыше 100 строк?
Избегайте веб-визуальных редакторов (они будут тормозить). Вместо этого используйте CLI-инструменты вроде MarkItDown или Pandoc. Если получившаяся таблица слишком велика для одной страницы, разбейте её на несколько таблиц или предоставьте ссылку на скачиваемый CSV-файл, чтобы сохранить читаемость.
Добавить комментарий