
Todos os bancos de dados modernos, sistemas distribuídos e APIs usam identificadores únicos — e em 2026, a norma que os rege mudou fundamentalmente. Um UUID (Universally Unique Identifier, identificador único universal) é um rótulo de 128 bits que pode identificar informações entre sistemas de computadores sem qualquer coordenação central. Sob a nova RFC 9562 (que substituiu a RFC 4122 em maio de 2024), o cenário mudou: UUID v4 continua sendo a escolha para IDs aleatórios, mas UUID v7 é agora o padrão recomendado para chaves primárias de bancos de dados, porque sua estrutura ordenada no tempo evita a fragmentação do índice em árvore B.
Este guia cobre o panorama completo: como os UUIDs funcionam, qual versão usar em cada caso e como implementá-los corretamente.
Compreendendo a RFC 9562: o padrão UUID moderno
Um UUID é um número de 128 bits cuja unicidade é praticamente garantida — sem qualquer autoridade central. Segundo a Wikipédia, a probabilidade de dois UUIDs colidirem é tão próxima de zero que é considerada impossível em aplicações reais. Equipes diferentes podem rotular dados de forma independente, confiantes de que seus IDs não vão colidir.
Em maio de 2024, a IETF publicou a RFC 9562, aposentando a antiga RFC 4122. A atualização respondeu às exigências dos sistemas distribuídos modernos, que precisavam de IDs ao mesmo tempo únicos e ordenáveis por tempo. Três novas versões foram introduzidas: v6, v7 e v8.
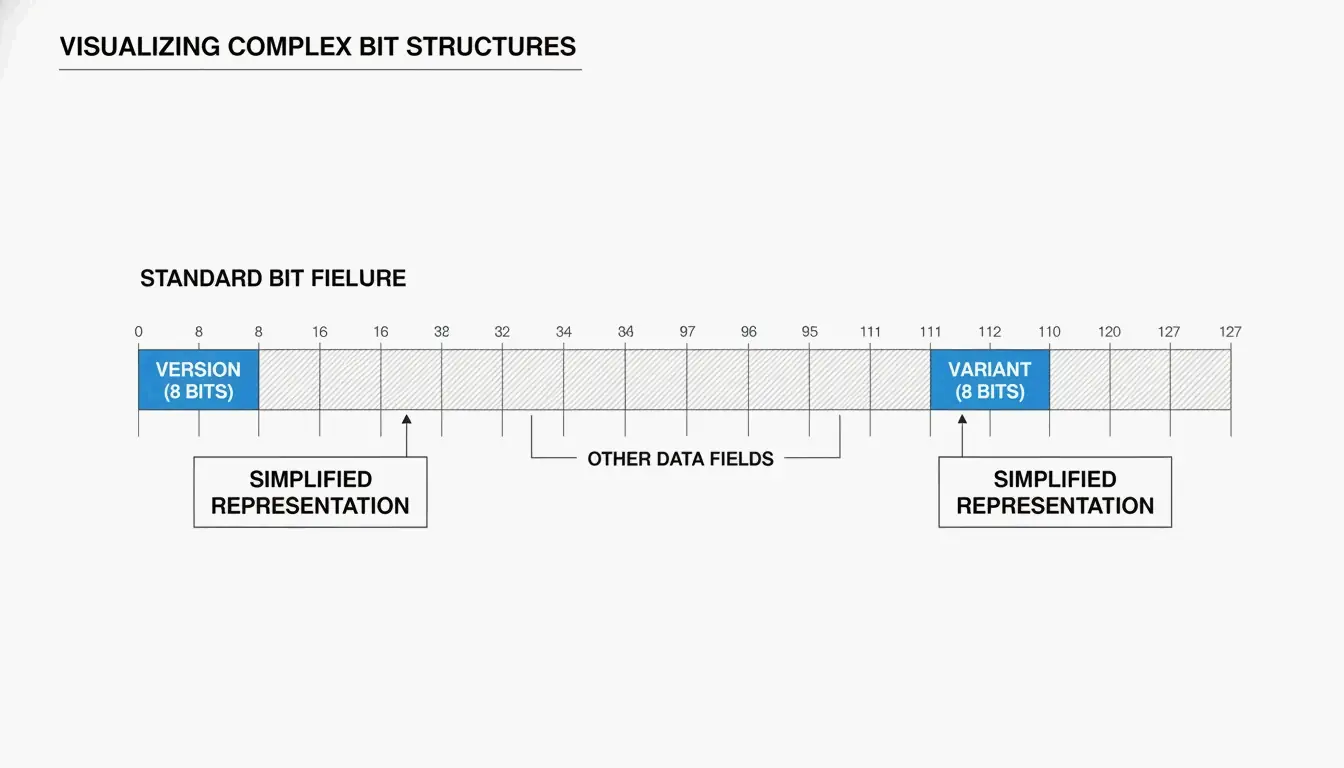
Anatomia de um UUID: versões e variantes
Normalmente você vê um UUID como 32 caracteres hexadecimais divididos em cinco grupos por hifens (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
Dois campos principais dizem como o UUID foi gerado:
| Campo | Localização | O que indica |
|---|---|---|
| Bits de versão | Os primeiros 4 bits do 7.º byte (primeiro caractere do 3.º grupo) | Qual algoritmo foi usado (ex.: “4” = v4, “7” = v7) |
| Bits de variante | 9.º byte | A variante do UUID — a RFC 9562 usa um padrão de bits 10 |
Como a SnapUtils explica, os bits de variante separam os UUIDs modernos da RFC 9562 dos formatos antigos da Apollo ou da Microsoft.
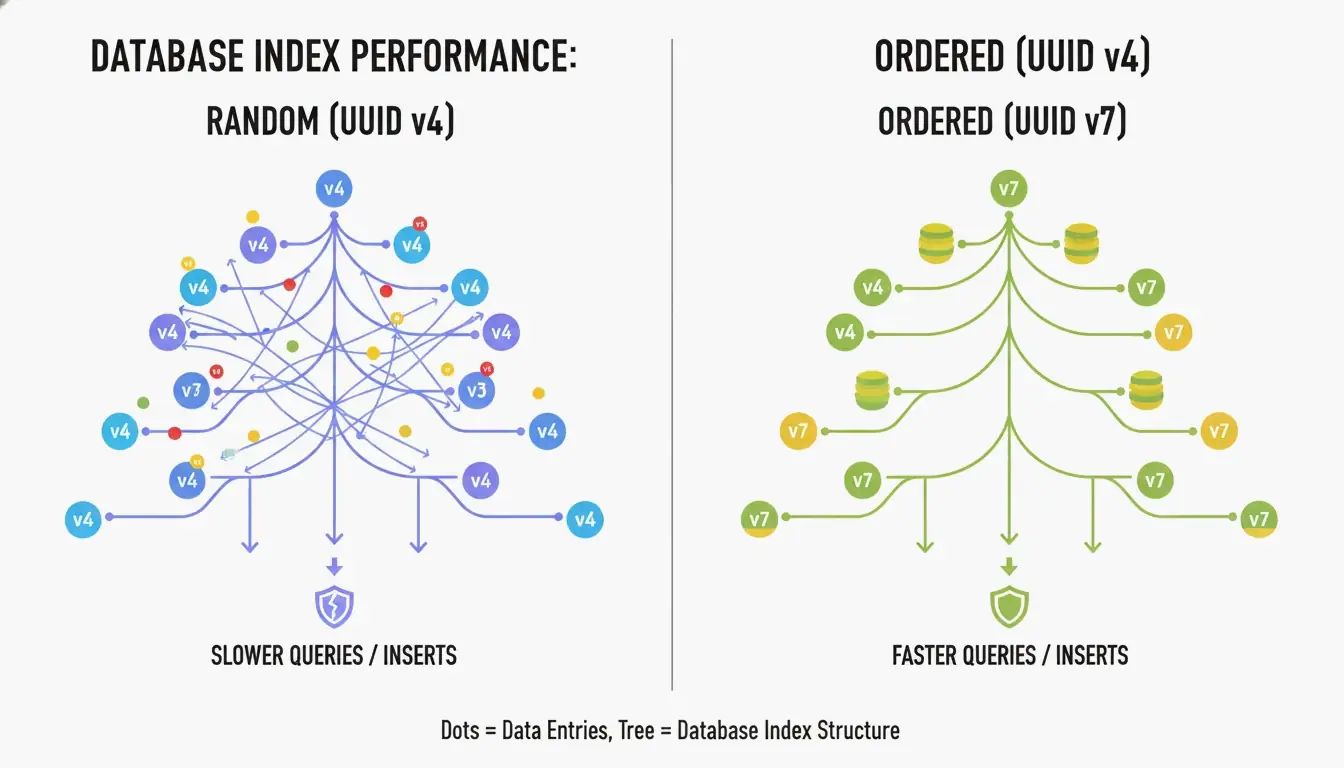
Por que o UUID v7 é o novo padrão-ouro para bancos de dados
A maior desvantagem do UUID v4 é que ele é completamente aleatório. Quando usado como chave primária em um índice de árvore B, o banco de dados precisa inserir novas linhas em posições imprevisíveis. Segundo a CreateUUID, isso causa “divisões de página” (page splits) — o banco de dados precisa reorganizar constantemente os dados para abrir espaço, levando a gravações mais lentas e desperdício de memória.
O UUID v7 resolve isso colocando um carimbo de data/hora Unix Epoch de 48 bits (precisão de milissegundos) no início do ID. Isso torna os IDs monotonicamente crescentes — os novos são sempre maiores que os antigos. O banco de dados pode simplesmente anexar ao final do índice, dando o desempenho de um inteiro sequencial com a unicidade global de um UUID.
Como o UUID v7 equilibra tempo e entropia
O UUID v7 preenche os 74 bits restantes com um CSPRNG (gerador de números pseudoaleatórios criptograficamente seguro). Segundo a Wikipédia, você precisaria gerar cerca de 1 bilhão de UUIDs por segundo durante 85 anos para atingir uma probabilidade de colisão de 50 %. Para qualquer aplicação real, o UUID v7 é efetivamente à prova de colisões.
Melhores práticas de armazenamento: Binary(16) vs. String(36)
Como você armazena os UUIDs importa tanto quanto a versão escolhida:
| Formato de armazenamento | Espaço | Desempenho do índice | Recomendação |
|---|---|---|---|
| Binary(16) | 16 bytes | Alto (compacto) | Melhor prática |
| Tipo UUID nativo | 16 bytes | Alto (otimizado) | Ideal para PostgreSQL |
| String (Char 36) | 36–72 bytes | Baixo (fragmentado) | Evitar |
A SnapUtils recomenda usar sempre tipos nativos em vez de strings. No PostgreSQL, o tipo nativo uuid armazena dados em um formato binário compacto de 16 bytes e ainda assim oferece suporte a consultas padrão baseadas em string.
UUID vs. GUID: há diferença?
Um GUID (Globally Unique Identifier, identificador único global) é a implementação da Microsoft do padrão UUID. Historicamente, havia uma diferença na ordenação de bytes (endianness) — os primeiros GUIDs da Microsoft usavam little-endian para os três primeiros campos, enquanto os UUIDs padrão usavam big-endian (ordem de bytes de rede) (SnapUtils).
Em 2026, isso é sobretudo uma convenção de nomenclatura. Sob a RFC 9562, eles funcionam de forma idêntica. Um Guid.NewGuid() no .NET é totalmente compatível com um uuid.uuid4() no Python. Você ouvirá “GUID” em círculos de Windows/Azure e “UUID” nas comunidades Linux e de código aberto.
Implementando UUIDs modernos: linguagem por linguagem
| Linguagem | UUID v4 | UUID v7 |
|---|---|---|
| Python | Módulo uuid integrado |
Pacote uuid6 ou uuid7 |
| JavaScript | crypto.randomUUID() |
Pacote npm uuid (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
uuidv7() nativo (PG 17+) ou extensões |
| .NET | Guid.NewGuid() |
Pacotes da comunidade |
| Rust | crate uuid (v1.7+) |
crate uuid com a feature v7 |
IDs determinísticos: UUID v5
Se você precisa do mesmo ID todas as vezes para uma determinada entrada (como uma URL ou nome de usuário), use UUID v5. Ele faz o hash de um UUID de namespace e de uma string de nome com SHA-1 — perfeito para desduplicação quando você não pode consultar um banco de dados central.
A lição de privacidade do UUID v1
O UUID v1 usa um carimbo de data/hora e o endereço MAC do computador. Ele foi amplamente abandonado porque vaza informações de hardware. Um exemplo famoso: o criador do vírus Melissa foi pego porque os UUIDs nos documentos do Word infectados continham seu endereço MAC específico.
RFC 9562 avançada: v6, v8 e UUIDs especiais
A RFC 9562 adicionou versões especializadas para necessidades de nicho de sistemas distribuídos:
| Versão | Finalidade | Quando usar |
|---|---|---|
| v6 | Carimbo de data/hora v1 reordenado — ordenável mantendo a precisão do v1 | Migração de sistemas v1 legados |
| v8 | Personalizado — 122 bits para dados definidos pelo desenvolvedor | Esquemas experimentais ou específicos de fornecedor |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Espaço reservado nulo |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
Marcador de extremidade de intervalo |
Conclusão
A RFC 9562 atualizou os identificadores únicos para a era moderna da nuvem. As orientações práticas:
- Chaves primárias de banco de dados → Use UUID v7 para inserções ordenadas no tempo e sem fragmentação
- Aleatoriedade geral → O UUID v4 continua perfeitamente adequado
- Desduplicação → O UUID v5 fornece IDs determinísticos
- Armazenamento → Use sempre Binary(16) ou tipos UUID nativos, nunca strings
Ação: Revise seus esquemas de banco de dados. Se você usa UUID v4 como chave primária em tabelas com milhões de linhas, migrar para UUID v7 é uma alteração simples que pode reduzir significativamente a fragmentação do índice e acelerar as consultas.
Perguntas frequentes
Um UUID é o mesmo que um GUID?
Funcionalmente, sim. Um GUID é a implementação da Microsoft do padrão UUID. Sob a RFC 9562, eles são idênticos em comportamento — você pode usá-los de forma intercambiável entre aplicações .NET, Java e Python.
Dois UUIDs podem colidir em um cenário real?
Matematicamente possível, praticamente impossível. Para o UUID v4, você precisaria gerar aproximadamente 2,71 quintilhões de IDs para atingir uma probabilidade de colisão de 50 %. Segundo o Generate-Random.org, gerar 1 bilhão de UUIDs por segundo durante 85 anos dá apenas 50 % de chance de uma única colisão.
Devo armazenar UUIDs como strings ou binário no banco de dados?
Sempre prefira Binary(16) ou o tipo UUID nativo (disponível no PostgreSQL). Uma string de 36 caracteres consome mais que o dobro do espaço e desacelera significativamente as buscas e junções de índice.A SnapUtils observa que os benefícios de desempenho da RFC 9562 são maximizados quando o armazenamento se mantém compacto.
Quando devo usar UUID v5 em vez de UUID v4?
Use v5 quando precisar de IDs determinísticos — a mesma entrada sempre produz o mesmo UUID, sem consultar um banco de dados. Use v4 quando precisa de aleatoriedade completa e quer garantir que o identificador não possa ser engenharia reversa até sua origem.
Deixe um comentário