
हर आधुनिक डेटाबेस, वितरित प्रणाली और API विशिष्ट पहचानकर्ताओं (unique identifiers) का उपयोग करता है — और 2026 में, उन्हें नियंत्रित करने वाला मानक मौलिक रूप से बदल गया है। UUID (Universally Unique Identifier, सार्वभौम विशिष्ट पहचानकर्ता) एक 128-बिट लेबल है जो बिना किसी केंद्रीय समन्वय के कंप्यूटर सिस्टम के बीच जानकारी की पहचान कर सकता है। नए RFC 9562 (जिसने मई 2024 में RFC 4122 की जगह ली) के तहत, परिदृश्य बदल गया है: UUID v4 अभी भी यादृच्छिक IDs के लिए पसंदीदा है, लेकिन UUID v7 अब डेटाबेस प्राथमिक कुंजियों के लिए अनुशंसित मानक है, क्योंकि इसका समय-क्रमबद्ध ढांचा B-ट्री इंडेक्स विखंडन को रोकता है।
यह गाइड पूरी तस्वीर कवर करता है: UUID कैसे काम करते हैं, कौन सा संस्करण कब उपयोग करें, और उन्हें सही ढंग से कैसे लागू करें।
RFC 9562 को समझना: आधुनिक UUID मानक
UUID एक 128-बिट संख्या है जिसकी विशिष्टता व्यावहारिक रूप से गारंटीशुदा है — किसी केंद्रीय प्राधिकरण की आवश्यकता नहीं। विकिपीडिया के अनुसार, दो UUID के टकराने की संभावना शून्य के इतने करीब है कि वास्तविक अनुप्रयोगों के लिए असंभव मानी जाती है। अलग-अलग टीमें स्वतंत्र रूप से डेटा को लेबल कर सकती हैं, इस विश्वास के साथ कि उनके IDs नहीं टकराएंगे।
मई 2024 में, IETF ने RFC 9562 प्रकाशित किया, पुराने RFC 4122 को सेवानिवृत्त कर दिया। यह अपडेट आधुनिक वितरित प्रणालियों की मांगों का उत्तर था, जिन्हें ऐसे IDs चाहिए थे जो विशिष्ट भी हों और समय के अनुसार क्रमबद्ध भी। तीन नए संस्करण पेश किए गए: v6, v7, और v8।
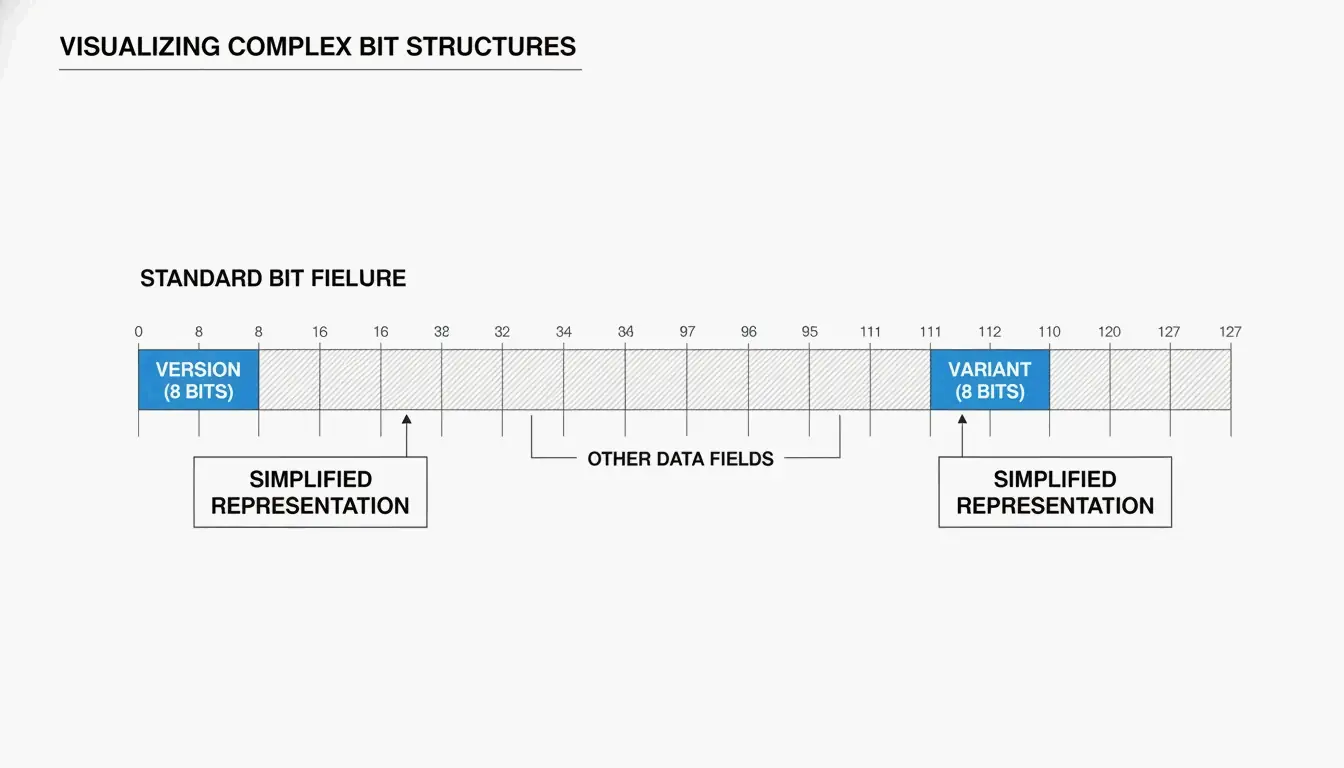
UUID की संरचना: संस्करण और वैरिएंट
आप आमतौर पर UUID को 32 हेक्साडेसिमल अक्षरों के रूप में देखते हैं जो हाइफ़न द्वारा पाँच समूहों में विभाजित होते हैं (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
दो प्रमुख फ़ील्ड आपको बताते हैं कि UUID कैसे उत्पन्न किया गया था:
| फ़ील्ड | स्थान | यह क्या बताता है |
|---|---|---|
| संस्करण बिट्स | 7वें बाइट के पहले 4 बिट्स (तीसरे समूह का पहला अक्षर) | कौन सा एल्गोरिदम उपयोग हुआ (जैसे “4” = v4, “7” = v7) |
| वैरिएंट बिट्स | 9वां बाइट | UUID वैरिएंट — RFC 9562 एक 10 बिट पैटर्न का उपयोग करता है |
जैसा SnapUtils समझाता है, वैरिएंट बिट्स आधुनिक RFC 9562 UUID को पुराने Apollo या Microsoft प्रारूपों से अलग करते हैं।
UUID v7 डेटाबेस का नया स्वर्ण मानक क्यों है
UUID v4 का सबसे बड़ा नुकसान यह है कि यह पूरी तरह से यादृच्छिक है। जब B-ट्री इंडेक्स में प्राथमिक कुंजी के रूप में उपयोग किया जाता है, तो डेटाबेस को अप्रत्याशित स्थितियों में नई पंक्तियाँ डालनी पड़ती हैं। CreateUUID के अनुसार, इससे “पेज विभाजन” (page splits) होते हैं — डेटाबेस को जगह बनाने के लिए लगातार डेटा पुनर्गठित करना पड़ता है, जिससे लेखन धीमा होता है और मेमोरी बर्बाद होती है।
UUID v7 इसे ID की शुरुआत में एक 48-बिट Unix Epoch टाइमस्टैम्प (मिलीसेकंड परिशुद्धता) रखकर हल करता है। इससे IDs एकरस रूप से बढ़ते हैं — नए हमेशा पुराने से बड़े होते हैं। डेटाबेस बस इंडेक्स के अंत में जोड़ सकता है, जिससे आपको अनुक्रमिक पूर्णांक का प्रदर्शन UUID की वैश्विक विशिष्टता के साथ मिलता है।
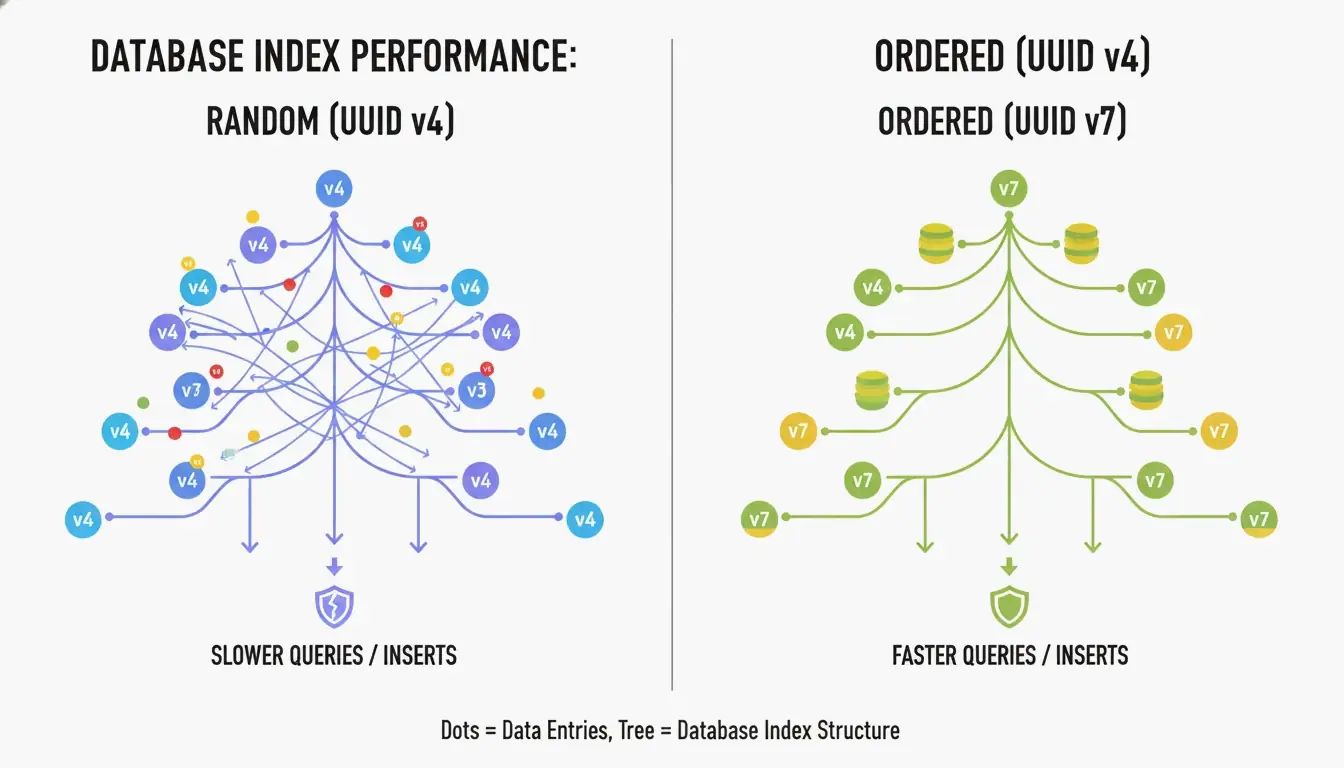
UUID v7 समय और एन्ट्रॉपी को कैसे संतुलित करता है
UUID v7 शेष 74 बिट्स को एक CSPRNG (क्रिप्टोग्राफिक रूप से सुरक्षित स्यूडो-रैंडम नंबर जनरेटर) से भरता है। विकिपीडिया के अनुसार, आपको 50% टकराव संभावना तक पहुँचने के लिए लगभग 85 वर्षों तक प्रति सेकंड 1 अरब UUID उत्पन्न करने होंगे। किसी भी वास्तविक अनुप्रयोग के लिए, UUID v7 व्यावहारिक रूप से टकराव-रहित है।
भंडारण की सर्वोत्तम प्रथाएँ: Binary(16) बनाम String(36)
आप UUID को कैसे संग्रहीत करते हैं, यह उतना ही मायने रखता है जितना कि आप कौन सा संस्करण उपयोग करते हैं:
| भंडारण प्रारूप | स्थान | इंडेक्स प्रदर्शन | अनुशंसा |
|---|---|---|---|
| Binary(16) | 16 बाइट | उच्च (कॉम्पैक्ट) | सर्वोत्तम प्रथा |
| नेटिव UUID प्रकार | 16 बाइट | उच्च (अनुकूलित) | PostgreSQL के लिए सर्वोत्तम |
| स्ट्रिंग (Char 36) | 36–72 बाइट | निम्न (विखंडित) | बचें |
SnapUtils हमेशा स्ट्रिंग्स के बजाय नेटिव प्रकारों का उपयोग करने की सलाह देता है। PostgreSQL में, नेटिव uuid प्रकार डेटा को कॉम्पैक्ट 16-बाइट बाइनरी प्रारूप में संग्रहीत करता है, साथ ही मानक स्ट्रिंग-आधारित क्वेरी का भी समर्थन करता है।
UUID बनाम GUID: कोई अंतर है क्या?
GUID (Globally Unique Identifier, वैश्विक विशिष्ट पहचानकर्ता) UUID मानक का Microsoft का कार्यान्वयन है। ऐतिहासिक रूप से, बाइट क्रम (endianness) में अंतर था — प्रारंभिक Microsoft GUID ने पहले तीन फ़ील्ड के लिए little-endian का उपयोग किया, जबकि मानक UUID ने big-endian (नेटवर्क बाइट क्रम) का उपयोग किया (SnapUtils)।
2026 तक, यह ज्यादातर एक नामकरण परंपरा है। RFC 9562 के तहत, वे समान रूप से काम करते हैं। .NET में Guid.NewGuid() Python में uuid.uuid4() के साथ पूरी तरह संगत है। आप Windows/Azure के घेरों में “GUID” और Linux तथा ओपन-सोर्स समुदायों में “UUID” सुनेंगे।
आधुनिक UUID लागू करना: भाषा-दर-भाषा
| भाषा | UUID v4 | UUID v7 |
|---|---|---|
| Python | अंतर्निहित uuid मॉड्यूल |
uuid6 या uuid7 पैकेज |
| JavaScript | crypto.randomUUID() |
uuid npm पैकेज (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
नेटिव uuidv7() (PG 17+) या एक्सटेंशन |
| .NET | Guid.NewGuid() |
सामुदायिक पैकेज |
| Rust | uuid क्रेट (v1.7+) |
v7 फ़ीचर के साथ uuid क्रेट |
नियतात्मक IDs: UUID v5
यदि आपको किसी दिए गए इनपुट (जैसे URL या उपयोगकर्ता नाम) के लिए हर बार वही ID चाहिए, तो UUID v5 का उपयोग करें। यह एक नेमस्पेस UUID और एक नाम स्ट्रिंग को SHA-1 से हैश करता है — जब आप केंद्रीय डेटाबेस से जाँच नहीं कर सकते तब डिडुप्लिकेशन के लिए एकदम सही।
UUID v1 का गोपनीयता सबक
UUID v1 एक टाइमस्टैम्प और कंप्यूटर के MAC पते का उपयोग करता है। इसे काफी हद तक त्याग दिया गया है क्योंकि यह हार्डवेयर जानकारी लीक करता है। एक प्रसिद्ध उदाहरण: मेलिसा वायरस का निर्माता इसलिए पकड़ा गया क्योंकि संक्रमित वर्ड दस्तावेज़ों में UUID में उसका विशिष्ट MAC पता शामिल था।
उन्नत RFC 9562: v6, v8, और विशेष UUID
RFC 9562 ने वितरित प्रणाली की विशिष्ट आवश्यकताओं के लिए विशेष संस्करण जोड़े:
| संस्करण | उद्देश्य | कब उपयोग करें |
|---|---|---|
| v6 | पुनर्व्यवस्थित v1 टाइमस्टैम्प — v1 की परिशुद्धता बनाए रखते हुए क्रमबद्ध | लीगेसी v1 सिस्टम का माइग्रेशन |
| v8 | कस्टम — डेवलपर-परिभाषित डेटा के लिए 122 बिट्स | प्रायोगिक या विक्रेता-विशिष्ट योजनाएँ |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
नल प्लेसहोल्डर |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
श्रेणी समाप्ति बिंदु मार्कर |
निष्कर्ष
RFC 9562 ने आधुनिक क्लाउड युग के लिए विशिष्ट पहचानकर्ताओं को अपडेट किया है। व्यावहारिक मार्गदर्शन:
- डेटाबेस प्राथमिक कुंजियाँ → समय-क्रमित, विखंडन-मुक्त निवेश के लिए UUID v7 का उपयोग करें
- सामान्य यादृच्छिकता → UUID v4 अभी भी पूरी तरह ठीक है
- डिडुप्लिकेशन → UUID v5 आपको नियतात्मक IDs देता है
- भंडारण → हमेशा Binary(16) या नेटिव UUID प्रकार का उपयोग करें, कभी स्ट्रिंग नहीं
कार्रवाई आइटम: अपने डेटाबेस स्कीमा जाँचें। यदि आप लाखों पंक्तियों वाली तालिकाओं में प्राथमिक कुंजी के रूप में UUID v4 का उपयोग कर रहे हैं, तो UUID v7 में माइग्रेट करना एक सीधा बदलाव है जो इंडेक्स विखंडन को काफी कम कर सकता है और क्वेरी को गति दे सकता है।
अक्सर पूछे जाने वाले प्रश्न
क्या UUID वही है जो GUID?
कार्यात्मक रूप से, हाँ। GUID UUID मानक का Microsoft का कार्यान्वयन है। RFC 9562 के तहत, वे व्यवहार में समान हैं — आप इन्हें .NET, Java, और Python अनुप्रयोगों के बीच परस्पर उपयोग कर सकते हैं।
क्या वास्तविक परिदृश्य में दो UUID कभी टकरा सकते हैं?
गणितीय रूप से संभव, व्यावहारिक रूप से असंभव। UUID v4 के लिए, आपको 50% टकराव संभावना तक पहुँचने के लिए लगभग 2.71 क्विंटिलियन IDs उत्पन्न करने होंगे। Generate-Random.org के अनुसार, 85 वर्षों तक प्रति सेकंड 1 अरब UUID उत्पन्न करने पर भी आपको केवल 50% मौका मिलता है कि एक भी टकराव हो।
क्या मुझे डेटाबेस में UUID को स्ट्रिंग या बाइनरी के रूप में संग्रहीत करना चाहिए?
हमेशा Binary(16) या नेटिव UUID प्रकार (PostgreSQL में उपलब्ध) को प्राथमिकता दें। 36-अक्षर की स्ट्रिंग दोगुने से अधिक स्थान का उपभोग करती है और इंडेक्स लुकअप तथा जॉइन को काफी धीमा कर देती है।SnapUtils नोट करता है कि RFC 9562 के प्रदर्शन लाभ तब अधिकतम होते हैं जब भंडारण कॉम्पैक्ट रहे।
मुझे UUID v4 के बजाय UUID v5 कब उपयोग करना चाहिए?
जब आपको नियतात्मक IDs चाहिए तब v5 का उपयोग करें — वही इनपुट हमेशा वही UUID उत्पन्न करता है, बिना डेटाबेस से जाँच के। जब आपको पूर्ण यादृच्छिकता चाहिए और यह सुनिश्चित करना चाहते हैं कि पहचानकर्ता को उसके स्रोत तक रिवर्स-इंजीनियर न किया जा सके, तब v4 का उपयोग करें।
प्रातिक्रिया दे