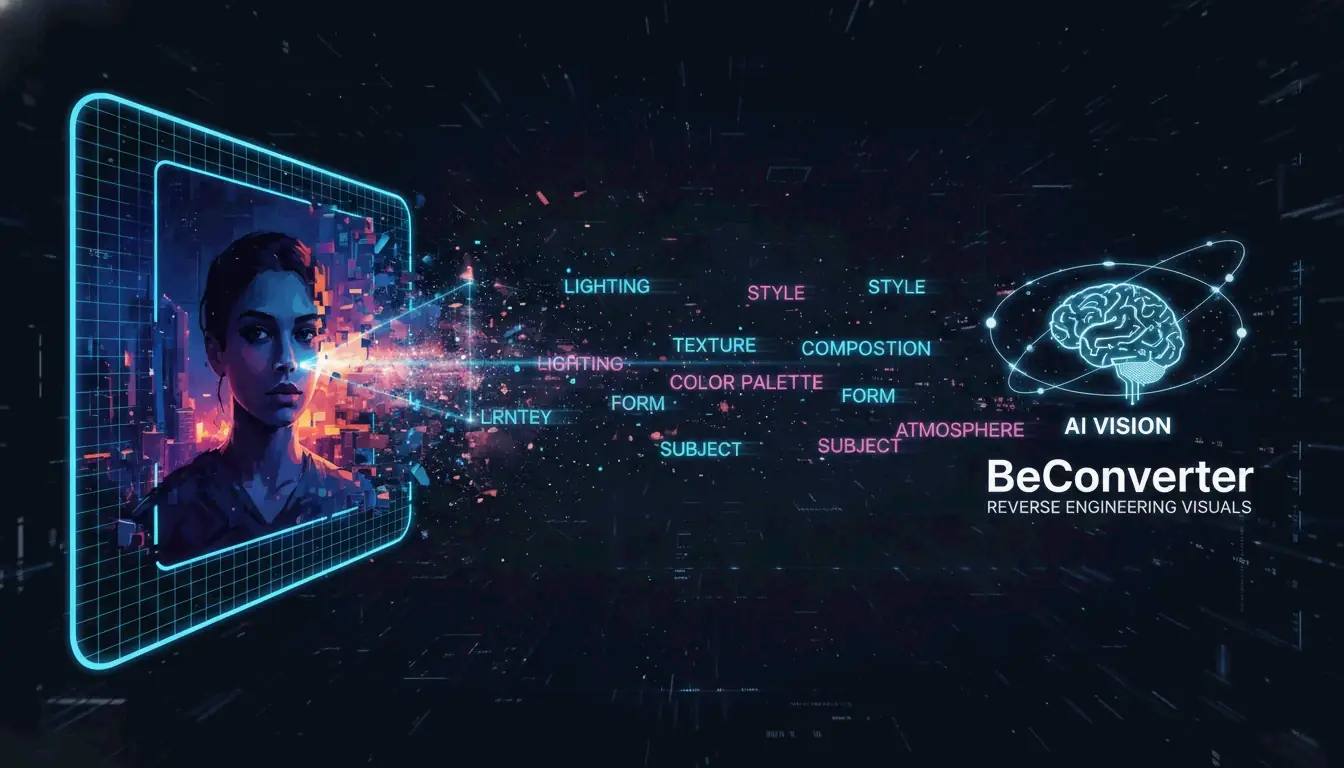
BeConverter में एक इमेज अपलोड करें, इसकी Vision-Language Model (VLM) विज़ुअल को स्टाइल टोकन में विघटित करने दें, फिर निकाले गए prompt को Midjourney, Stable Diffusion, या FLUX में पेस्ट करें। किसी भी विज़ुअल को पुन: उत्पादन योग्य AI prompt में बदलने का यह पूरा workflow है — बिना किसी अनुमान के।
रिवर्स प्रॉम्प्टिंग क्या है और BeConverter कैसे काम करता है?
रिवर्स प्रॉम्प्टिंग पिक्सल को वापस टेक्स्ट में बदलती है जिसे एक जेनरेटिव मॉडल समझ सकता है। शून्य से prompt लिखने और आउटपुट के संदर्भ से मेल खाने की उम्मीद करने के बजाय, आप तैयार इमेज से शुरू करते हैं और उन सटीक कीवर्ड, लाइटिंग स्थितियों और सौंदर्य टैग्स को निकालते हैं जो इसकी दिखावट को परिभाषित करते हैं।
BeConverter एक Vision-Language Model (VLM) का उपयोग करके इमेज के कलात्मक गुणों का विश्लेषण करता है। मॉडल आपकी फोटो की तुलना अपने ट्रेनिंग डेटा से करके रेंडरिंग स्टाइल (3D बनाम ऑयल पेंटिंग), लाइटिंग सेटअप (वॉल्यूमेट्रिक बनाम एम्बिएंट), और कंपोज़िशन जैसे विशेषताओं को वर्गीकृत करता है। परिणाम एक संरचित टेक्स्ट prompt होता है जिसे आप किसी भी इमेज जनरेटर में उपयोग कर सकते हैं।
VLM बनाम OCR: स्टैंडर्ड स्कैनिंग आर्ट क्यों नहीं पढ़ सकती
Optical Character Recognition (OCR) टेक्स्ट पढ़ता है — अक्षर, संख्याएँ, रसीदें। एक VLM कला निर्देशन पढ़ता है। जैसा कि PromptsEra समझाता है, जहाँ OCR एक साइन पर “STOP” शब्द देखता है, वहीं एक VLM अष्टकोणीय आकार, मटमैला लाल पेंट, गहराई का क्षेत्र और सूर्य के कोण का पता लगाता है — विज़ुअल पुनरुत्पादन के लिए आवश्यक विवरण।
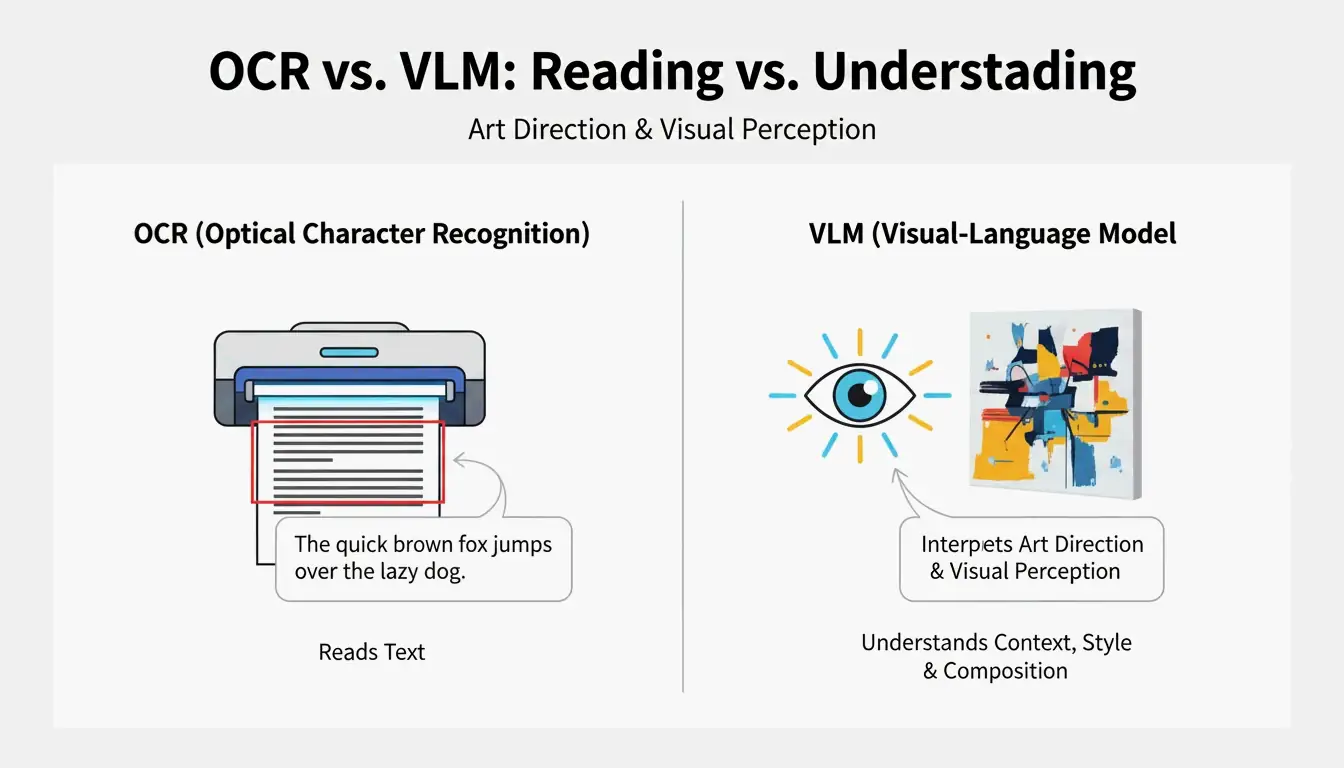
| क्षमता | OCR | VLM |
|---|---|---|
| टेक्स्ट पढ़ता है | हाँ | सीमित |
| लाइटिंग पहचानता है | नहीं | हाँ |
| कंपोज़िशन स्टाइल का पता लगाता है | नहीं | हाँ |
| कलर ग्रेडिंग निकालता है | नहीं | हाँ |
| Prompt-तैयार टेक्स्ट आउटपुट करता है | नहीं | हाँ |
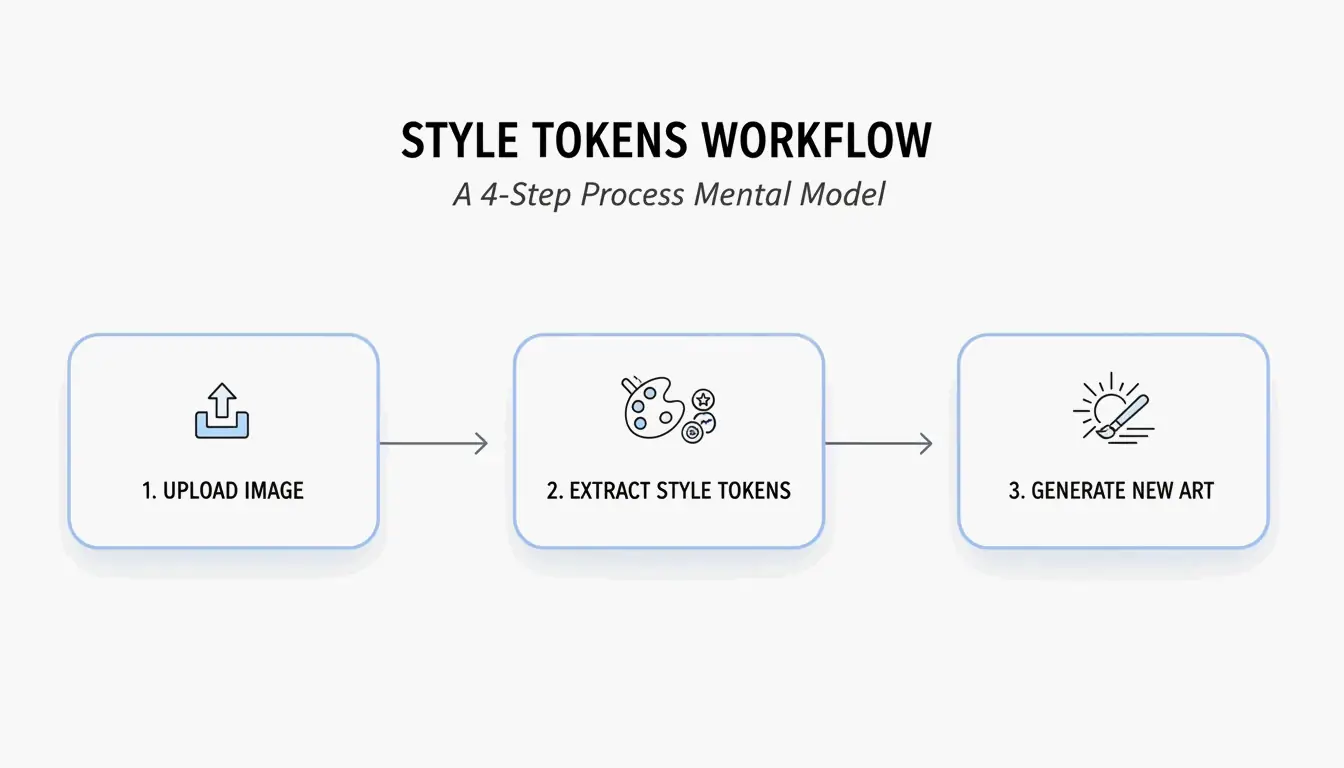
4-चरण वर्कफ़्लो: BeConverter से AI Prompt कैसे बनाएं
PromptsEra की Style Token Isolation Strategy के आधार पर, इस अनुक्रम का पालन करें:
- अपनी सोर्स इमेज अपलोड करें — उच्च-रिज़ॉल्यूशन फ़ाइल का उपयोग करें। VLM को सूक्ष्म विशेषताओं जैसे “volumetric lighting” या “35mm lens grain” का पता लगाने के लिए स्पष्ट पिक्सल की आवश्यकता होती है।
- अपना इंटरोगेटर चुनें — वर्णनात्मक, काव्यात्मक prompt के लिए CLIP Interrogator चुनें (Midjourney के लिए आदर्श) या कॉमा-सेपरेटेड टैग के लिए DeepDanbooru (Stable Diffusion के लिए आदर्श)।
- स्टाइल टोकन अलग करें — सब्जेक्ट टोकन (जैसे “a cat”) हटाएँ और केवल स्टाइल मार्कर (जैसे “cyberpunk, neon rim lighting, 8k, cinematic depth of field”) बनाए रखें।
- अपने जनरेटर में पेस्ट करें — साफ किए गए टोकन को Midjourney v7, Stable Diffusion, या FLUX में कॉपी करें और जनरेट करें।
2026 मॉडल के लिए Prompt अनुकूलन: FLUX बनाम Midjourney
प्रत्येक मॉडल prompt को अलग तरह से व्याख्या करता है। PromptsEra बताता है कि अमूर्त विवरण जैसे “melancholy atmosphere” Midjourney में अच्छा काम करता है लेकिन FLUX में विफल होता है, जिसे शाब्दिक स्थानिक विवरणों की आवश्यकता होती है जैसे “dark room with rain hitting the window, overhead fluorescent light casting long shadows.”
| Prompt स्टाइल | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| अमूर्त/काव्यात्मक | मजबूत | कमज़ोर | मध्यम |
| शाब्दिक/स्थानिक | मध्यम | मजबूत | मध्यम |
| कॉमा-सेपरेटेड टैग | मध्यम | मध्यम | मजबूत |
| नेगेटिव prompt | समर्थित (--no) |
समर्थित | समर्थित |
फ्रेंकेन्स्टाइन रणनीति: कई इमेज से स्टाइल मर्ज करना
सबसे प्रभावी रिवर्स इंजीनियरिंग तकनीक विभिन्न स्रोतों से स्टाइल टोकन को जोड़ती है। BeConverter का उपयोग करके Image A से लाइटिंग और Image B से सब्जेक्ट रेंडरिंग निकालें, फिर उन्हें एक ही prompt में मर्ज करें।
सुसंगत मर्जिंग के लिए मुख्य नियंत्रण:
- आस्पेक्ट रेश्यो — स्पष्ट रूप से सेट करें (जैसे, Midjourney के लिए
--ar 16:9) क्योंकि रिवर्स टूल आपके इच्छित कैनवास का अनुमान नहीं लगा सकते। - नेगेटिव Prompt — हमेशा “blurry, deformed, low quality” जैसे बहिष्करण जोड़ें। रिवर्स टूल केवल पता लगाते हैं कि क्या मौजूद है; वे यह नहीं पहचान सकते कि क्या अनुपस्थित होना चाहिए।
जैसा कि Andrew Lo, MIT के लेबोरेटरी फॉर फाइनेंशियल इंजीनियरिंग के निदेशक, सलाह देते हैं: “हमेशा LLM से पूछें, आप किस बारे में अनिश्चित हैं? आपके लिए कौन सी जानकारी अनुपस्थित है?” वही सिद्धांत लागू करें — जनरेट करने से पहले अपने पुनर्निर्मित prompt में अंतराल की पहचान करें।
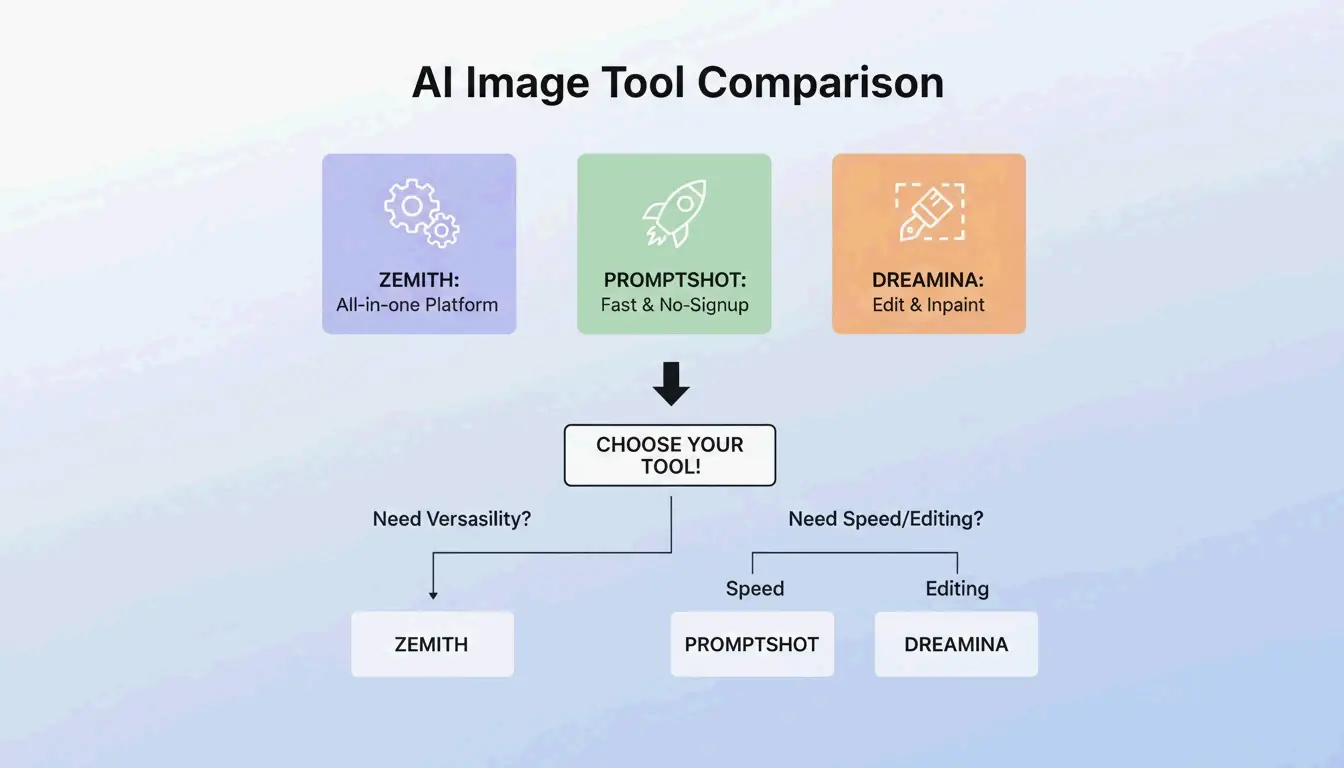
BeConverter बनाम Zemith बनाम PromptShot: टूल तुलना (2026)
| विशेषता | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| इंटरोगेटर मोड | CLIP + DeepDanbooru | मल्टी-मॉडल (25+) | सिंगल-पास |
| दैनिक मुफ्त क्रेडिट | हाँ | 100 | असीमित |
| साइन-अप आवश्यक | नहीं | हाँ | नहीं |
| के लिए सर्वोत्तम | टोकन आइसोलेशन | ऑल-इन-वन वर्कफ़्लो | त्वरित एक्सट्रैक्शन |
| आउटपुट फॉर्मेट | वर्णनात्मक + टैग | मॉडल-विशिष्ट | Prompt स्ट्रिंग |
अतिरिक्त विकल्प जिन पर ध्यान देने योग्य है:
- Zemith — 2026 तक 30,000 से अधिक उपयोगकर्ता। Zemith के अनुसार, यह GPT-5.5 सहित 25+ मॉडल का समर्थन करता है जिसमें 100 दैनिक क्रेडिट शामिल हैं।
- PromptShot AI — कोई खाता आवश्यक नहीं। PromptShot AI उन रचनाकारों के लिए डिज़ाइन की गई 5-चरण प्रक्रिया प्रदान करता है जिन्हें AI आर्ट को जल्दी “पुनः बनाने और सुधारने” की आवश्यकता होती है।
- Dreamina (GPT Image 2) — एक विंडो में जनरेट और संपादित करें। Dailyhunt के अनुसार, GPT Image 2 मॉडल prompt जनरेशन के तुरंत बाद inpainting और लाइटिंग समायोजन का समर्थन करता है।
निष्कर्ष
BeConverter के साथ रिवर्स प्रॉम्प्टिंग किसी भी संदर्भ इमेज को सेकंडों में एक संरचित, पुन: उपयोग योग्य AI prompt में बदल देती है। अपनी इमेज अपलोड करें, CLIP या DeepDanbooru के साथ स्टाइल टोकन निकालें, कलात्मक विशेषताओं को अलग करें, और अपनी पसंद के जनरेटर में पेस्ट करें। सर्वोत्तम परिणामों के लिए, prompt फॉर्मेट को अपने लक्ष्य मॉडल के अनुसार अनुकूलित करें — Midjourney के लिए अमूर्त, FLUX के लिए शाब्दिक, Stable Diffusion के लिए टैग-आधारित — और आउटपुट गुणवत्ता बनाए रखने के लिए हमेशा नेगेटिव prompt शामिल करें।
अक्सर पूछे जाने वाले प्रश्न
क्या रिवर्स प्रॉम्प्टिंग किसी अन्य रचनाकार द्वारा उपयोग किए गए मूल prompt को पुनर्प्राप्त कर सकती है?
नहीं। यह विज़ुअल विश्लेषण के आधार पर एक वर्णनात्मक अनुमान का पुनर्निर्माण करती है। विभिन्न VLM मॉडल विभिन्न विशेषताओं को प्राथमिकता देते हैं, इसलिए आउटपुट एक उच्च-गुणवत्ता वाला पुनर्निर्माण है — न कि छिपा हुआ मेटाडेटा या कीस्ट्रोक रिकवरी।
क्या इमेज-से-prompt तकनीक वास्तविक स्मार्टफ़ोन फ़ोटोग्राफ़ पर काम करती है?
हाँ। PromptsEra बताता है कि VLM वास्तविक-दुनिया की विशेषताओं जैसे “golden hour lighting” या विशिष्ट कैमरा लेंस की पहचान कर सकते हैं और उन बनावटों को कलात्मक पुनर्व्याख्या के लिए prompt में अनुवाद कर सकते हैं।
क्या कॉपीराइटेड कलाकृति से निकाले गए prompt का उपयोग करना कानूनी है?
Prompt छोटे टेक्स्ट स्ट्रिंग होते हैं और आमतौर पर कॉपीराइट द्वारा कवर नहीं होते हैं। नैतिक दृष्टिकोण अपने स्वयं के मूल काम को सूचित करने के लिए स्टाइल टोकन निकालना है। जैसा कि PromptsEra बताता है, संरक्षित चरित्र की सटीक प्रतिलिपि बनाने का प्रयास कानूनी समस्याएँ पैदा कर सकता है — इन टूल का उपयोग तकनीक सीखने के लिए करें, कॉपी करने के लिए नहीं।
प्रातिक्रिया दे