Besoin de transformer une feuille de calcul, un fichier CSV ou JSON en un tableau Markdown propre ? En 2026, le processus est simple — le bon outil dépend de ce que vous faites : une conversion ponctuelle ou l’automatisation de la documentation à grande échelle.
Ce guide passe en revue les meilleurs outils pour chaque scénario : des éditeurs visuels pour le travail manuel, des outils en ligne de commande (CLI) pour l’automatisation, et l’intégration CI/CD pour garder la documentation synchronisée avec votre base de code.
Les meilleurs outils en un coup d’œil
| Outil | Idéal pour | Type | Atout principal |
|---|---|---|---|
| TableGenerator.com | Éditions visuelles rapides | Web (côté client) | Éditeur en grille, contrôles d’alignement |
| AnywayData | Fichiers JSON complexes | Web / bibliothèque | Aplatissement des structures imbriquées, analyse AST |
| MarkItDown (Microsoft) | Automatisation Excel/Word | CLI Python | Préserve les en-têtes et grilles des fichiers Office |
| Pandoc | Conversion multi-formats | CLI | Prend en charge des dizaines de formats, stable à grande échelle |
| EaseCloud | Excel → GFM | Web | Convertisseur simple basé sur le navigateur |
| GoConverter | Excel → GFM | Web | Conversion rapide avec options d’alignement |
Selon DasRoot (2026), les outils Markdown modernes peuvent traiter 15–30 tables par seconde pour des jeux de données de taille moyenne — et les meilleurs utilisent un traitement côté client, ce qui signifie que vos données ne quittent jamais votre navigateur.
Pourquoi la conformité GFM compte
GitHub Flavored Markdown (GFM) est le dialecte spécifique utilisé par GitHub, GitLab et Discord. La spécification Markdown d’origine ne prenait pas du tout en charge les tableaux — GFM a ajouté la syntaxe familière à base de « pipes et tirets ». Un générateur conforme à GFM garantit que vos tableaux s’affichent correctement avec des en-têtes en gras et des colonnes alignées, plutôt que d’apparaître comme du texte brut.

Comment convertir Excel et CSV en GFM
Le processus se déroule en deux étapes :
- Exporter en CSV — Enregistrez votre fichier Excel ou Google Sheets au format CSV. Cela supprime la mise en forme lourde tout en préservant la grille de données.
- Convertir — Utilisez un outil basé sur le navigateur comme EaseCloud ou GoConverter pour générer le code GFM.
Alignement des colonnes
GFM contrôle l’alignement via la ligne de séparation (la ligne située sous l’en-tête) :
| Syntaxe | Alignement |
|---|---|
:--- |
Aligné à gauche (par défaut) |
---: |
Aligné à droite |
:---: |
Aligné au centre |
Échapper les caractères pipe
Markdown utilise | pour marquer les bords des colonnes. Si vos données contiennent un pipe (dans un extrait de code ou une formule, par exemple), cela cassera le tableau. Échappez-le avec :
- Entité HTML :
| - Barre oblique inversée :
\| - Apostrophes inverses de code :
`|`
Gérer les grands jeux de données (100+ lignes)
Pour les jeux de données de plus de 100 lignes, les éditeurs visuels en ligne peuvent ramer. Les convertisseurs modernes utilisent un analyse incrémentale pour rester réactifs. Selon AnywayData, l’utilisation d’une « logique de données combinatoire par paires » peut réduire les cas de test nécessaires de 90–99%, ce qui aide lors de la documentation de configurations complexes.
Pour les très grands jeux de données, envisagez de diviser le contenu en plusieurs tableaux ou de fournir un lien de téléchargement CSV à côté de la version Markdown.
Convertir JSON en GFM : aplatir les données imbriquées
JSON est hiérarchique — des données imbriquées comme des poupées russes. Les tableaux Markdown sont des grilles 2D plates. La conversion nécessite une logique d’aplatissement :
user.address.city → "User Address City" (en-tête de colonne unique)
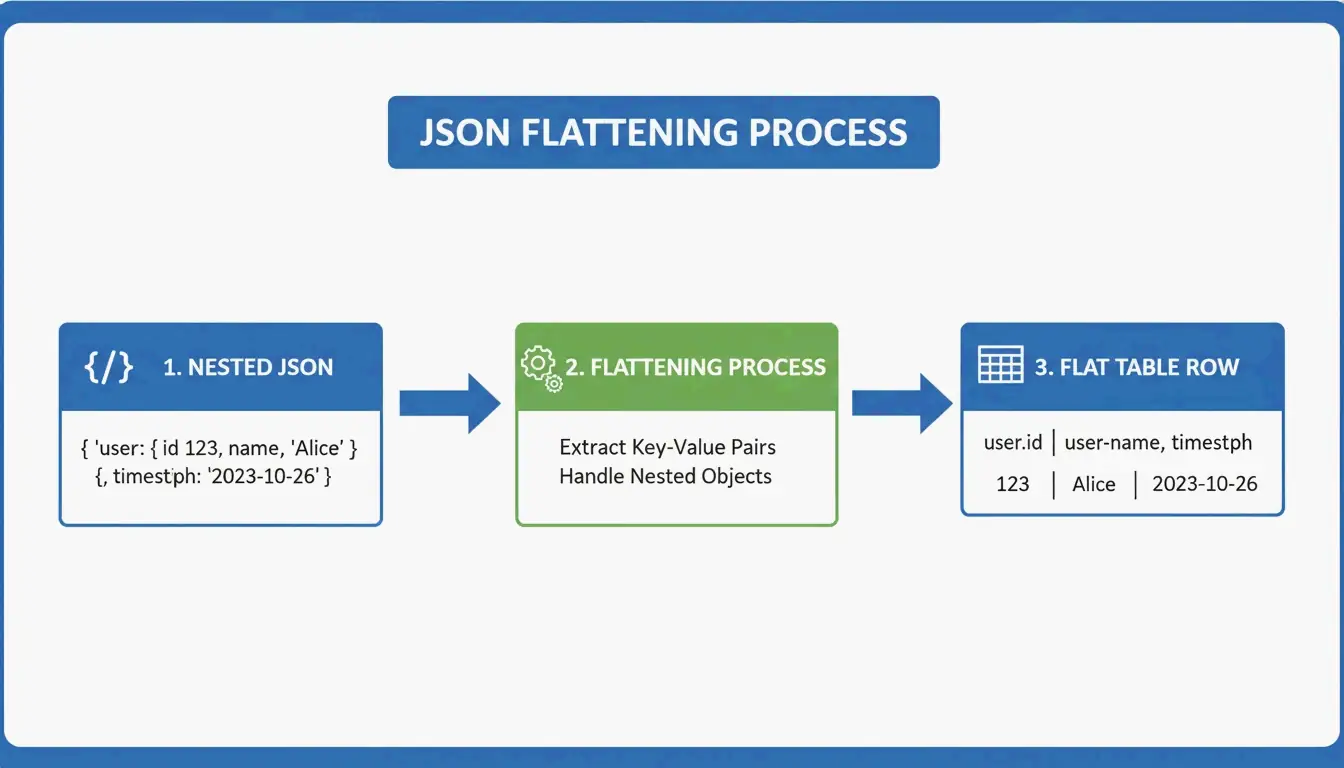
Le Grid Table Editor d’AnywayData excelle ici — il vous permet d’importer du JSON et de contrôler manuellement la façon dont les couches imbriquées sont aplaties. La qualité de la conversion dépend de si l’outil utilise une construction AST (Abstract Syntax Tree) plutôt qu’une simple correspondance de motifs textuels. Les analyseurs basés sur AST construisent une carte logique de la structure des données, gérant les imbrications plus profondes et les schémas incohérents avec une précision bien supérieure.
Automatiser avec CI/CD
Pour les équipes d’ingénierie, la conversion manuelle est une perte de temps. Intégrer la génération de tableaux dans votre pipeline CI/CD garantit que les fichiers README restent à jour automatiquement :
- Convertir les réponses des API JSON en GFM pendant le processus de build
- Traiter la documentation comme du code — elle se met à jour quand vos données changent
- Éviter le problème récurrent des informations obsolètes ou incorrectes dans votre dépôt
Des outils comme Terraform-docs v0.17.0 (2026) injectent automatiquement les tableaux de ressources directement dans les fichiers README — ce qui prouve que les outils CLI surpassent souvent les interfaces web pour la documentation au niveau infrastructure.
MarkItDown contre Pandoc : lequel choisir ?
| Critère | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| Optimisé pour | Fichiers Office (Excel, Word) | Conversion universelle de documents |
| Variantes Markdown | Axé GFM | CommonMark, GFM et bien d’autres |
| Idéal pour | Conversion rapide XLSX → tableau GitHub | Travail CLI multi-formats et haut volume |
| Dernière version | 2026 | 3.9.0.2 (stable) |
| Vitesse | Plus rapide pour un fichier Office unique | Meilleur pour le traitement par lots |
| À utiliser quand | Vous devez convertir un seul fichier Excel | Vous devez convertir entre des dizaines de formats |
Pour la plupart des développeurs, MarkItDown est plus rapide dans le cas courant (Excel → tableau GitHub). Pandoc est le meilleur choix lorsque vous jonglez avec de nombreux formats de documents ou que vous lancez des conversions par lots à grande échelle.
Conclusion
Convertir des données en tableaux GFM en 2026 se résume au volume et au flux de travail :
- Éditions ponctuelles → TableGenerator.com ou AnywayData pour un contrôle visuel
- Conversions Office récurrentes → MarkItDown intégré à votre workflow Python
- Multi-formats ou haut volume → Pandoc pour le traitement par lots en CLI
- Documentation d’infrastructure → Automatisation CI/CD avec terraform-docs ou des scripts personnalisés
Le principe clé : la documentation doit se mettre à jour quand vos données se mettent à jour. Automatiser la conversion évite les tableaux obsolètes et maintient la documentation de votre projet fiable.
FAQ
Comment échapper les caractères pipe (|) dans une cellule de tableau Markdown ?
Utilisez l’entité HTML | à la place du pipe littéral. Vous pouvez aussi utiliser un échappement par barre oblique inversée \| si votre analyseur GFM le prend en charge, ou encadrer le contenu avec des apostrophes inverses de code. Ces trois méthodes empêchent le pipe d’être interprété comme un séparateur de colonne.
GFM prend-il en charge les cellules fusionnées ou le contenu multiligne ?
Non. Le GFM standard ne prend pas en charge colspan ni rowspan. Chaque cellule doit être indépendante. Pour du contenu multiligne au sein d’une cellule, utilisez des balises HTML <br> pour forcer les sauts de ligne tout en conservant les données dans une seule ligne.
Quelle est la meilleure approche pour les jeux de données de plus de 100 lignes ?
Évitez les éditeurs visuels basés sur le web (ils vont ramer). Utilisez plutôt des outils CLI comme MarkItDown ou Pandoc. Si le tableau résultant est trop volumineux pour une seule page, divisez-le en plusieurs tableaux ou fournissez un lien vers un fichier CSV téléchargeable pour préserver la lisibilité.
Laisser un commentaire