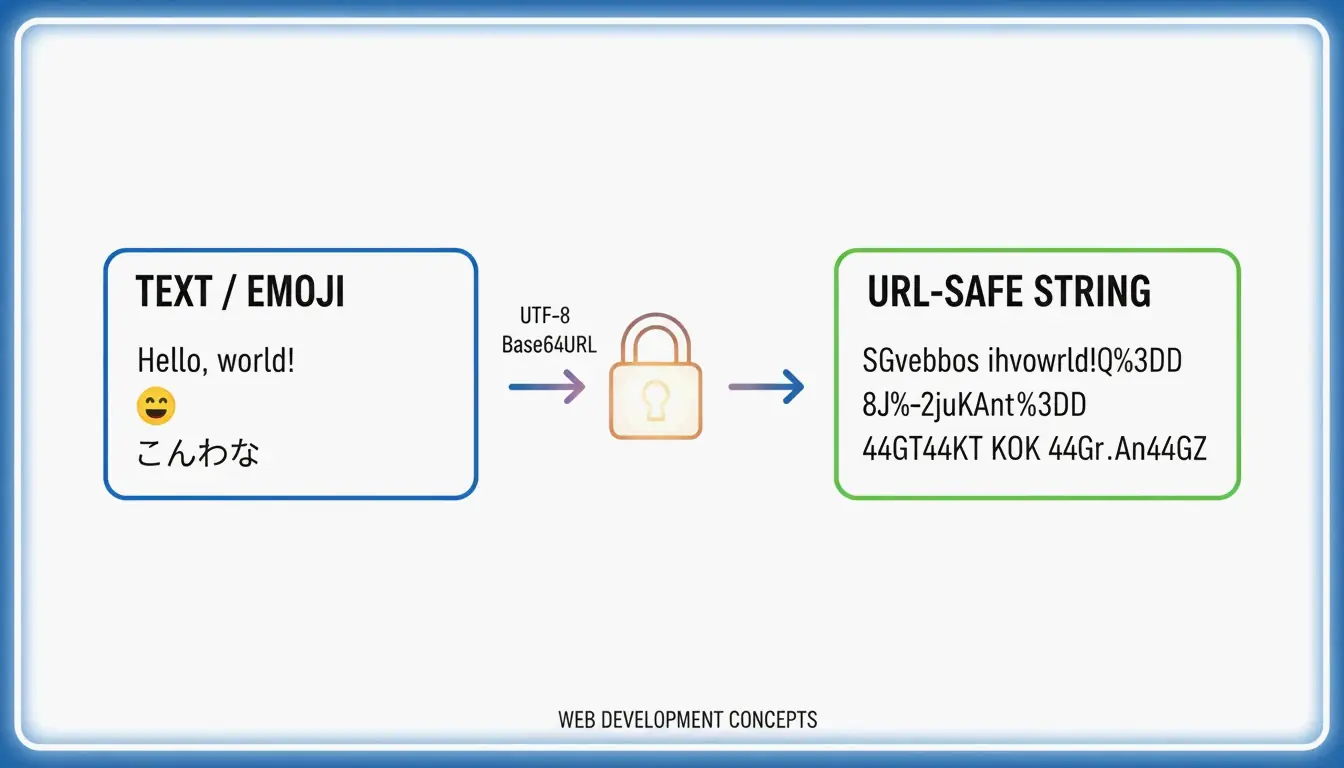
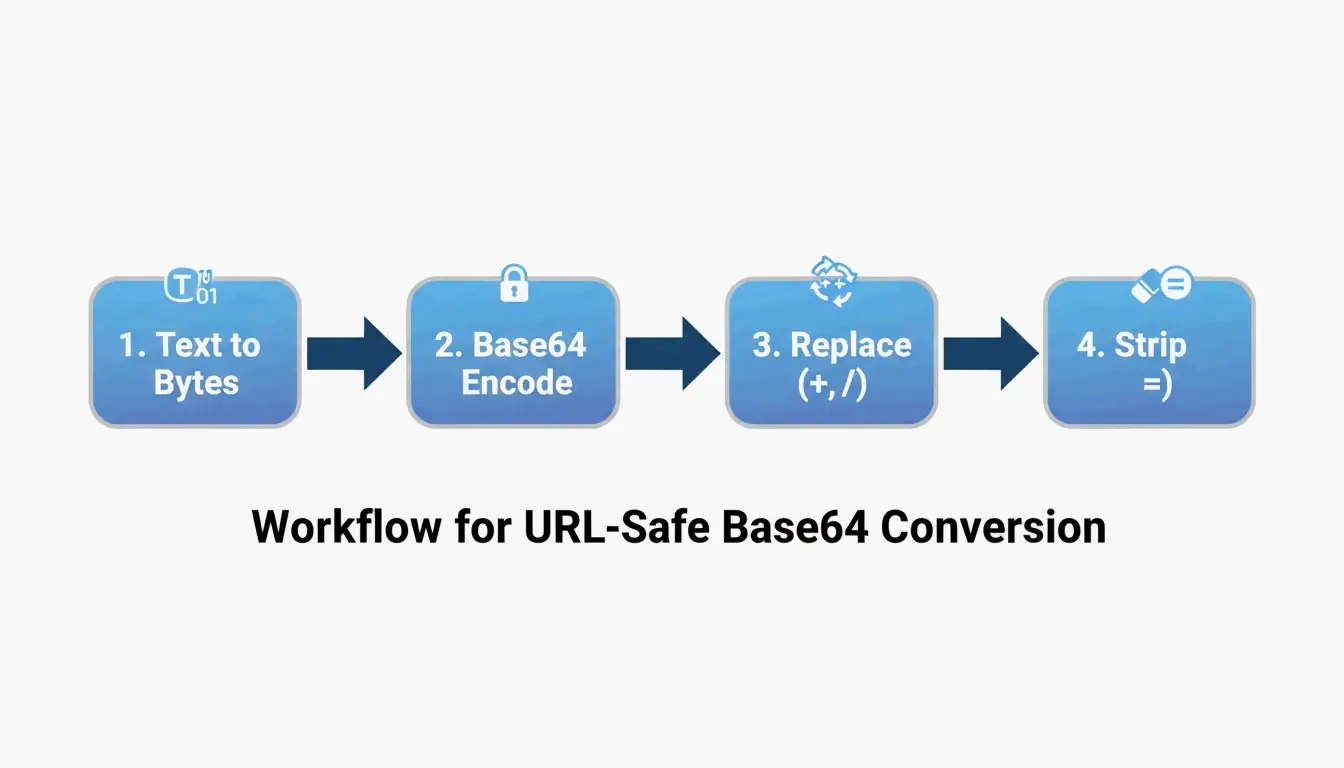
لـتحويل UTF-8 إلى Base64URL، اتبع 4 خطوات: (1) ترميز النص إلى بايتات UTF-8، (2) تطبيق Base64 القياسي، (3) استبدال + → - و / → _، (4) إزالة حشو = النهائي. يُنتج هذا سلسلة آمنة للروابط وفقًا لـ RFC 4648، تُستخدم في JWTs ورؤوس API.
Base64 القياسي مقابل Base64URL
| العنصر | Base64 القياسي | Base64URL | السبب |
|---|---|---|---|
| الحرف رقم 62 | + |
- |
+ يعني مسافة في الروابط |
| الحرف رقم 63 | / |
_ |
/ هو فاصل مسار في الروابط |
| الحشو | = مطلوب |
محذوف | = يصبح %3D في الروابط |
| آمن للروابط | لا | نعم | استخدام مباشر في سلاسل الاستعلام وأسماء الملفات |
وفقًا لـ RFC 4648 §5، يضمن هذا “الأبجدية الآمنة للروابط وأسماء الملفات” التوافق بين الأنظمة.

عملية التحويل المكونة من 4 خطوات
| الخطوة | العملية | مثال (“Hello”) |
|---|---|---|
| 1 | نص UTF-8 → بايتات | H e l l o → مصفوفة بايتات |
| 2 | بايتات → Base64 القياسي | SGVsbG8= |
| 3 | استبدال + → -، / → _ |
لا حاجة لتغيير هنا |
| 4 | إزالة حشو = النهائي |
SGVsbG8 |
يزيد ترميز Base64 حجم البيانات بنسبة ~33% وفقًا لـ ويكيبيديا.
التعامل مع Unicode والرموز التعبيرية
وفقًا لـ NextUtils، فإن Base64 هو ترميز وليس تشفيرًا — فهو ينقل البيانات عبر القنوات النصية فقط. للتعامل مع Unicode والرموز التعبيرية بدون مشاكل (“Mojibake”)، استخدم دائمًا TextEncoder للتحويل أولاً إلى بايتات UTF-8.
| المدخلات | بدون TextEncoder | مع TextEncoder |
|---|---|---|
Hello 世界! 🌍 |
Mojibake / TypeError | Base64URL صحيح |
أمثلة على الكود
JavaScript (المتصفح) — آمن لـ Unicode
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3 — المكتبة القياسية
وفقًا لـ AskPython:
import base64
data = "Hello 世界! 🌍"
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js — التحويل باستخدام Buffer
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
استكشاف الأخطاء وإصلاحها: أخطاء الحشو
| الخطأ | السبب | الحل |
|---|---|---|
binascii.Error: Incorrect padding |
حشو = مفقود |
أضف = حتى يصبح الطول من مضاعفات 4 |
TypeError مع atob() |
أحرف غير ASCII | استخدم TextEncoder أولاً |
| مخرجات مشوهة | تم تخطي ترميز UTF-8 | قم دائمًا بالترميز إلى بايتات قبل Base64 |
وفقًا لـ AskPython، احسب الحشو المفقود: padding_needed = (4 - len(data) % 4) % 4 ثم أضف نفس العدد من أحرف =.
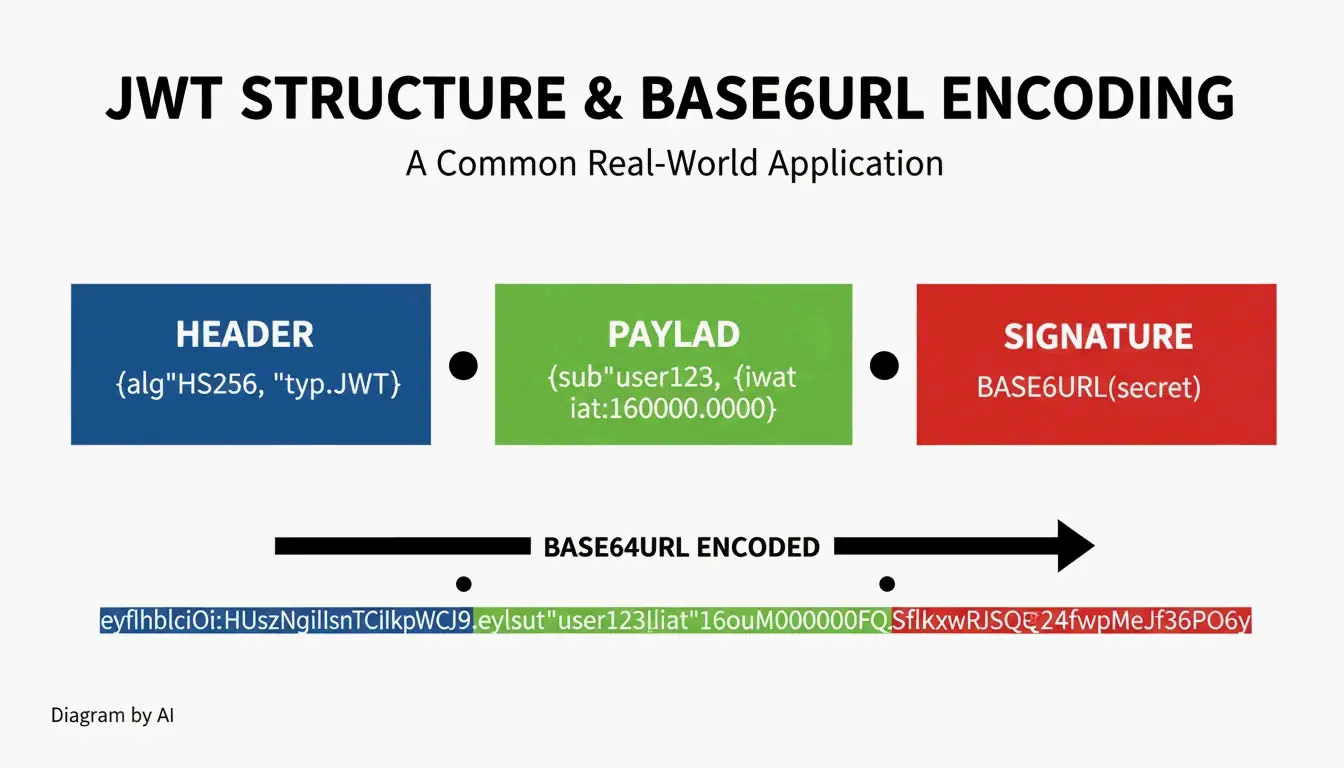
حالات الاستخدام: JWT ومعرّفات URIs للبيانات
هيكل JWT (JSON Web Token)
| الجزء | المحتوى | الترميز |
|---|---|---|
| الرأس | الخوارزمية + نوع الرمز | Base64URL |
| الحمولة | المطالبات (بيانات المستخدم، تاريخ الانتهاء) | Base64URL |
| التوقيع | توقيع HMAC أو RSA | Base64URL |
تبدأ JWTs غالبًا بـ eyJ — وهو ترميز Base64URL لـ { (قوس JSON الافتتاحي).
Base64 مقابل Base64URL حسب حالة الاستخدام
| حالة الاستخدام | الترميز | الحشو |
|---|---|---|
| رموز JWT | Base64URL | محذوف |
| معرّفات URIs للبيانات (الصور المضمّنة) | Base64 القياسي | مطلوب |
| مصادقة HTTP Basic | Base64 القياسي | مطلوب |
| معاملات الاستعلام في الروابط | Base64URL | محذوف |
الخلاصة
4 خطوات: بايتات UTF-8 → Base64 → استبدال +/ بـ -_ → إزالة الحشو. استخدم TextEncoder في JavaScript، و base64.urlsafe_b64encode() في Python، و Buffer في Node.js. اتبع RFC 4648 للتوافق بين الأنظمة. Base64URL هو ترميز وليس تشفيرًا — استخدم AES-256 أو TLS للأمان.
الأسئلة الشائعة
هل Base64URL هو نفسه التشفير؟
لا. Base64URL هو ترميز قابل للعكس — يمكن لأي شخص فك ترميزه بدون مفتاح. استخدم AES-256 أو TLS/SSL لحماية البيانات الحساسة.
لماذا يفشل Base64URL في أداة فك ترميز Base64 القياسية؟
تتوقع أدوات فك الترميز القياسية + و / وحشو =. يستخدم Base64URL الرموز - و _ ويحذف الحشو. اعكس استبدالات الأحرف واستعد الحشو قبل فك الترميز.
لماذا يتم حذف الحشو في JWTs؟
يتحول الحرف = إلى %3D في الروابط، مما يجعل السلاسل أطول وأصعب في القراءة. تسمح RFC 4648 بالحذف لأن أدوات فك الترميز يمكنها إعادة بناء الطول الأصلي بدون علامات الحشو.
اترك تعليقاً