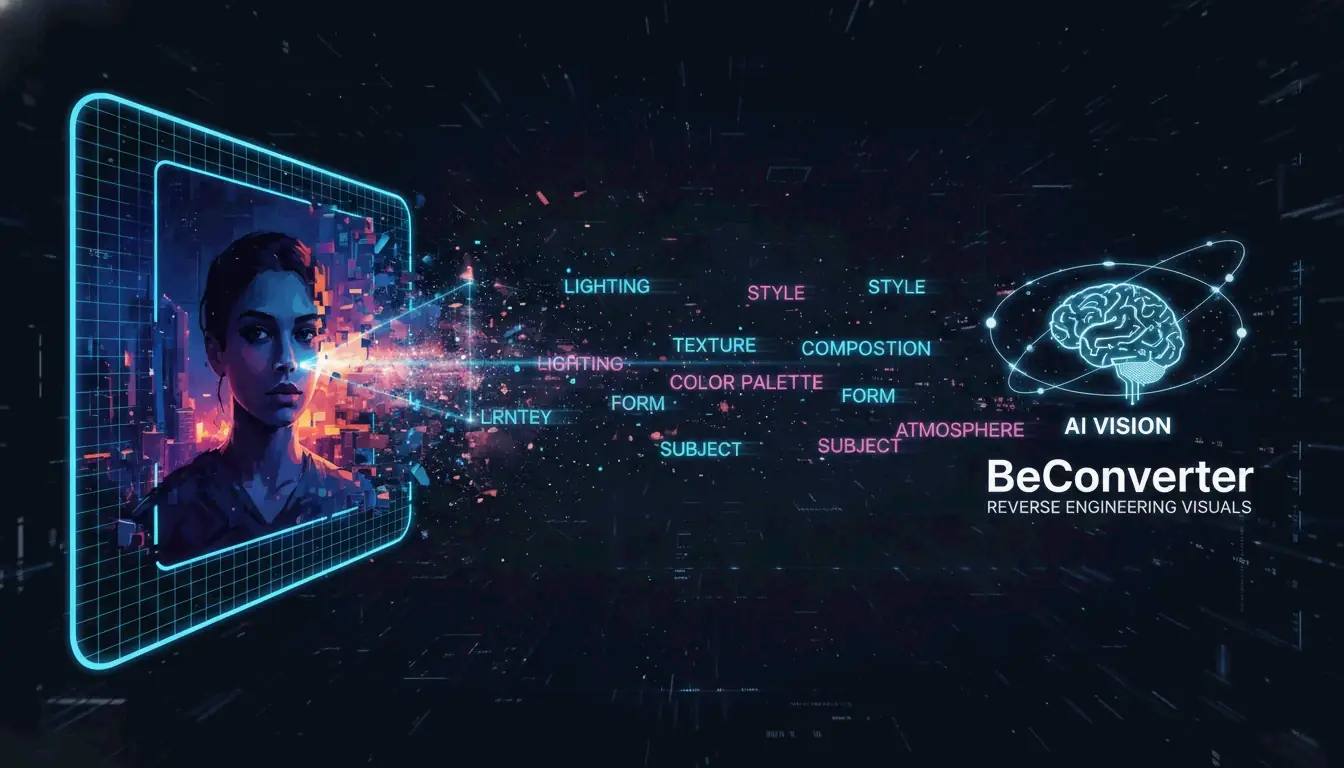
Laden Sie ein Bild in BeConverter hoch, lassen Sie das Vision-Language Model (VLM) das Bild in Stil-Tokens zerlegen und fügen Sie den extrahierten Prompt anschließend in Midjourney, Stable Diffusion oder FLUX ein. Das ist der komplette Workflow, um aus jedem Bild einen reproduzierbaren KI-Prompt zu machen — ohne Trial-and-Error.
Was ist Reverse Prompting und wie funktioniert BeConverter?
Reverse Prompting wandelt Pixel zurück in Text, den ein generatives Modell verstehen kann. Anstatt einen Prompt von Grund auf neu zu schreiben und zu hoffen, dass das Ergebnis einer Referenz entspricht, startet man mit dem fertigen Bild und extrahiert die exakten Schlagworte, Lichtverhältnisse und ästhetischen Tags, die sein Erscheinungsbild definieren.
BeConverter nutzt ein Vision-Language Model (VLM), um die künstlerischen Eigenschaften eines Bildes zu analysieren. Das Modell vergleicht Ihr Foto mit seinen Trainingsdaten und klassifiziert Attribute wie Rendering-Stil (3D vs. Olmalerei), Lichtsetzung (volumetrisch vs. Umgebungslicht) und Bildkomposition. Das Ergebnis ist ein strukturierter Text-Prompt, den Sie direkt in einen Bildgenerator einspeisen konnen.
VLM vs. OCR: Warum herkommliche Texterkennung keine Kunst lesen kann
Optical Character Recognition (OCR) liest Text — Buchstaben, Zahlen, Kassenbons. Ein VLM liest Kunstrichtung. Wie PromptsEra erklart: Wo OCR das Wort „STOPP“ auf einem Schild erkennt, registriert ein VLM die achteckige Form, die verblasste rote Farbe, die Schärfentiefe und den Einfallswinkel der Sonne — Details, die für die visuelle Reproduktion entscheidend sind.
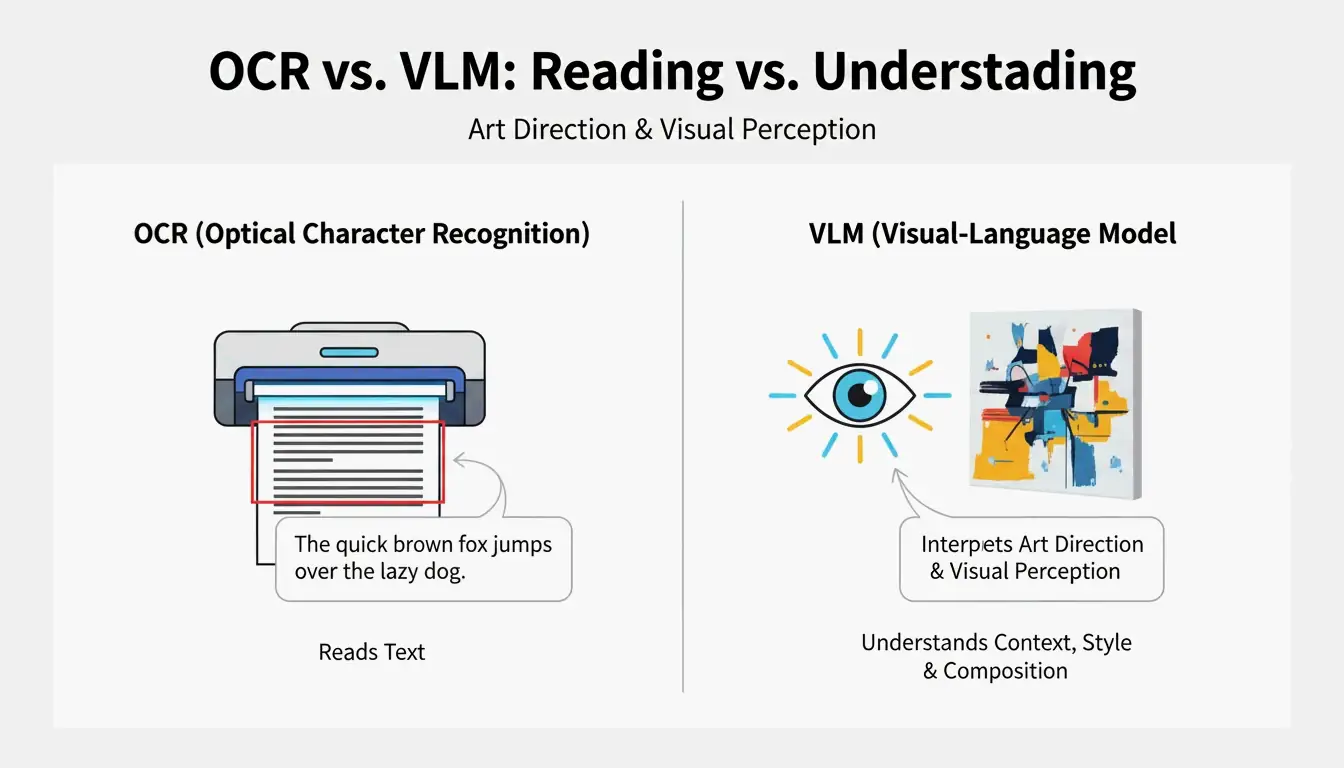
| Fähigkeit | OCR | VLM |
|---|---|---|
| Liest Text | Ja | Begrenzt |
| Erkennt Lichtstimmung | Nein | Ja |
| Erkennt Kompositionsstil | Nein | Ja |
| Extrahiert Color Grading | Nein | Ja |
| Gibt prompt-fähigen Text aus | Nein | Ja |
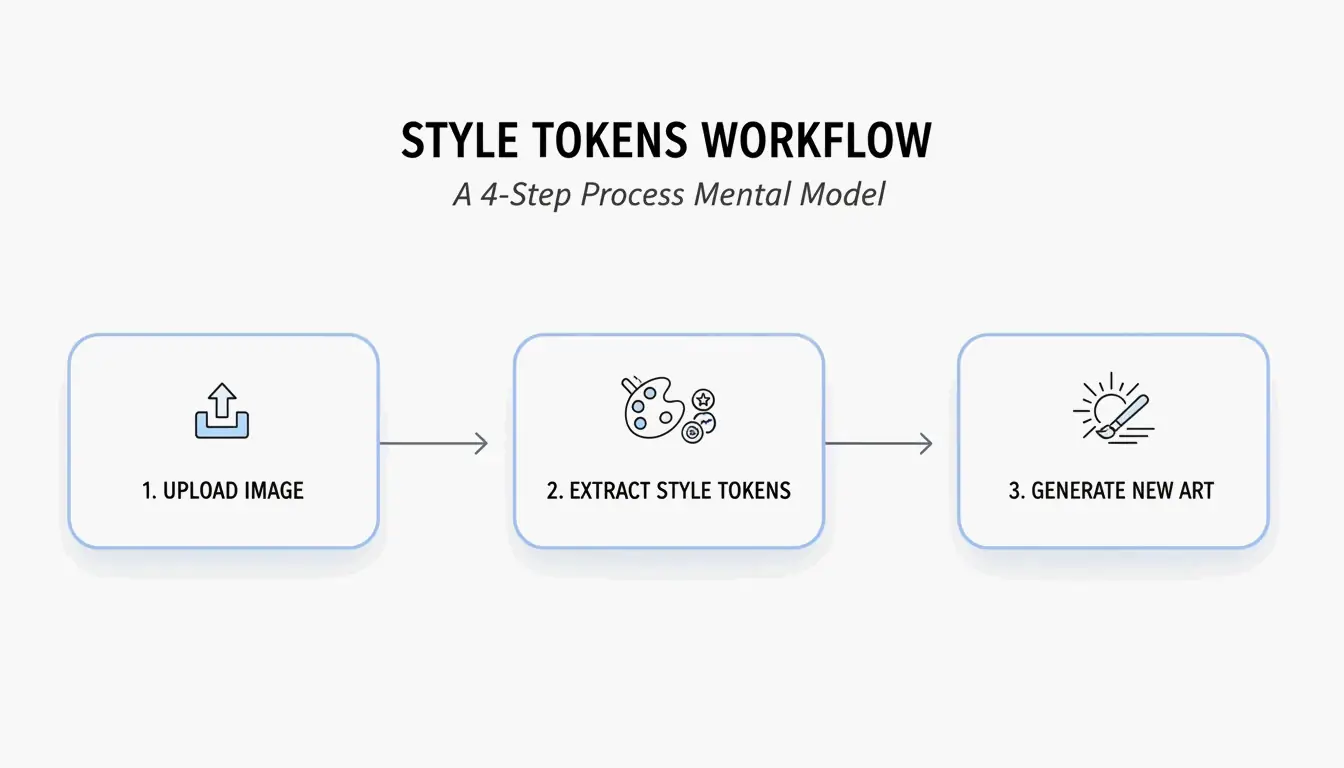
4-Schritte-Workflow: KI-Prompts mit BeConverter erstellen
Basierend auf der Style-Token-Isolationsstrategie von PromptsEra folgen Sie dieser Reihenfolge:
- Quellbild hochladen — Verwenden Sie eine hochauflösende Datei. Das VLM braucht klare Pixel, um subtile Attribute wie „volumetrisches Licht“ oder „35mm-Korn“ zu erkennen.
- Interrogator auswahlen — Wahlen Sie CLIP Interrogator fur beschreibende, poetische Prompts (ideal fur Midjourney) oder DeepDanbooru fur kommagetrennte Tags (ideal fur Stable Diffusion).
- Stil-Tokens isolieren — Loschen Sie die Subjekt-Tokens (z. B. „eine Katze“) und behalten Sie nur die Stil-Marker (z. B. „Cyberpunk, Neon-Rim-Lighting, 8k, filmische Schärfentiefe“).
- In den Generator einfugen — Kopieren Sie die bereinigten Tokens in Midjourney v7, Stable Diffusion oder FLUX und generieren Sie.
Prompts an 2026er Modelle anpassen: FLUX vs. Midjourney
Jedes Modell interpretiert Prompts unterschiedlich. PromptsEra merkt an, dass abstrakte Beschreibungen wie „melancholische Atmosphare“ in Midjourney gut funktionieren, in FLUX jedoch scheitern — FLUX bentigt konkrete raumliche Beschreibungen wie „dunkler Raum, Regen prallt gegen das Fenster, deckenmontierte Leuchtstofflampe wirft lange Schatten.“
| Prompt-Stil | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| Abstrakt/poetisch | Stark | Schwach | MittelmaBig |
| Konkret/raümlich | MittelmaBig | Stark | MittelmaBig |
| Kommagetrennte Tags | MittelmaBig | MittelmaBig | Stark |
| Negative Prompts | Unterstützt (--no) |
Unterstützt | Unterstützt |
Die Frankenstein-Strategie: Stile aus mehreren Bildern verschmelzen
Die wirkungsvollste Reverse-Engineering-Technik kombiniert Stil-Tokens aus verschiedenen Quellen. Nutzen Sie BeConverter, um die Beleuchtung aus Bild A und das Subjekt-Rendering aus Bild B zu extrahieren, und verschmelzen Sie beides zu einem einzigen Prompt.
Wichtige Steuerungselemente fur konsistente Verschmelzung:
- Seitenverhaltnis — Explizit festlegen (z. B.
--ar 16:9fur Midjourney), da Reverse-Tools Ihre geplante Leinwand nicht ableiten konnen. - Negative Prompts — Immer Ausschlusse wie „verschwommen, deformiert, schlechte Qualitat“ hinzufugen. Reverse-Tools erkennen nur, was vorhanden ist; sie konnen nicht identifizieren, was fehlen sollte.
Wie Andrew Lo, Direktor des MIT Laboratory for Financial Engineering, rät: „Fragen Sie das LLM immer: Worüber sind Sie unsicher? Welche Informationen fehlen Ihnen?“ Wenden Sie dasselbe Prinzip an — identifizieren Sie die Lücken in Ihrem rekonstruierten Prompt, bevor Sie generieren.
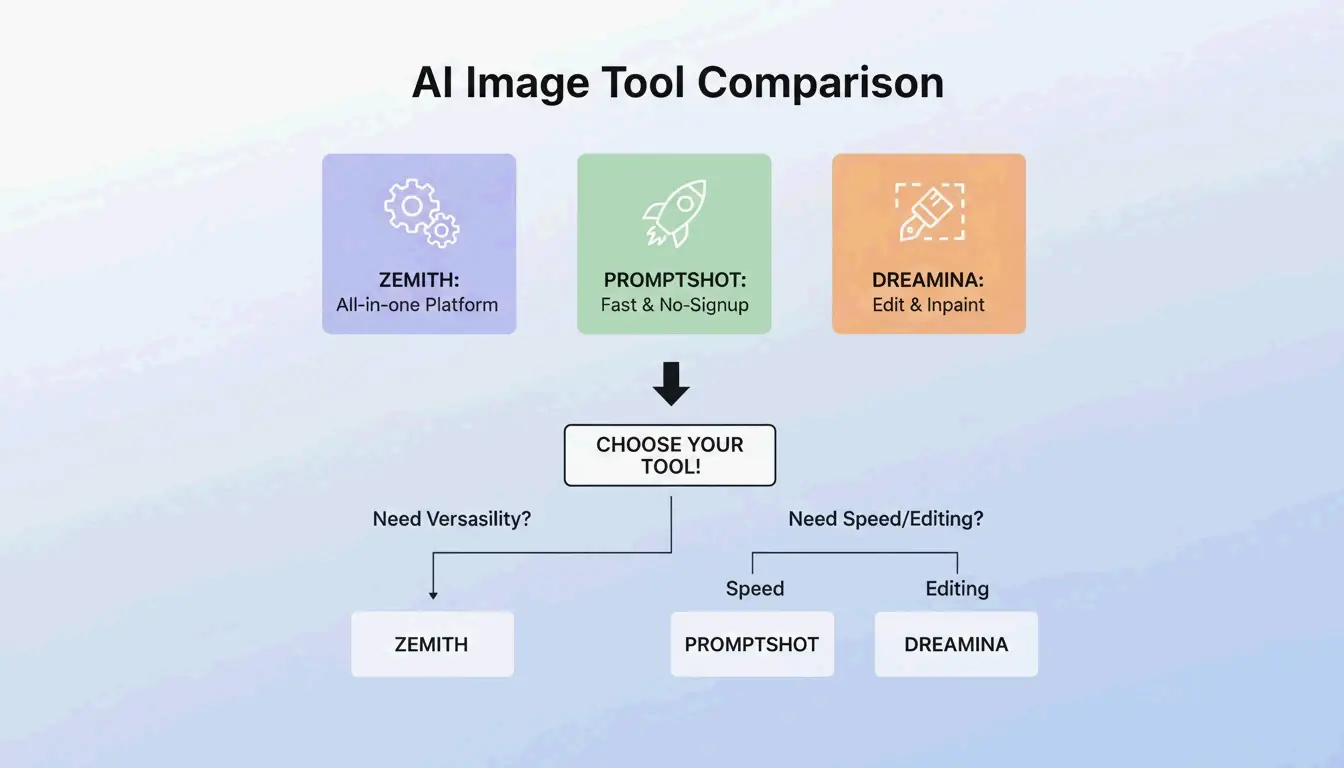
BeConverter vs. Zemith vs. PromptShot: Tool-Vergleich (2026)
| Feature | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| Interrogator-Modi | CLIP + DeepDanbooru | Multi-Modell (25+) | Einzeldurchlauf |
| Tägliche Gratis-Credits | Ja | 100 | Unbegrenzt |
| Registierung erforderlich | Nein | Ja | Nein |
| Am besten fur | Token-Isolation | All-in-One-Workflow | Schnelle Extraktionen |
| Ausgabeformat | Beschreibend + Tags | Modellspezifisch | Prompt-String |
Weitere erwähnenswerte Alternativen:
- Zemith — Uber 30.000 Nutzer Stand 2026. Laut Zemith werden 25+ Modelle einschließlich GPT-5.5 mit 100 täglichen Credits unterstützt.
- PromptShot AI — Kein Konto erforderlich. PromptShot AI bietet einen 5-Schritte-Prozess, der fur Kreative konzipiert ist, die KI-Kunst schnell „nachbilden und verbessern“ wollen.
- Dreamina (GPT Image 2) — Generieren und bearbeiten in einem Fenster. Laut Dailyhunt unterstützt das GPT Image 2-Modell Inpainting und Lichtanpassungen direkt nach der Prompt-Generierung.
Fazit
Reverse Prompting mit BeConverter wandelt jedes Referenzbild in Sekunden in einen strukturierten, wiederverwendbaren KI-Prompt um. Laden Sie Ihr Bild hoch, extrahieren Sie Stil-Tokens mit CLIP oder DeepDanbooru, isolieren Sie die künstlerischen Attribute und fügen Sie alles in den Generator Ihrer Wahl ein. Fur optimale Ergebnisse passen Sie das Prompt-Format an Ihr Zielmodell an — abstrakt fur Midjourney, konkret fur FLUX, tag-basiert fur Stable Diffusion — und erganzen Sie stets negative Prompts, um die Ausgabequalität zu sichern.
FAQ
Kann Reverse Prompting den exakten Original-Prompt eines anderen Erstellers rekonstruieren?
Nein. Es erstellt eine beschreibende Naherung basierend auf visueller Analyse. Verschiedene VLM-Modelle priorisieren unterschiedliche Attribute, sodass das Ergebnis eine hochwertige Rekonstruktion ist — keine verborgenen Metadaten oder Tastatureingaben.
Funktioniert Bild-zu-Prompt-Technologie auch bei echten Smartphone-Fotos?
Ja. PromptsEra merkt an, dass VLMs reale Attribute wie „Goldene-Stunde-Beleuchtung“ oder spezifische Kameraobjektive erkennen und diese Texturen in Prompts fur künstlerische Neuinterpretationen ubersetzen konnen.
Ist es legal, Prompts zu verwenden, die aus urheberrechtlich geschützten Kunstwerken extrahiert wurden?
Prompts sind kurze Textzeichenfolgen und fallen in der Regel nicht unter das Urheberrecht. Der ethische Ansatz besteht darin, Stil-Tokens zu extrahieren, um die eigene originäre Arbeit zu inspirieren. Wie PromptsEra anmerkt, kann der Versuch, eine geschützte Figur exakt zu kopieren, rechtliche Probleme nach sich ziehen — nutzen Sie diese Tools, um Techniken zu erlernen, nicht um abzuschreiben.
Schreibe einen Kommentar