이미지를 BeConverter에 업로드하고, Vision-Language Model(VLM)이 비주얼을 스타일 토큰으로 분해한 다음, 추출된 프롬프트를 Midjourney, Stable Diffusion 또는 FLUX에 붙여넣기만 하면 된다. 이것이 모든 비주얼을 재현 가능한 AI 프롬프트로 변환하는 완전한 워크플로우다. 추측은 필요 없다.
리버스 프롬프팅이란 무엇이며, BeConverter는 어떻게 작동하는가?
리버스 프롬프팅은 픽셀을 생성 모델이 이해할 수 있는 텍스트로 변환하는 기술이다. 프롬프트를 처음부터 작성하고 출력이 참조 이미지와 일치하기를 바라는 대신, 완성된 이미지에서 출발하여 그 외관을 정의하는 정확한 키워드, 조명 조건, 미학 태그를 추출한다.
BeConverter는 Vision-Language Model(VLM)을 사용하여 이미지의 예술적 속성을 분석한다. 모델은 사진을 학습 데이터와 비교하여 렌더링 스타일(3D vs 유화), 조명 설정(볼루메트릭 vs 앰비언트), 구도 등의 속성을 분류한다. 그 결과 어떤 이미지 생성기에든 입력할 수 있는 구조화된 텍스트 프롬프트를 얻을 수 있다.
VLM과 OCR의 차이: 일반 스캐닝으로 아트를 읽을 수 없는 이유
광학 문자 인식(OCR)은 텍스트(글자, 숫자, 영수증)를 읽는다. 반면 VLM은 _아트 디렉션_을 읽는다. PromptsEra가 설명하듯이, OCR이 표지판 위의 “STOP”이라는 글자를 읽는다면, VLM은 팔각형 모양, 바랜 빨간 페인트, 피사계 심도, 태양의 각도를 감지한다. 이는 비주얼 재현에 필수적인 요소들이다.
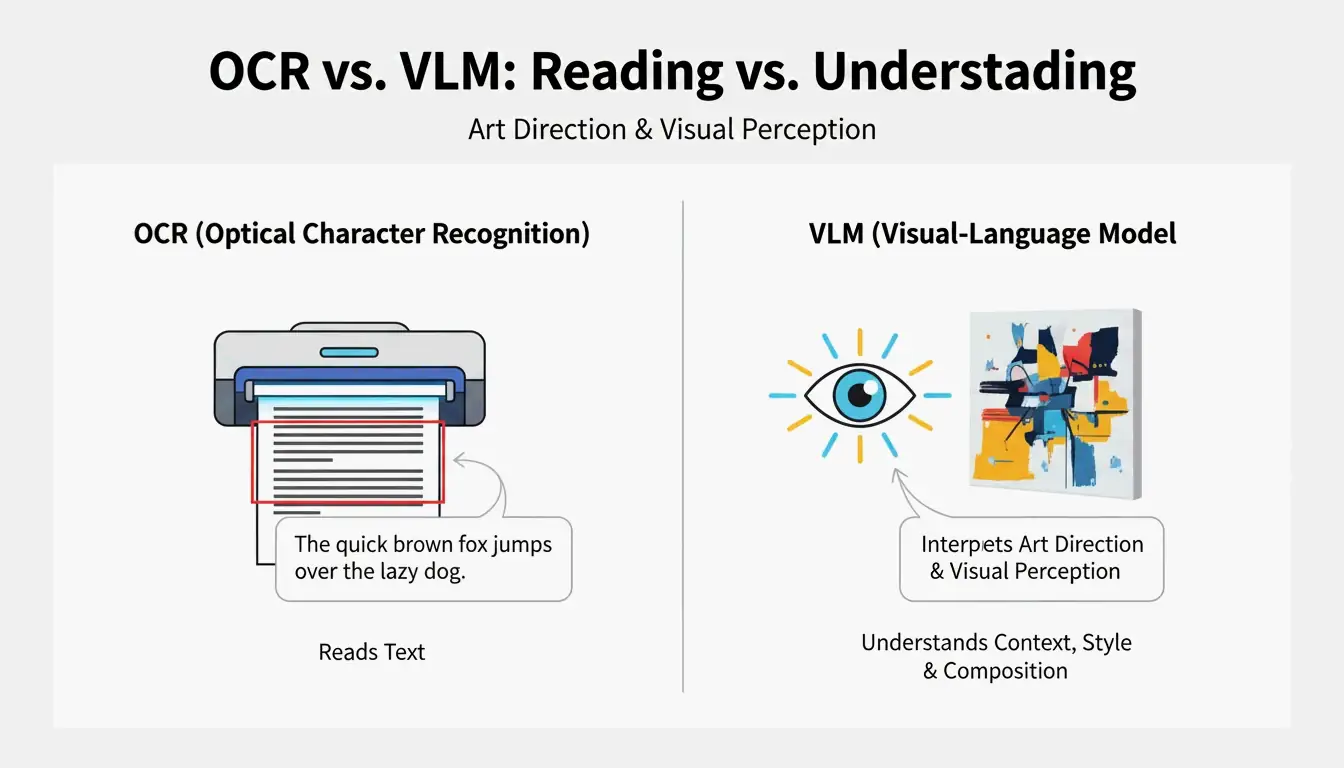
| 기능 | OCR | VLM |
|---|---|---|
| 텍스트 읽기 | 가능 | 제한적 |
| 조명 식별 | 불가 | 가능 |
| 구도 스타일 감지 | 불가 | 가능 |
| 컬러 그레이딩 추출 | 불가 | 가능 |
| 프롬프트용 텍스트 출력 | 불가 | 가능 |
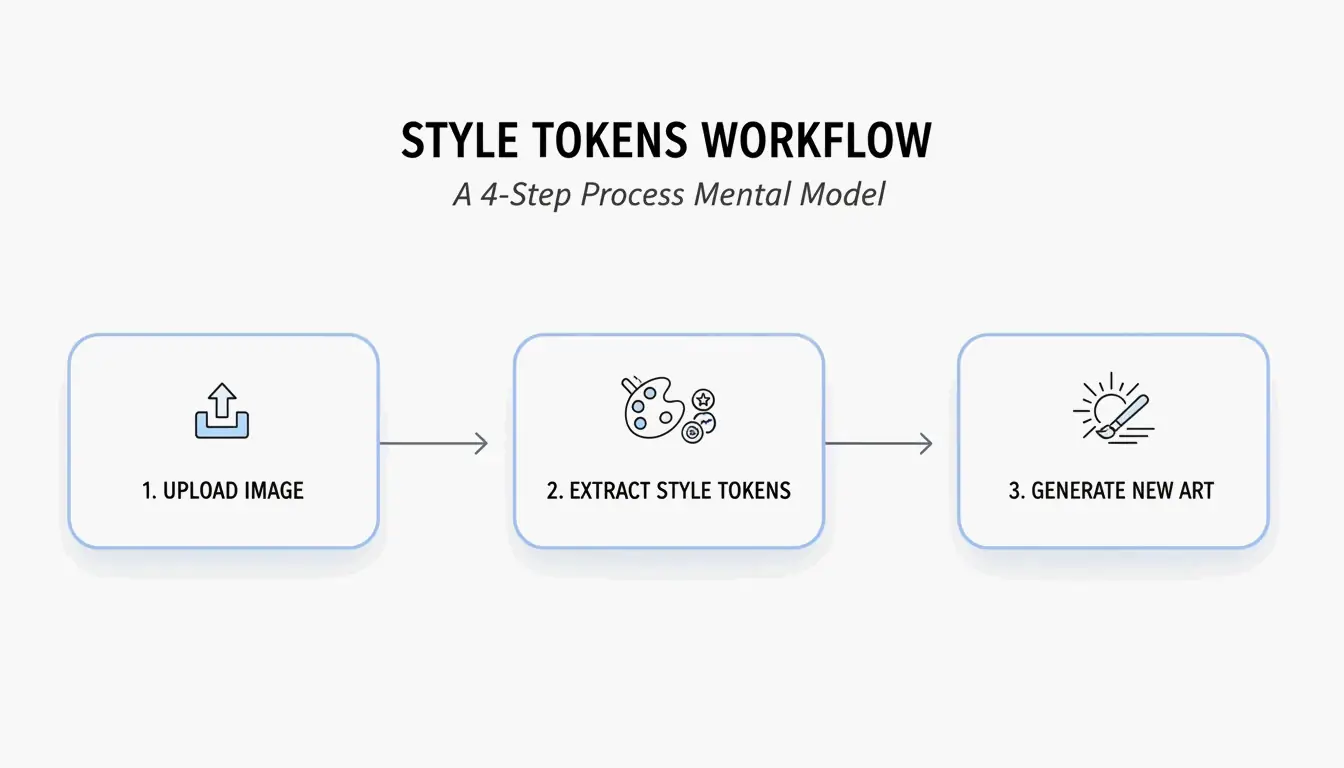
4단계 워크플로우: BeConverter로 AI 프롬프트 만들기
PromptsEra의 스타일 토큰 분리 전략을 기반으로 다음 순서를 따른다:
- 소스 이미지를 업로드한다 — 고해상도 파일을 사용한다. VLM이 “볼루메트릭 라이팅”이나 “35mm 렌즈 그레인” 같은 미묘한 속성을 감지하려면 선명한 픽셀이 필요하다.
- 인터로게이터를 선택한다 — 서술적이고 시적인 프롬프트에는 CLIP Interrogator를 선택(Midjourney에 이상적), 쉼표로 구분된 태그에는 DeepDanbooru를 선택(Stable Diffusion에 이상적).
- 스타일 토큰을 분리한다 — 피사체 토큰(예: “a cat”)을 삭제하고 스타일 마커(예: “cyberpunk, neon rim lighting, 8k, cinematic depth of field”)만 유지한다.
- 생성기에 붙여넣는다 — 정리된 토큰을 Midjourney v7, Stable Diffusion 또는 FLUX에 복사하여 생성한다.
2026년 모델을 위한 프롬프트 적응: FLUX vs. Midjourney
각 모델은 프롬프트를 다르게 해석한다. PromptsEra에 따르면, “우울한 분위기” 같은 추상적 설명은 Midjourney에서 잘 작동하지만 FLUX에서는 실패한다. FLUX는 “비가 창문을 때리는 어두운 방, 머리 위 형광등이 긴 그림자를 드리우는” 같은 구체적인 공간적 설명을 필요로 한다.
| 프롬프트 스타일 | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| 추상/시적 | 강함 | 약함 | 보통 |
| 구체적/공간적 | 보통 | 강함 | 보통 |
| 쉼표 구분 태그 | 보통 | 보통 | 강함 |
| 네거티브 프롬프트 | 지원(--no) |
지원 | 지원 |
프랑켄슈타인 전략: 여러 이미지에서 스타일 병합하기
가장 효과적인 리버스 엔지니어링 기법은 서로 다른 소스의 스타일 토큰을 결합하는 것이다. BeConverter를 사용하여 이미지 A에서 조명을 추출하고 이미지 B에서 피사체 렌더링을 추출한 다음, 이를 하나의 프롬프트로 병합한다.
일관된 병합을 위한 핵심 제어 항목:
- 화면 비율 — 리버스 도구는 의도한 캔버스 크기를 추론할 수 없으므로 명시적으로 설정해야 한다(예: Midjourney의 경우
--ar 16:9). - 네거티브 프롬프트 — 항상 “blurry, deformed, low quality” 같은 제외 항목을 추가한다. 리버스 도구는 _존재하는 것_만 감지할 수 있다. 없어야 할 것을 식별할 수는 없다.
MIT 금융공학 연구소 소장인 Andrew Lo는 다음과 같이 조언한다: “항상 LLM에게 묻라. 당신은 무엇에 대해 불확실한가? 어떤 정보가 누락되어 있는가?” 같은 원칙을 적용하여, 재구성된 프롬프트의 빈틈을 생성하기 전에 파악하는 것이 중요하다.
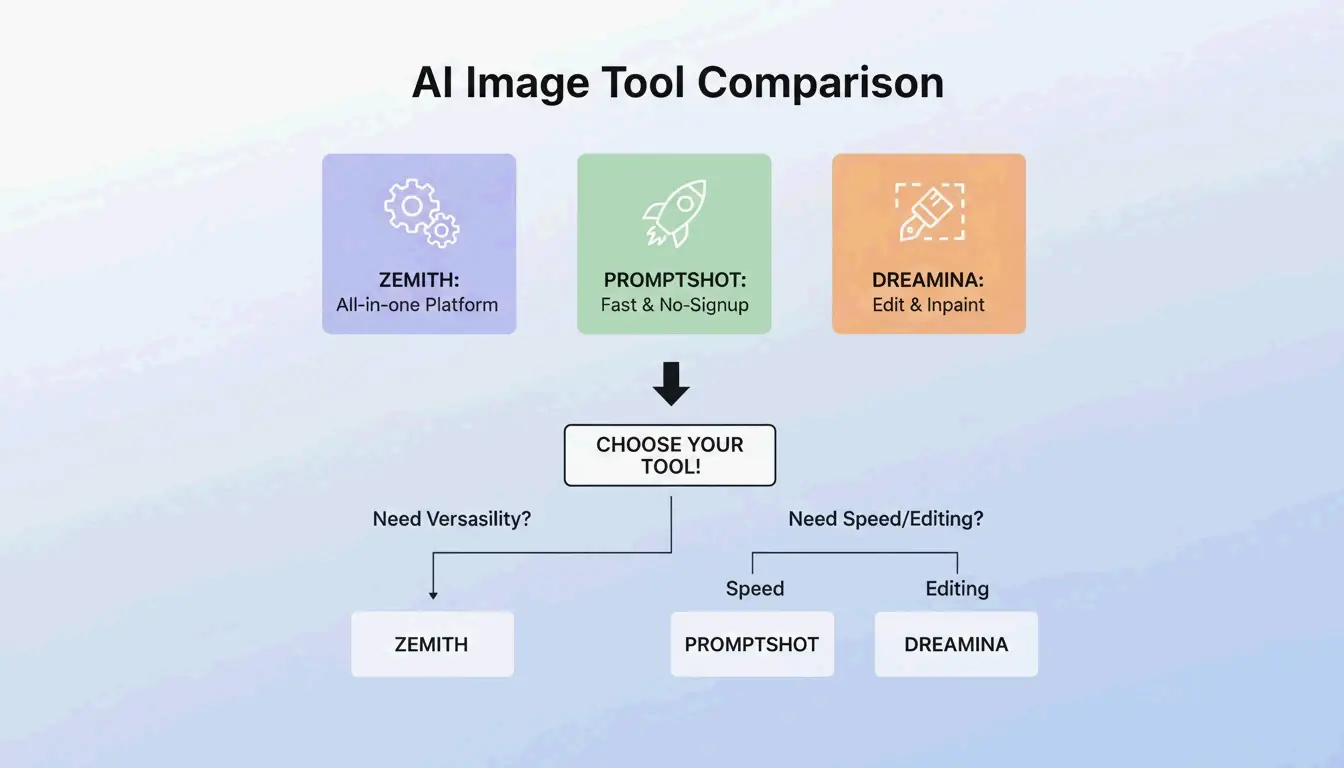
BeConverter vs. Zemith vs. PromptShot: 도구 비교 (2026년)
| 기능 | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| 인터로게이터 모드 | CLIP + DeepDanbooru | 멀티모델(25종 이상) | 싱글패스 |
| 무료 데일리 크레딧 | 있음 | 100 | 무제한 |
| 가입 필요 | 불필요 | 필요 | 불필요 |
| 최적 용도 | 토큰 분리 | 올인원 워크플로우 | 빠른 추출 |
| 출력 형식 | 서술적 + 태그 | 모델별 | 프롬프트 문자열 |
추가로 주목할 만한 옵션:
- Zemith — 2026년 현재 30,000명 이상의 사용자. Zemith에 따르면 GPT-5.5를 포함한 25종 이상의 모델을 지원하며 하루 100 크레딧을 제공한다.
- PromptShot AI — 계정이 필요 없다. PromptShot AI는 AI 아트를 빠르게 “재현하고 개선”해야 하는 크리에이터를 위한 5단계 프로세스를 제공한다.
- Dreamina (GPT Image 2) — 한 창에서 생성과 편집이 가능. Dailyhunt에 따르면, GPT Image 2 모델은 프롬프트 생성 직후 인페인팅과 조명 조정을 지원한다.
결론
BeConverter를 활용한 리버스 프롬프팅은 어떤 참조 이미지든 몇 초 만에 구조화되고 재사용 가능한 AI 프롬프트로 변환한다. 이미지를 업로드하고, CLIP 또는 DeepDanbooru로 스타일 토큰을 추출하고, 예술적 속성을 분리한 다음, 원하는 생성기에 붙여넣기만 하면 된다. 최상의 결과를 위해 대상 모델에 맞게 프롬프트 형식을 조정하라. Midjourney에는 추상적, FLUX에는 구체적, Stable Diffusion에는 태그 기반 형식을 사용하고, 출력 품질을 유지하기 위해 항상 네거티브 프롬프트를 포함하라.
FAQ
리버스 프롬프팅으로 다른 크리에이터가 사용한 원본 프롬프트를 정확히 복원할 수 있는가?
아니요. 시각적 분석을 기반으로 한 서술적 근사치를 재구성할 뿐이다. 서로 다른 VLM 모델은 서로 다른 속성을 우선시하므로, 출력은 고품질의 재구성이지 숨겨진 메타데이터나 키스트로크 복구가 아니다.
이미지-투-프롬프트 기술은 실제 스마트폰 사진에서도 작동하는가?
네. PromptsEra에 따르면, VLM은 “골든 아워 조명”이나 특정 카메라 렌즈 같은 실제 세계의 속성을 식별하고, 그 텍스처를 예술적 재해석을 위한 프롬프트로 변환할 수 있다.
저작권으로 보호되는 아트워크에서 추출한 프롬프트를 사용하는 것은 합법인가?
프롬프트는 짧은 텍스트 문자열이며 일반적으로 저작권의 적용을 받지 않는다. 윤리적인 접근 방식은 스타일 토큰을 추출하여 자신의 오리지널 작업에 활용하는 것이다. PromptsEra가 지적하듯이, 보호된 캐릭터를 정확히 복제하려고 시도하면 법적 문제가 발생할 수 있다. 이러한 도구는 기술을 배우기 위해 사용하고, 복사를 위해 사용해서는 안 된다.
답글 남기기