스프레드시트, CSV, 또는 JSON 파일을 깔끔한 마크다운 표로 바꾸고 싶으신가요? 2026년에는 이 과정이 아주 단순해졌습니다. 한 번의 일회성 변환인지, 아니면 대규모 문서를 자동화하려는 상황인지에 따라 적합한 도구가 달라집니다.
이 가이드에서는 각 상황에 가장 잘 맞는 도구들을 살펴봅니다. 수작업용 시각 편집기, 자동화용 CLI 도구, 그리고 문서를 코드베이스와 동기화하는 CI/CD 연동까지 모두 다룹니다.
한눈에 보는 주요 도구
| 도구 | 용도 | 유형 | 핵심 장점 |
|---|---|---|---|
| TableGenerator.com | 빠른 시각 편집 | 웹(클라이언트 사이드) | 그리드 기반 편집기, 정렬 제어 |
| AnywayData | 복잡한 JSON 파일 | 웹 / 라이브러리 | 중첩 구조 평탄화, AST 파싱 |
| MarkItDown (Microsoft) | 엑셀/워드 자동화 | Python CLI | 오피스 파일의 헤더와 표 그리드 보존 |
| Pandoc | 다중 포맷 변환 | CLI | 수십 가지 포맷 지원, 대규모에서도 안정적 |
| EaseCloud | 엑셀 → GFM | 웹 | 간단한 브라우저 기반 변환기 |
| GoConverter | 엑셀 → GFM | 웹 | 정렬 옵션을 포함한 빠른 변환 |
DasRoot (2026)에 따르면, 최신 마크다운 도구는 중간 규모 데이터셋을 기준으로 초당 15–30개 표 속도로 처리할 수 있으며, 우수한 도구들은 클라이언트 사이드 방식을 사용해 데이터가 브라우저를 떠나지 않도록 합니다.
GFM 호환성이 중요한 이유
GitHub Flavored Markdown (GFM) 은 GitHub, GitLab, Discord에서 사용하는 특정 방언입니다. 원래의 마크다운 사양은 표를 전혀 지원하지 않았으며, 익숙한 “파이프와 대시” 문법은 GFM이 추가한 것입니다. GFM을 준수하는 생성기를 사용하면 표가 굵은 헤더와 정렬된 열로 올바르게 렌더링되며, 원시 텍스트처럼 보이는 일을 방지할 수 있습니다.

엑셀과 CSV를 GFM으로 변환하는 방법
과정은 두 단계입니다.
- CSV로 내보내기 — 엑셀이나 구글 시트 파일을 CSV로 저장합니다. 이렇게 하면 무거운 서식은 제거되면서도 데이터 그리드는 보존됩니다.
- 변환 — EaseCloud나 GoConverter 같은 브라우저 기반 도구를 사용해 GFM 코드를 생성합니다.
열 정렬
GFM은 구분선 행(헤더 아래 줄)을 통해 정렬을 제어합니다.
| 문법 | 정렬 |
|---|---|
:--- |
왼쪽 정렬(기본값) |
---: |
오른쪽 정렬 |
:---: |
가운데 정렬 |
파이프 문자 이스케이프
마크다운은 |를 사용해 열 경계를 표시합니다. 데이터에 파이프가 포함되어 있으면(예: 코드 스니펫이나 수식) 표가 깨집니다. 다음 방법으로 이스케이프하세요.
- HTML 엔티티:
| - 백슬래시:
\| - 코드 백틱:
`|`
대용량 데이터셋 처리 (100+ rows)
행이 100개를 넘는 데이터셋에서는 웹 기반 시각 편집기가 버벅일 수 있습니다. 최신 변환기들은 점진적 파싱을 사용해 반응성을 유지합니다. AnywayData에 따르면, “쌍별 조합 데이터 로직”을 활용하면 필요한 테스트 케이스를 90–99% 까지 줄일 수 있으며, 이는 복잡한 설정을 문서화할 때 큰 도움이 됩니다.
진정으로 대규모인 데이터셋이라면 여러 표로 분할하거나, 마크다운 버전과 함께 다운로드 가능한 CSV 링크를 제공하는 것을 고려해 보세요.
JSON을 GFM으로 변환하기: 중첩 데이터 평탄화
JSON은 계층적입니다. 러시아 마트료시카처럼 데이터가 중첩되어 있죠. 반면 마크다운 표는 평면적인 2차원 그리드입니다. 변환에는 평탄화 로직이 필요합니다.
user.address.city → "User Address City" (단일 열 헤더)
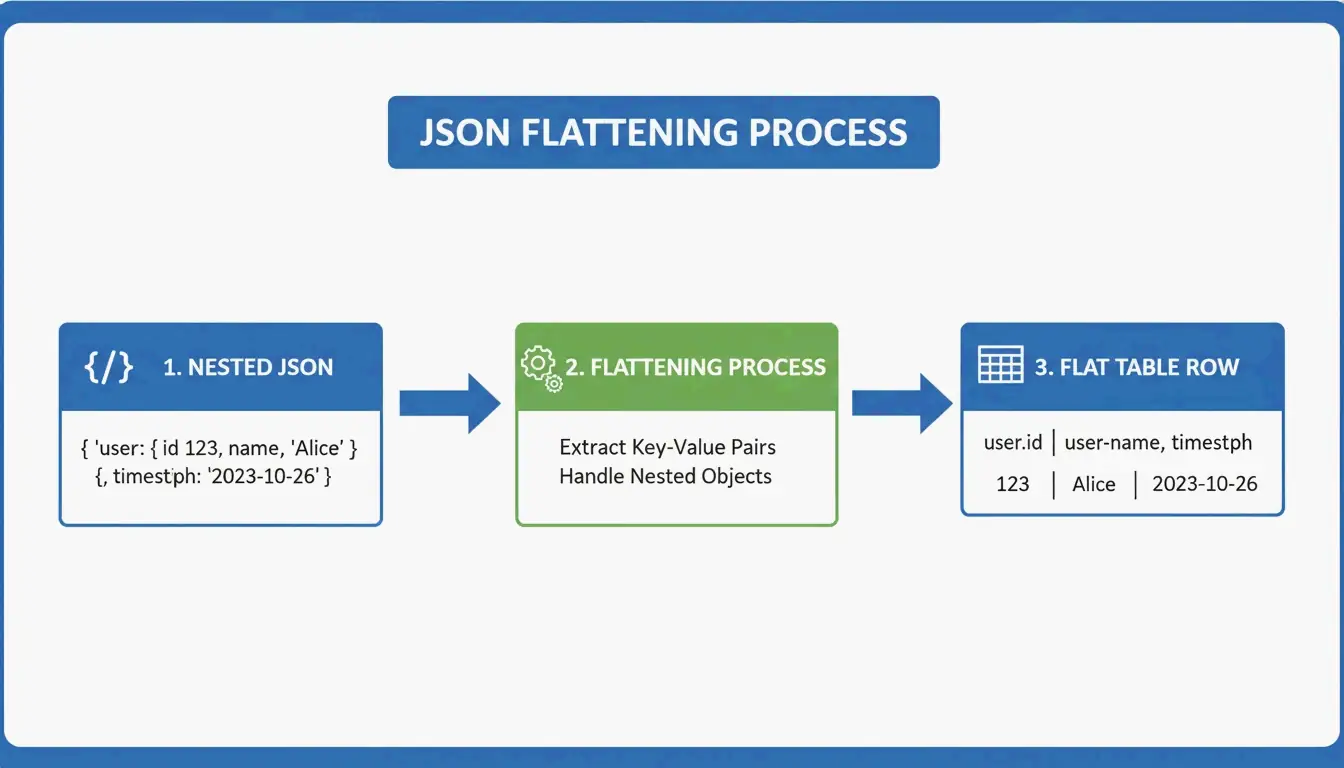
AnywayData 의 Grid Table Editor가 이 작업에 탁월합니다. JSON을 임포트하고 중첩 계층이 어떻게 평탄화될지 직접 제어할 수 있습니다. 변환의 품질은 도구가 단순한 텍스트 패턴 매칭이 아니라 AST (Abstract Syntax Tree) 구성을 사용하는지에 달려 있습니다. AST 기반 파서는 데이터 구조의 논리적 맵을 구축하므로 더 깊은 중첩과 일관성 없는 스키마도 훨씬 더 정확하게 처리합니다.
CI/CD로 자동화하기
엔지니어링 팀에게 수동 변환은 시간 낭비입니다. 표 생성을 CI/CD pipeline에 통합하면 README 파일이 자동으로 최신 상태를 유지합니다.
- 빌드 과정 중에 JSON API 응답을 GFM으로 변환
- 문서를 코드처럼 취급 — 데이터가 바뀌면 함께 업데이트
- 저장소에 오래되거나 잘못된 정보가 쌓이는 흔한 문제를 예방
Terraform-docs v0.17.0 (2026) 같은 도구는 리소스 표를 README 파일에 자동으로 주입합니다. 이는 인프라 수준의 문서화에서는 CLI 도구가 웹 인터페이스보다 종종 더 뛰어남을 보여줍니다.
MarkItDown vs. Pandoc: 어느 쪽을 써야 할까?
| 요소 | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| 최적화 대상 | 오피스 파일(엑셀, 워드) | 범용 문서 변환 |
| 마크다운 변종 | GFM 중심 | CommonMark, GFM 등 다수 |
| 적합한 경우 | 빠른 XLSX → GitHub 표 | 다중 포맷, 대용량 CLI 작업 |
| 최신 버전 | 2026 | 3.9.0.2 (안정) |
| 속도 | 단일 오피스 파일에서 더 빠름 | 배치 처리에 더 적합 |
| 사용 시점 | 엑셀 파일 하나를 변환할 때 | 수십 가지 포맷 간 변환이 필요할 때 |
대부분의 개발자에게 흔한 사례(엑셀 → GitHub 표)에서는 MarkItDown이 더 빠릅니다. 여러 문서 포맷을 다루거나 대규모 배치 변환을 실행할 때는 Pandoc이 더 나은 선택입니다.
결론
2026년에 데이터를 GFM 표로 변환하는 일은 결국 볼륨과 워크플로의 문제입니다.
- 일회성 편집 → 시각적 제어를 원하면 TableGenerator.com 또는 AnywayData
- 반복적인 오피스 변환 → Python 워크플로에 통합된 MarkItDown
- 다중 포맷 또는 대용량 → CLI 배치 처리를 위한 Pandoc
- 인프라 문서 → terraform-docs이나 커스텀 스크립트를 활용한 CI/CD 자동화
핵심 원칙은 이것입니다: 데이터가 업데이트될 때 문서도 업데이트되어야 합니다. 변환을 자동화하면 오래된 표를 방지하고 프로젝트의 문서를 신뢰할 수 있는 상태로 유지할 수 있습니다.
FAQ
마크다운 표 셀 안에서 파이프 문자(|)를 어떻게 이스케이프하나요?
리터럴 파이프 대신 HTML 엔티티 |를 사용하세요. 또는 사용 중인 GFM 파서가 지원한다면 백슬래시 이스케이프 \|를 쓰거나, 콘텐츠를 코드 백틱으로 감싸도 됩니다. 세 가지 방법 모두 파이프가 열 구분자로 해석되는 것을 막아줍니다.
GFM은 병합된 셀이나 여러 줄 콘텐츠를 지원하나요?
아니요. 표준 GFM은 colspan이나 rowspan을 지원하지 않습니다. 각 셀은 독립적이어야 합니다. 셀 내부에서 여러 줄 콘텐츠를 표현하려면 HTML <br> 태그를 사용해 줄바꿈을 강제하면서 데이터는 단일 행에 유지하세요.
100행이 넘는 데이터셋에는 어떤 접근법이 가장 좋나요?
웹 기반 시각 편집기는 건너뛰세요(버벅일 겁니다). 대신 MarkItDown이나 Pandoc 같은 CLI 도구를 사용하세요. 결과 표가 단일 페이지에 넣기엔 너무 크다면, 가독성을 유지하기 위해 여러 표로 분할하거나 다운로드 가능한 CSV 파일 링크를 제공하세요.
답글 남기기