スプレッドシート、CSV、JSONファイルをきれいな Markdown テーブルに変換したい場合、2026年ではプロセスは至ってシンプルです。適切なツールは、単発の変換なのか、ドキュメントを大規模に自動化するのかによって変わります。
本ガイドでは、各シナリオに最適なツールを取り上げます。手作業向けのビジュアルエディタ、自動化向けの CLI ツール、そしてドキュメントをコードベースと同期させ続けるための CI/CD 連携まで網羅します。
主要ツール早見表
| ツール | 最適な用途 | タイプ | 主な強み |
|---|---|---|---|
| TableGenerator.com | クイックなビジュアル編集 | Web(クライアントサイド) | グリッドベースの編集、配置制御 |
| AnywayData | 複雑な JSON ファイル | Web / ライブラリ | ネスト構造のフラット化、AST パース |
| MarkItDown (Microsoft) | Excel/Word の自動化 | Python CLI | Office ファイルのヘッダーと表グリッドを保持 |
| Pandoc | 多フォーマット変換 | CLI | 数十種類のフォーマットをサポート、大規模でも安定 |
| EaseCloud | Excel → GFM | Web | シンプルなブラウザベースのコンバータ |
| GoConverter | Excel → GFM | Web | 配置オプション付きの高速変換 |
DasRoot (2026) によれば、モダンな Markdown ツールは中規模データセットで 15–30 テーブル/秒 を処理でき、優れたツールは クライアントサイド処理 を採用しているため、データがブラウザから外に漏れることはありません。
GFM 準拠が重要な理由
GitHub Flavored Markdown (GFM) は、GitHub、GitLab、Discord で使われている特定の方言です。オリジナルの Markdown 仕様ではテーブル自体がサポートされておらず、GFM がおなじみの「パイプとダッシュ」構文を追加しました。GFM 準拠のジェネレータを使えば、テーブルが生テキストとして表示されるのではなく、太字のヘッダーと整列したカラムで正しくレンダリングされます。

Excel と CSV を GFM に変換する方法
プロセスは 2 ステップです。
- CSV にエクスポート — Excel や Google Sheets のファイルを CSV として保存します。これで重い書式が削ぎ落とされ、データグリッドだけが残ります。
- 変換 — EaseCloud や GoConverter のようなブラウザベースのツールを使って GFM コードを生成します。
カラムの配置
GFM ではセパレータ行(ヘッダーの下の行)で配置を制御します。
| 構文 | 配置 |
|---|---|
:--- |
左寄せ(デフォルト) |
---: |
右寄せ |
:---: |
中央寄せ |
パイプ文字のエスケープ
Markdown では | を使ってカラムの境界を示します。もしデータの中にパイプが含まれていると(コードスニペットや数式など)、テーブルが壊れてしまいます。次の方法でエスケープしてください。
- HTML 実体参照:
| - バックスラッシュ:
\| - コードバッククォート:
`|`
大規模データセットの扱い(100+ rows)
100 行を超えるデータセットでは、Web ベースのビジュアルエディタが遅くなることがあります。モダンなコンバータは インクリメンタルパース を使って応答性を維持します。AnywayData によれば、「ペアワイズの組み合わせデータロジック」を使うことで必要なテストケースを 90–99% 削減でき、複雑な設定をドキュメント化する際に役立ちます。
本当に大規模なデータセットでは、複数のテーブルに分割するか、Markdown 版と一緒にダウンロード可能な CSV リンクを併記することを検討してください。
JSON を GFM に変換:ネストされたデータのフラット化
JSON は階層構造で、マトリョーシカのようにネストされたデータです。一方 Markdown テーブルはフラットな 2 次元グリッドです。変換には フラット化ロジック が必要です。
user.address.city → "User Address City" (single column header)
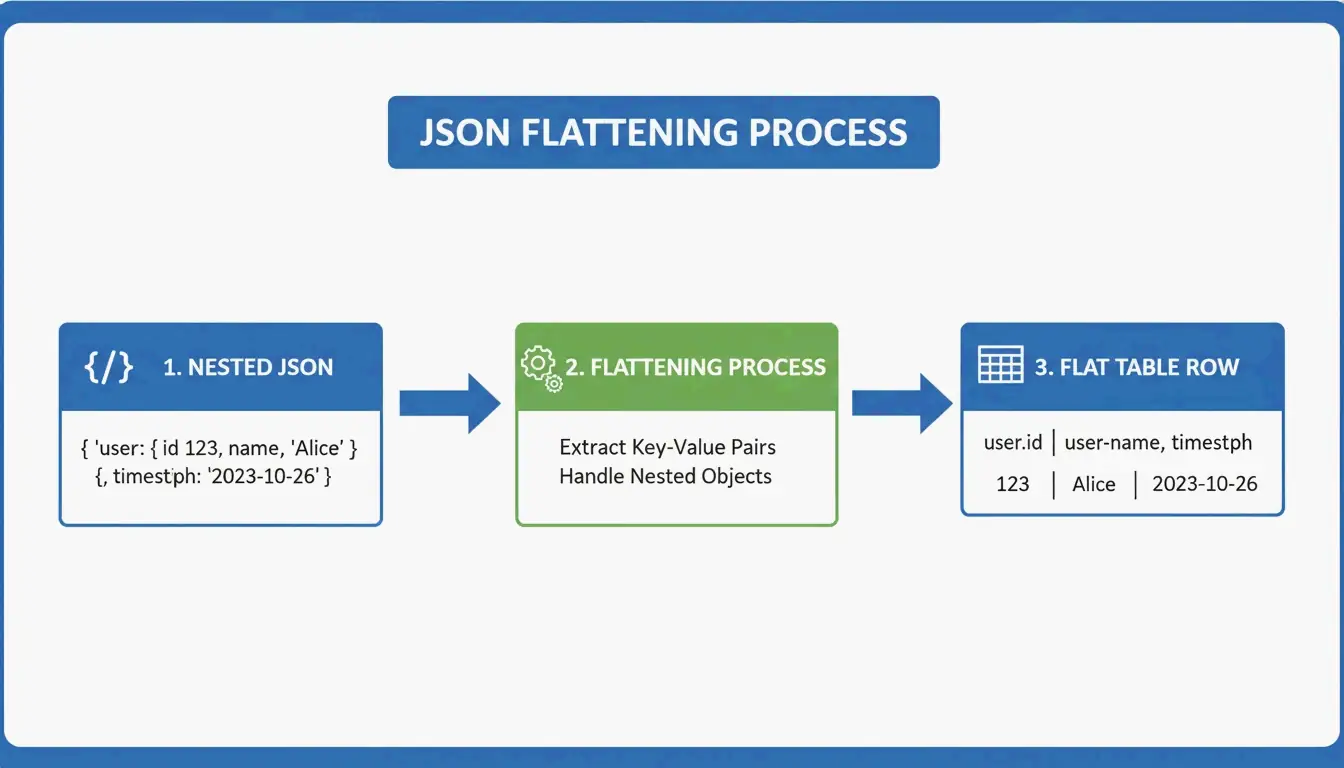
AnywayData ’s Grid Table Editor はここで本領を発揮します。JSON をインポートし、ネストされたレイヤーをどのようにフラット化するかを手動で制御できます。変換の品質は、単純なテキストパターンマッチングではなく、AST (Abstract Syntax Tree) 構築を使っているかどうかにかかっています。AST ベースのパーサはデータ構造の論理マップを構築するため、より深いネストや一貫性のないスキーマをはるかに正確に処理できます。
CI/CD で自動化
エンジニアリングチームにとって、手動変換は時間の無駄です。CI/CD pipeline にテーブル生成を組み込めば、README ファイルが自動的に最新に保たれます。
- ビルドプロセス中に JSON API レスポンスを GFM に変換
- ドキュメントをコードとして扱う — データが変われば更新される
- リポジトリで情報が古くなったり誤ったりするよくある問題を防止
Terraform-docs v0.17.0 (2026) のようなツールは、リソーステーブルを README ファイルに直接自動挿入します。これは、インフラレベルのドキュメントにおいて CLI ツールが Web インターフェースより優れることを示しています。
MarkItDown vs. Pandoc:どちらを使うべきか
| 項目 | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| 最適化対象 | Office ファイル(Excel、Word) | 汎用ドキュメント変換 |
| Markdown フレーバー | GFM 重視 | CommonMark、GFM、その他多数 |
| 適している用途 | クイックな XLSX → GitHub テーブル | 多フォーマット・大量の CLI 作業 |
| 最新バージョン | 2026 | 3.9.0.2(安定版) |
| 速度 | 単一の Office ファイルなら高速 | バッチ処理に優れる |
| 使うべき場面 | Excel ファイル 1 つを変換したい時 | 数十種類のフォーマット間で変換したい時 |
ほとんどの開発者にとって、MarkItDown は一般的なケース(Excel → GitHub テーブル)でより高速です。多くのドキュメントフォーマットを扱う場合や、大規模なバッチ変換を実行する場合は、Pandoc がより良い選択肢です。
まとめ
2026 年にデータを GFM テーブルに変換するのは、量とワークフロー次第です。
- 単発の編集 → ビジュアル制御なら TableGenerator.com か AnywayData
- 繰り返しの Office 変換 → Python ワークフローに統合した MarkItDown
- 多フォーマット・大量処理 → CLI バッチ処理なら Pandoc
- インフラドキュメント → terraform-docs やカスタムスクリプトによる CI/CD 自動化
重要な原則は、データが更新されたらドキュメントも更新されるべき ということです。変換を自動化すれば古いテーブルを防ぎ、プロジェクトのドキュメントを信頼できるものに保てます。
FAQ
Markdown テーブルのセル内でパイプ文字 (|) をエスケープするには?
リテラルのパイプの代わりに HTML 実体参照 | を使います。GFM パーサが対応していればバックスラッシュエスケープ \| を使うか、コンテンツをコードバッククォートで囲みます。3 つの方法すべて、パイプがカラムセパレータとして解釈されるのを防げます。
GFM は結合セルや複数行のコンテンツをサポートしていますか?
いいえ。 標準の GFM は colspan や rowspan をサポートしていません。各セルは独立していなければなりません。セル内で複数行のコンテンツを使いたい場合は、HTML の <br> タグを使って改行を強制しつつ、データを 1 行に収めてください。
100 行を超えるデータセットにはどう対応すべきですか?
Web ベースのビジュアルエディタは避けてください(遅延します)。代わりに MarkItDown や Pandoc のような CLI tools を使います。結果のテーブルが 1 ページに収まらないほど大きい場合は、読みやすさを保つため複数のテーブルに分割するか、ダウンロード可能な CSV ファイルへのリンクを提示してください。
コメントを残す