
Si trabajas con códigos de barras —ya sea en logística, salud, manufactura o retail— probablemente te has topado tanto con Code 128 como con Code 39. Son dos de los formatos de código de barras 1D más comunes, y en 2026 la elección entre ambos se reduce a cuántos datos necesitas codificar y cuánto espacio tienes en la etiqueta.
Code 128 es el estándar moderno: alta densidad, soporte completo de ASCII y un dígito de control obligatorio. Code 39 es la alternativa más antigua y sencilla, que funciona bien con cadenas cortas pero se vuelve poco manejable con datos más largos. Esta guía desglosa las diferencias y te ayuda a elegir el correcto.
Code 128 vs Code 39 de un vistazo
| Característica | Code 128 | Code 39 |
|---|---|---|
| Densidad de datos | Alta — cabe más información en menos espacio | Baja — se ensancha rápido |
| Conjunto de caracteres | Los 128 caracteres ASCII completos | 43 caracteres (mayúsculas, dígitos, pocos símbolos) |
| Soporte de minúsculas | Nativo | Solo mediante el modo «Extended» (duplica la longitud del código) |
| Dígito de control | Obligatorio (Modulo 103) | Opcional |
| Anchos de barra/espacio | 4 anchos (1, 2, 3, 4 unidades) | 2 anchos (estrecho y ancho) |
| Ideal para | Logística, envíos, datos complejos | Seguimiento interno simple, sistemas heredados |
La diferencia en el espacio físico es notable. Según Peak Technologies, deberías cambiar de Code 39 a Code 128 si tu cadena de datos es más larga de 15 caracteres. Un ID de 20 caracteres en Code 39 podría no caber en una etiqueta estándar de 2 pulgadas, mientras que Code 128 lo mantiene compacto.

Los escáneres modernos (cámaras de área y apps para smartphone) leen ambos formatos con facilidad. Pero Code 128 tiene ventaja en confiabilidad porque su detección de errores integrada evita lecturas erróneas en entornos de alto volumen.
Densidad de datos: por qué importa
La densidad de datos es cuántos caracteres caben en una pulgada de código de barras. Wikipedia explica que Code 128 usa cuatro anchos diferentes para barras y espacios, mientras que Code 39 solo usa dos. Esta precisión hace que Code 128 sea aproximadamente el doble de denso para datos numéricos —a menudo el único código de barras 1D que funciona en artículos pequeños como viales médicos o dispositivos electrónicos diminutos.
Soporte de caracteres
- Code 39 (estándar): 43 caracteres — letras mayúsculas A–Z, dígitos 0–9 y un puñado de símbolos (-, ., $, /, +, %, espacio).
- Code 128: los 128 caracteres ASCII completos — mayúsculas, minúsculas, símbolos e incluso caracteres de control como retornos de carro.
- Code 39 Extended: puede codificar minúsculas mediante pares de caracteres (por ejemplo, «+A» para la minúscula «a»), pero como señala Peak Technologies, esto es «un desperdicio de espacio» y alarga innecesariamente el código de barras.
Por qué Code 128 es el estándar logístico moderno
Code 128 impulsa el envío global a través del estándar GS1-128, que usa «Application Identifiers» (identificadores de aplicación) para estructurar datos como números de lote, fechas de caducidad y números de serie.
Dígito de control obligatorio (Modulo 103)
En Code 39, el checksum es opcional. En Code 128, es integrado: el código de barras añade un valor calculado que el escáner verifica en cada lectura. Esto elimina prácticamente el riesgo de una lectura «errónea» en almacenes concurridos.
Optimización mediante los Code Sets A, B y C
Code 128 se mantiene compacto alternando entre tres modos internos:
| Code Set | Optimizado para | Ventaja clave |
|---|---|---|
| A | Letras mayúsculas + códigos de control | Aplicaciones industriales |
| B | Alfanumérico estándar + minúsculas | Texto de propósito general |
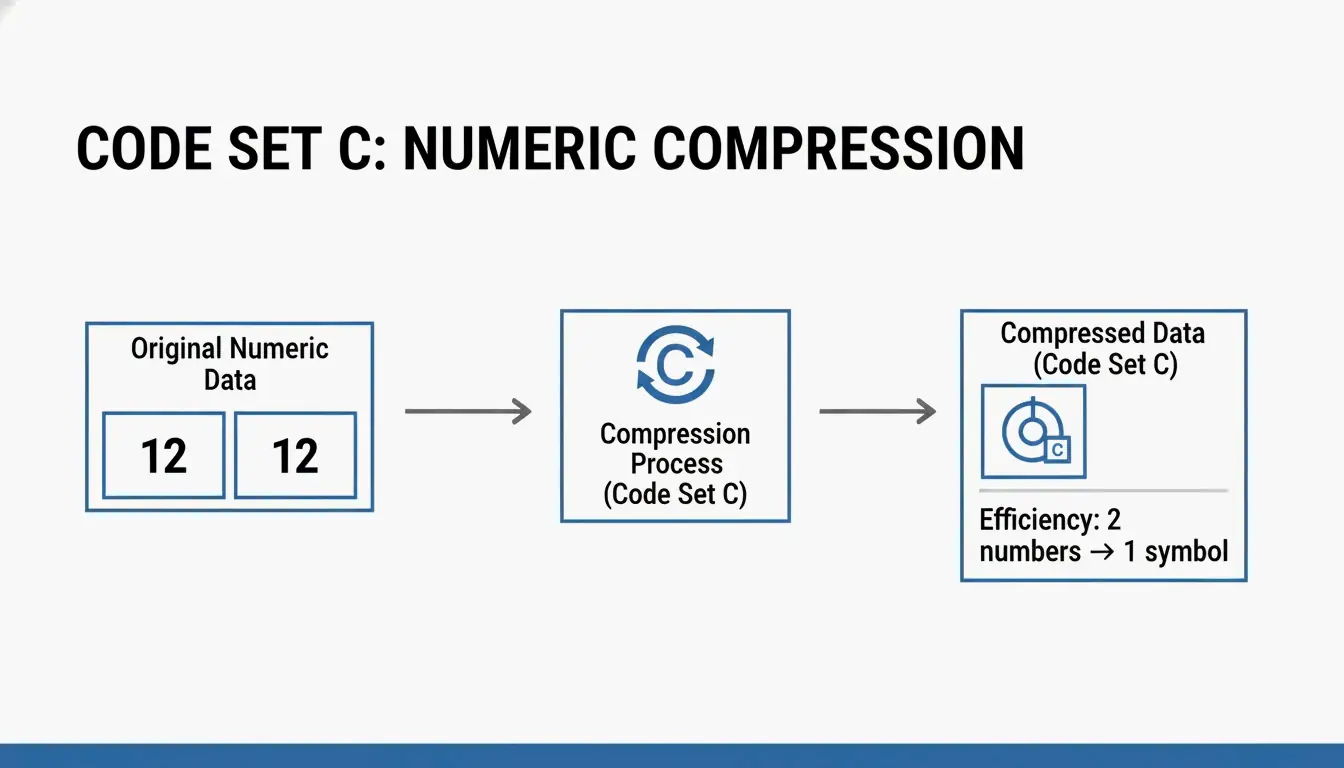
| C | Solo datos numéricos | Dos dígitos por símbolo — el más eficiente para números |
Wikipedia explica que el Code Set C agrupa dos dígitos en un solo símbolo de código de barras. Para cadenas numéricas largas, esto es increíblemente eficiente. La investigación de Steven Skiena muestra que una selección inteligente del Code Set puede hacer un código de barras 8% más pequeño en promedio que usando un ajuste estático.
¿Sigue siendo relevante Code 39?
Code 39 todavía tiene cabida en 2026 porque es simple y tolerante. Es «autoverificable» — los huecos entre caracteres ayudan a aislar errores —, lo que hace que funcione bien con impresoras de baja resolución o escáneres industriales antiguos.
Todavía encontrarás Code 39 en:
– Departamento de Defensa de EE. UU. (estándar LOGMARS)
– Seguimiento interno en Salud
– Sistemas heredados de la industria automotriz
El problema surge con Code 39 Extended. Codificar una sola «a» minúscula requiere imprimir «+A» — duplicando la longitud del código de barras. Si tus IDs de seguimiento usan letras en mayúsculas y minúsculas combinadas, Code 39 Extended es una mala opción.
Especificaciones técnicas: X-dimension y zonas en blanco
La calidad con la que un código de barras se escanea depende de la X-dimension — el ancho de la barra más estrecha. Según los estándares GS1 2026, la X-dimension mínima para puntos de venta minorista es de 0.264 mm (0.0104 inches).
Ambos formatos también necesitan una Quiet Zone (zona en blanco) — espacio blanco a ambos extremos del código de barras, de al menos 10× el ancho de la barra más estrecha. Sin ella, los escáneres no pueden determinar dónde empieza y dónde termina el código.
Compatibilidad con escáneres
| Tipo de escáner | Funciona mejor con | Notas |
|---|---|---|
| Escáneres láser | Códigos de barras más largos y altos | Necesitan una trayectoria láser clara a través de todas las barras |
| Cámaras de área (estándar 2026) | Ambos formatos, incluido Code 128 de alta densidad | Pueden leer etiquetas dañadas o inclinadas |
| Cámaras de smartphone | Ambos | Soporte nativo en iOS/Android |
Según Gitnux 2024, el sector retail maneja el 42% de las lecturas diarias globales — por eso la industria avanza hacia estándares de imagen de área más confiables.
Conclusión
Code 39 está bien para IDs internos simples y cortos —especialmente en sistemas heredados con escáneres antiguos. Code 128 es la opción clara para todo lo demás: es más pequeño, soporta más caracteres, incluye verificación de errores obligatoria y es la columna vertebral de la logística moderna.
Regla de decisión:
– Datos más cortos de 10–15 caracteres, solo mayúsculas → Code 39 es aceptable
– Cualquier cosa más larga, o con mayúsculas/minúsculas mixtas / símbolos → Code 128
– Se requiere cumplimiento GS1-128 → Code 128 (no hay otra opción)
Al diseñar etiquetas, asegúrate de que tu barra más estrecha cumpla el estándar GS1 de 0.264 mm para garantizar la legibilidad en todo el mundo.
Preguntas frecuentes
¿Puede Code 39 codificar letras minúsculas?
El Code 39 estándar solo admite letras mayúsculas, dígitos y unos pocos símbolos. Para codificar minúsculas necesitas Code 39 Extended, que usa pares de caracteres (por ejemplo, «+A» para «a»). Esto aumenta significativamente la longitud física del código de barras, haciéndolo mucho menos eficiente que Code 128.
¿Por qué Code 128 es más «denso» que Code 39?
Code 128 usa cuatro anchos de barra/espacio (frente a los dos de Code 39) y su Code Set C codifica dos dígitos por símbolo. Esto hace que Code 128 sea aproximadamente el doble de denso que Code 39 para datos numéricos, ahorrando valioso espacio en la etiqueta.
¿Necesito un dígito de control para los códigos de barras Code 39?
Es opcional para Code 39, aunque se recomienda en entornos críticos. Code 128 lleva un checksum Modulo 103 obligatorio integrado en su especificación, lo que lo hace inherentemente más confiable para escaneo de alto volumen.
¿Qué tipo de código de barras es mejor para artículos pequeños con espacio de etiqueta limitado?
Code 128: su mayor densidad permite imprimirlo con una X-dimension mayor (más fácil de leer para los escáneres) dentro del mismo espacio físico donde un código Code 39 quedaría apretado y difícil de escanear.
Deja una respuesta