
প্রতিটি আধুনিক ডেটাবেস, বিতরণকৃত সিস্টেম এবং API অদ্বিতীয় শনাক্তকারী (unique identifier) ব্যবহার করে — এবং ২০২৬ সালে, সেগুলিকে নিয়ন্ত্রণকারী মান মৌলিকভাবে পরিবর্তিত হয়েছে। UUID (Universally Unique Identifier, সার্বজনীন অদ্বিতীয় শনাক্তকারী) হলো একটি ১২৮-বিট লেবেল যা কোনো কেন্দ্রীয় সমন্বয় ছাড়াই কম্পিউটার সিস্টেম জুড়ে তথ্য শনাক্ত করতে পারে। নতুন RFC 9562 (যা ২০২৪ সালের মে মাসে RFC 4122 কে প্রতিস্থাপন করেছে)-এর অধীনে, দৃশ্যপট পরিবর্তিত হয়েছে: UUID v4 এখনও এলোমেলো IDs-এর জন্য পছন্দের, কিন্তু UUID v7 এখন ডেটাবেস প্রাথমিক কীগুলির জন্য সুপারিশকৃত মান, কারণ এর সময়-ক্রমিত কাঠামো B-ট্রি ইনডেক্স খণ্ডায়ন রোধ করে।
এই গাইডটি সম্পূর্ণ চিত্র কভার করে: UUID কীভাবে কাজ করে, কোন সংস্করণ কখন ব্যবহার করবেন এবং কীভাবে সেগুলি সঠিকভাবে বাস্তবায়ন করবেন।
RFC 9562 বোঝা: আধুনিক UUID মান
UUID হলো একটি ১২৮-বিট সংখ্যা যার অদ্বিতীয়তা ব্যবহারিকভাবে গ্যারান্টিযুক্ত — কোনো কেন্দ্রীয় কর্তৃপক্ষের প্রয়োজন নেই। উইকিপিডিয়া অনুসারে, দুটি UUID-এর সংঘর্ষের সম্ভাবনা এতই শূন্যের কাছাকাছি যে বাস্তব অ্যাপ্লিকেশনের জন্য অসম্ভব বলে বিবেচিত। বিভিন্ন দল স্বাধীনভাবে ডেটা লেবেল করতে পারে, এই বিশ্বাসে যে তাদের IDs সংঘর্ষ করবে না।
২০২৪ সালের মে মাসে, IETF RFC 9562 প্রকাশ করে, পুরোনো RFC 4122 কে অবসর দেয়। আপডেটটি আধুনিক বিতরণকৃত সিস্টেমগুলির দাবিগুলির প্রতিক্রিয়া ছিল, যেগুলি এমন IDs প্রয়োজন ছিল যা অদ্বিতীয় এবং সময় অনুসারে সাজানো যায়। তিনটি নতুন সংস্করণ চালু করা হয়েছিল: v6, v7 এবং v8।
UUID-এর গঠন: সংস্করণ এবং ভ্যারিয়েন্ট
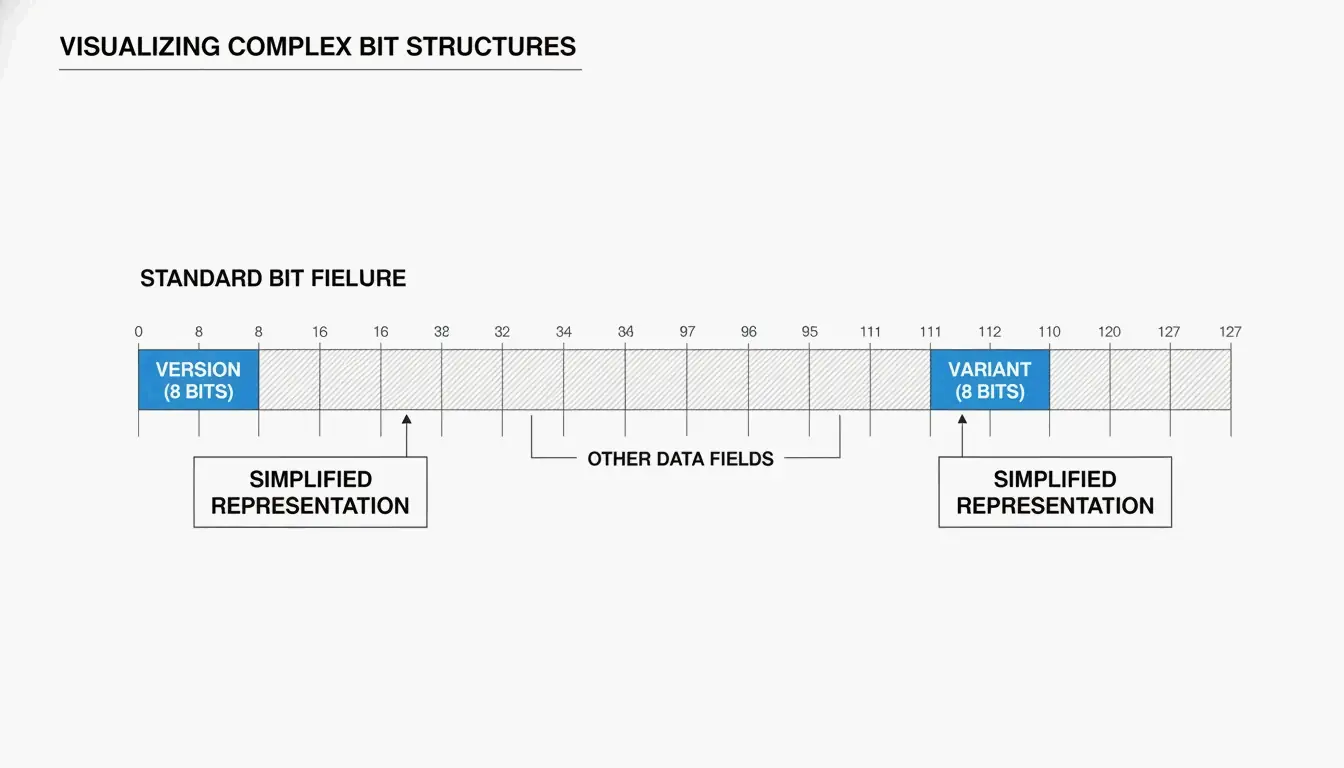
আপনি সাধারণত UUID কে ৩২টি হেক্সাডেসিমাল অক্ষর হিসাবে দেখবেন যা হাইফেন দ্বারা পাঁচটি দলে বিভক্ত (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
দুটি মূল ক্ষেত্র আপনাকে জানায় UUID কীভাবে তৈরি হয়েছিল:
| ক্ষেত্র | অবস্থান | এটি যা জানায় |
|---|---|---|
| সংস্করণ বিট | ৭ম বাইটের প্রথম ৪টি বিট (৩য় দলের প্রথম অক্ষর) | কোন অ্যালগরিদম ব্যবহার হয়েছিল (যেমন “4” = v4, “7” = v7) |
| ভ্যারিয়েন্ট বিট | ৯ম বাইট | UUID ভ্যারিয়েন্ট — RFC 9562 একটি 10 বিট প্যাটার্ন ব্যবহার করে |
যেমন SnapUtils ব্যাখ্যা করে, ভ্যারিয়েন্ট বিটগুলি আধুনিক RFC 9562 UUID কে পুরোনো Apollo বা Microsoft ফরম্যাট থেকে আলাদা করে।
UUID v7 ডেটাবেসের জন্য নতুন স্বর্ণ মান কেন
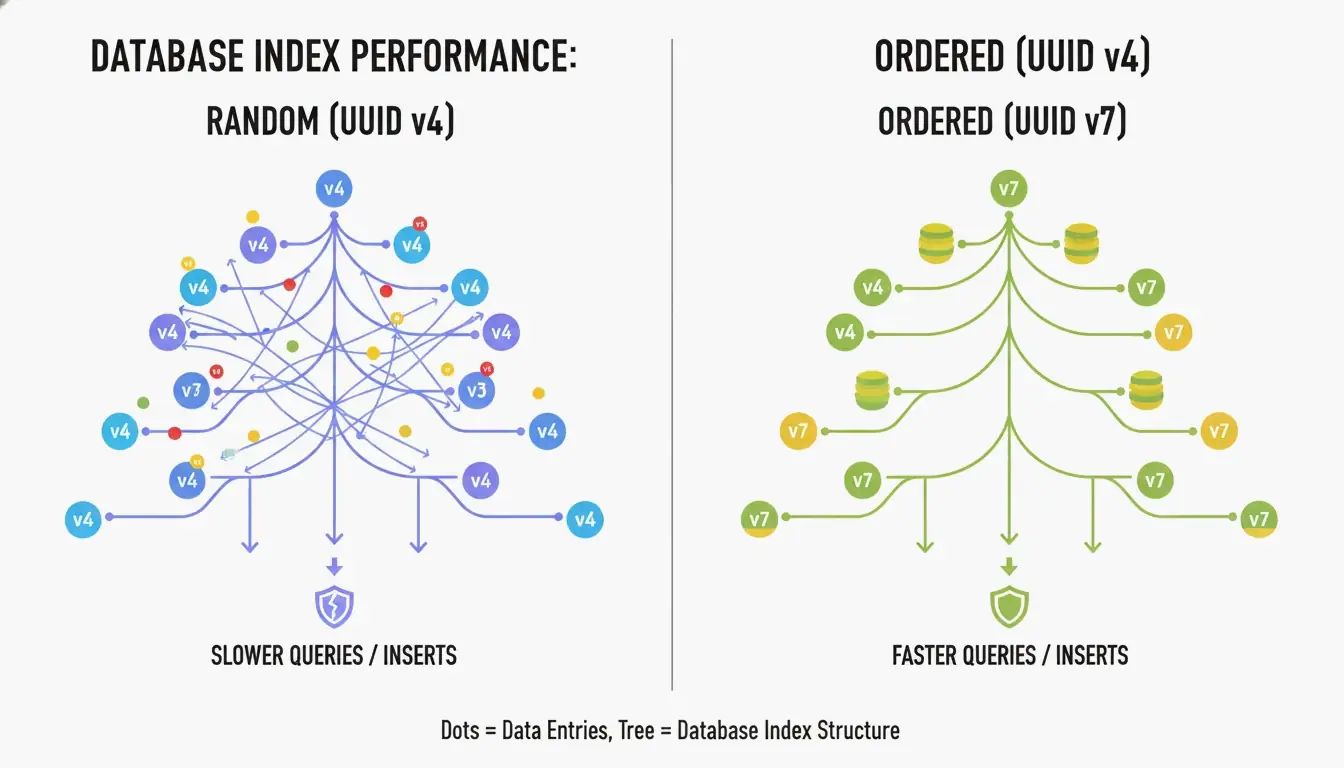
UUID v4-এর সবচেয়ে বড় অসুবিধা হলো এটি সম্পূর্ণ এলোমেলো। যখন B-ট্রি ইনডেক্সে প্রাথমিক কী হিসাবে ব্যবহৃত হয়, তখন ডেটাবেসকে অপ্রত্যাশিত অবস্থানে নতুন সারি সন্নিবেশ করতে হয়। CreateUUID অনুসারে, এটি “পেজ বিভাজন” (page splits) সৃষ্টি করে — ডেটাবেসকে জায়গা তৈরির জন্য ক্রমাগত ডেটা পুনর্গঠন করতে হয়, যার ফলে লেখা ধীর হয় এবং মেমরি নষ্ট হয়।
UUID v7 এটি ID-এর শুরুতে একটি ৪৮-বিট Unix Epoch টাইমস্ট্যাম্প (মিলিসেকেন্ড নির্ভুলতা) স্থাপন করে সমাধান করে। এটি IDs কে এককভাবে বর্ধমান করে তোলে — নতুনগুলি সর্বদা পুরোনোগুলির চেয়ে বড়। ডেটাবেস কেবল ইনডেক্সের শেষে যুক্ত করতে পারে, আপনাকে একটি ক্রমিক পূর্ণসংখ্যার কর্মক্ষমতা UUID-এর বিশ্বব্যাপী অদ্বিতীয়তার সাথে দেয়।
UUID v7 কীভাবে সময় ও এনট্রপির ভারসাম্য রক্ষা করে
UUID v7 অবশিষ্ট ৭৪ বিট একটি CSPRNG (ক্রিপ্টোগ্রাফিক্যালি সিকিউর সিউডো-র্যান্ডম নম্বর জেনারেটর) দিয়ে পূরণ করে। উইকিপিডিয়া অনুসারে, আপনাকে ৫০% সংঘর্ষ সম্ভাবনায় পৌঁছাতে প্রতি সেকেন্ডে প্রায় ১ বিলিয়ন UUID ৮৫ বছর ধরে তৈরি করতে হবে। যেকোনো বাস্তব অ্যাপ্লিকেশনের জন্য, UUID v7 কার্যত সংঘর্ষ-প্রতিরোধী।
সংরক্ষণের সেরা অনুশীলন: Binary(16) বনাম String(36)
আপনি UUID কীভাবে সংরক্ষণ করেন তা আপনি কোন সংস্করণ ব্যবহার করেন ততটাই গুরুত্বপূর্ণ:
| সংরক্ষণ ফরম্যাট | স্থান | ইনডেক্স কর্মক্ষমতা | সুপারিশ |
|---|---|---|---|
| Binary(16) | ১৬ বাইট | উচ্চ (কম্প্যাক্ট) | সেরা অনুশীলন |
| নেটিভ UUID প্রকার | ১৬ বাইট | উচ্চ (অপ্টিমাইজড) | PostgreSQL-এর জন্য সেরা |
| স্ট্রিং (Char 36) | ৩৬–৭২ বাইট | নিম্ন (খণ্ডিত) | এড়িয়ে চলুন |
SnapUtils সর্বদা স্ট্রিংয়ের পরিবর্তে নেটিভ প্রকার ব্যবহারের সুপারিশ করে। PostgreSQL-এ, নেটিভ uuid প্রকার ডেটা একটি কম্প্যাক্ট ১৬-বাইট বাইনারি ফরম্যাটে সংরক্ষণ করে যখন এখনও স্ট্যান্ডার্ড স্ট্রিং-ভিত্তিক ক্যোয়ারি সমর্থন করে।
UUID বনাম GUID: কোনো পার্থক্য আছে কি?
GUID (Globally Unique Identifier, বিশ্বব্যাপী অদ্বিতীয় শনাক্তকারী) হলো UUID মানের Microsoft-এর বাস্তবায়ন। ঐতিহাসিকভাবে, বাইট ক্রমে (endianness) একটি পার্থক্য ছিল — প্রারম্ভিক Microsoft GUID-গুলি প্রথম তিনটি ক্ষেত্রের জন্য little-endian ব্যবহার করত, যেখানে স্ট্যান্ডার্ড UUID big-endian (নেটওয়ার্ক বাইট ক্রম) ব্যবহার করত (SnapUtils)।
২০২৬ সালের মধ্যে, এটি বেশিরভাগই একটি নামকরণের রীতি। RFC 9562-এর অধীনে, এগুলি অভিন্নভাবে কাজ করে। .NET-এ Guid.NewGuid() Python-এ uuid.uuid4()-এর সাথে সম্পূর্ণ সামঞ্জস্যপূর্ণ। আপনি Windows/Azure মহলে “GUID” এবং Linux এবং ওপেন-সোর্স কমিউনিটিতে “UUID” শুনবেন।
আধুনিক UUID বাস্তবায়ন: ভাষা অনুযায়ী
| ভাষা | UUID v4 | UUID v7 |
|---|---|---|
| Python | অন্তর্নির্মিত uuid মডিউল |
uuid6 বা uuid7 প্যাকেজ |
| JavaScript | crypto.randomUUID() |
uuid npm প্যাকেজ (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
নেটিভ uuidv7() (PG 17+) বা এক্সটেনশন |
| .NET | Guid.NewGuid() |
কমিউনিটি প্যাকেজ |
| Rust | uuid ক্রেট (v1.7+) |
v7 ফিচারসহ uuid ক্রেট |
নির্ধারণমূলক IDs: UUID v5
আপনি যদি একটি নির্দিষ্ট ইনপুটের (যেমন URL বা ব্যবহারকারীর নাম) জন্য প্রতিবার একই ID প্রয়োজন হয়, তবে UUID v5 ব্যবহার করুন। এটি একটি নেমস্পেস UUID এবং একটি নাম স্ট্রিংকে SHA-1 দিয়ে হ্যাশ করে — যখন আপনি একটি কেন্দ্রীয় ডেটাবেস চেক করতে পারবেন না তখন ডিডুপ্লিকেশনের জন্য নিখুঁত।
UUID v1-এর গোপনীয়তার শিক্ষা
UUID v1 একটি টাইমস্ট্যাম্প এবং কম্পিউটারের MAC ঠিকানা ব্যবহার করে। এটি ব্যাপকভাবে পরিত্যক্ত হয়েছে কারণ এটি হার্ডওয়্যার তথ্য ফাঁস করে। একটি বিখ্যাত উদাহরণ: মেলিসা ভাইরাস নির্মাতা ধরা পড়েছিল কারণ সংক্রমিত Word নথিতে UUID-গুলিতে তার নির্দিষ্ট MAC ঠিকানা ছিল।
উন্নত RFC 9562: v6, v8 এবং বিশেষ UUID
RFC 9562 বিতরণকৃত সিস্টেমের সূক্ষ্ম প্রয়োজনের জন্য বিশেষায়িত সংস্করণ যোগ করেছে:
| সংস্করণ | উদ্দেশ্য | কখন ব্যবহার করবেন |
|---|---|---|
| v6 | পুনর্বিন্যাস্ত v1 টাইমস্ট্যাম্প — v1-এর নির্ভুলতা রেখে সাজানো যায় | লিগেসি v1 সিস্টেম মাইগ্রেশন |
| v8 | কাস্টম — ডেভেলপার-নির্ধারিত ডেটার জন্য ১২২ বিট | পরীক্ষামূলক বা বিক্রেতা-নির্দিষ্ট স্কিম |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
নাল প্লেসহোল্ডার |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
পরিসর প্রান্তিক মার্কার |
উপসংহার
RFC 9562 আধুনিক ক্লাউড যুগের জন্য অদ্বিতীয় শনাক্তকারী আপডেট করেছে। ব্যবহারিক নির্দেশিকা:
- ডেটাবেস প্রাথমিক কী → সময়-ক্রমিত, খণ্ডায়ন-মুক্ত সন্নিবেশের জন্য UUID v7 ব্যবহার করুন
- সাধারণ এলোমেলোতা → UUID v4 এখনও সম্পূর্ণ ঠিক
- ডিডুপ্লিকেশন → UUID v5 আপনাকে নির্ধারণমূলক IDs দেয়
- সংরক্ষণ → সর্বদা Binary(16) বা নেটিভ UUID প্রকার ব্যবহার করুন, কখনো স্ট্রিং নয়
করণীয়: আপনার ডেটাবেস স্কিমা পরীক্ষা করুন। আপনি যদি লক্ষ লক্ষ সারির টেবিলে প্রাথমিক কী হিসাবে UUID v4 ব্যবহার করেন, তবে UUID v7-এ মাইগ্রেট করা একটি সহজ পরিবর্তন যা ইনডেক্স খণ্ডায়ন উল্লেখযোগ্যভাবে কমাতে এবং ক্যোয়ারি দ্রুত করতে পারে।
প্রায়শই জিজ্ঞাসিত প্রশ্নাবলি
UUID কি GUID-এর মতোই?
কার্যকরীভাবে, হ্যাঁ। GUID হলো UUID মানের Microsoft-এর বাস্তবায়ন। RFC 9562-এর অধীনে, এগুলি আচরণে অভিন্ন — আপনি এগুলি .NET, Java এবং Python অ্যাপ্লিকেশন জুড়ে পরস্পর ব্যবহার করতে পারেন।
বাস্তব পরিস্থিতিতে দুটি UUID কি কখনো সংঘর্ষ করতে পারে?
গাণিতিকভাবে সম্ভব, ব্যবহারিকভাবে অসম্ভব। UUID v4-এর জন্য, আপনাকে ৫০% সংঘর্ষ সম্ভাবনায় পৌঁছাতে প্রায় ২.৭১ কুইন্টিলিয়ন IDs তৈরি করতে হবে। Generate-Random.org অনুসারে, ৮৫ বছর ধরে প্রতি সেকেন্ডে ১ বিলিয়ন UUID তৈরি করলে আপনার একটি মাত্র সংঘর্ষের মাত্র ৫০% সুযোগ থাকে।
আমার ডেটাবেসে UUID কি স্ট্রিং বা বাইনারি হিসাবে সংরক্ষণ করব?
সর্বদা Binary(16) বা নেটিভ UUID প্রকার (PostgreSQL-এ উপলব্ধ) পছন্দ করুন। একটি ৩৬-অক্ষরের স্ট্রিং দ্বিগুণের বেশি স্থান গ্রহণ করে এবং ইনডেক্স লুকআপ ও জয়েনগুলিকে উল্লেখযোগ্যভাবে ধীর করে।SnapUtils উল্লেখ করে যে সংরক্ষণ কম্প্যাক্ট থাকলে RFC 9562-এর কর্মক্ষমতা সুবিধাগুলি সর্বোচ্চ হয়।
আমি কখন UUID v4-এর পরিবর্তে UUID v5 ব্যবহার করব?
যখন আপনার নির্ধারণমূলক IDs প্রয়োজন, তখন v5 ব্যবহার করুন — একই ইনপুট সর্বদা একই UUID তৈরি করে, ডেটাবেস চেক ছাড়াই। যখন আপনার সম্পূর্ণ এলোমেলোতা প্রয়োজন এবং নিশ্চিত করতে চান যে শনাক্তকারীকে তার উৎসে রিভার্স-ইঞ্জিনিয়ার করা যাবে না, তখন v4 ব্যবহার করুন।
মন্তব্য করুন