
每一个现代数据库、分布式系统和 API 都在使用唯一标识符——而在 2026 年,规范它们的标准已经发生了根本性变化。UUID(通用唯一标识符,Universally Unique Identifier) 是一个 128 位的标签,可以在没有任何中央协调的情况下跨计算机系统标识信息。根据新的 RFC 9562(于 2024 年 5 月取代了 RFC 4122),格局已经改变:UUID v4 仍然是随机 ID 的首选,但 UUID v7 现在是数据库主键的推荐标准,因为其时间有序的结构能防止 B 树索引碎片化。
本指南涵盖全貌:UUID 如何工作、何时使用哪个版本,以及如何正确实现它们。
理解 RFC 9562:现代 UUID 标准
UUID 是一个 128 位的数字,几乎可以保证唯一——无需任何中央机构。根据 维基百科,两个 UUID 发生冲突的概率接近于零,在实际应用中被认为是不可能的。不同团队可以独立标记数据,确信他们的 ID 不会冲突。
2024 年 5 月,IETF 发布了 RFC 9562,废止了旧的 RFC 4122。这次更新回应了现代分布式系统的需求,它们需要既唯一_又_可按时间排序的 ID。三个新版本被引入:v6、v7 和 v8。
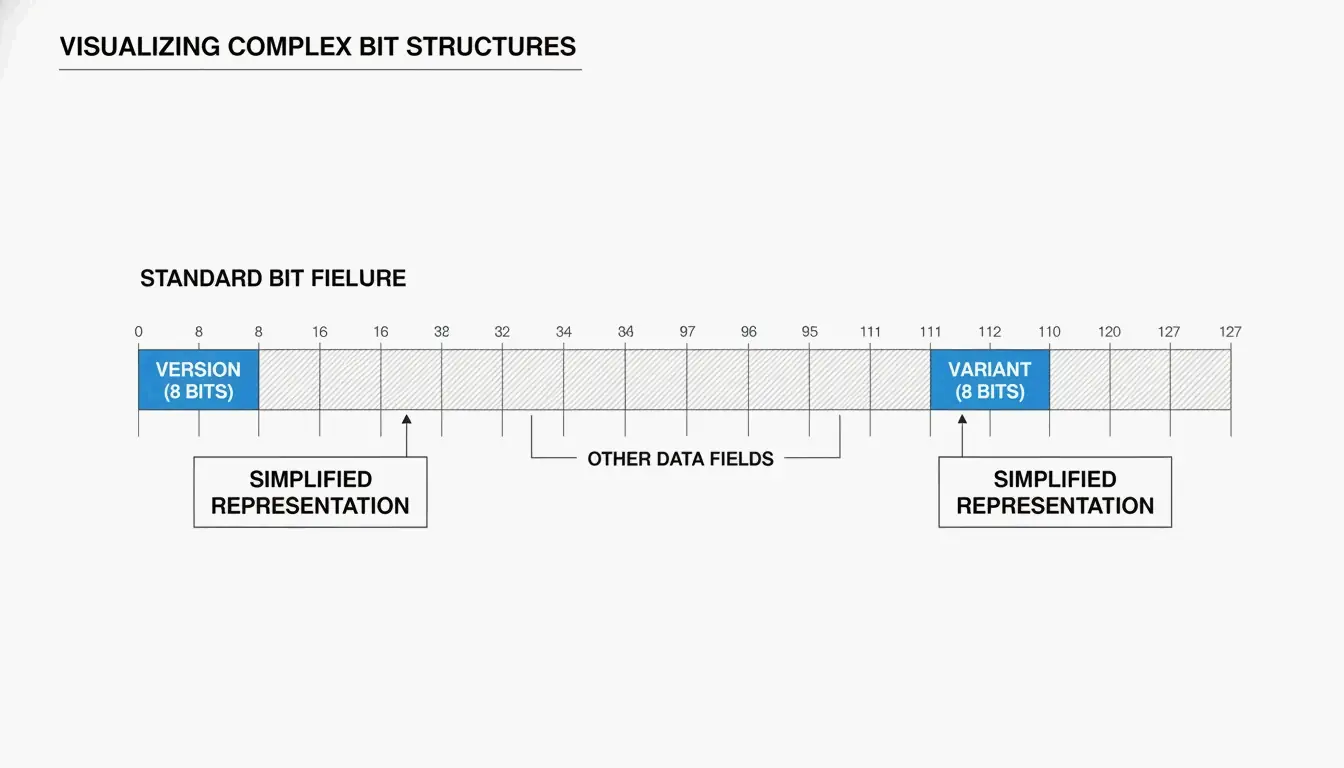
UUID 的解剖:版本与变体
你通常会把 UUID 看作 32 个十六进制字符,用连字符分成五组(8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
两个关键字段告诉你 UUID 是如何生成的:
| 字段 | 位置 | 它告诉你什么 |
|---|---|---|
| 版本位 | 第 7 个字节的前 4 位(第 3 组的第一个字符) | 使用了哪种算法(例如 “4” = v4,”7″ = v7) |
| 变体位 | 第 9 个字节 | UUID 变体——RFC 9562 使用 10 位模式 |
正如 SnapUtils 所解释的,变体位将现代 RFC 9562 UUID 与早期的 Apollo 或微软格式区分开来。
为什么 UUID v7 是数据库的新黄金标准
UUID v4 最大的缺点是它完全随机。当用作 B 树索引 的主键时,数据库不得不在不可预测的位置插入新行。根据 CreateUUID 的说法,这会导致 “页分裂”(page splits)——数据库必须不断重组数据腾出空间,导致写入变慢并浪费内存。
UUID v7 通过在 ID 开头放置一个 48 位 Unix 纪元时间戳(毫秒精度)来解决这个问题。这使得 ID 单调递增——新的总是比旧的大。数据库只需追加到索引末尾,就能给你顺序整数般的性能加上 UUID 的全局唯一性。
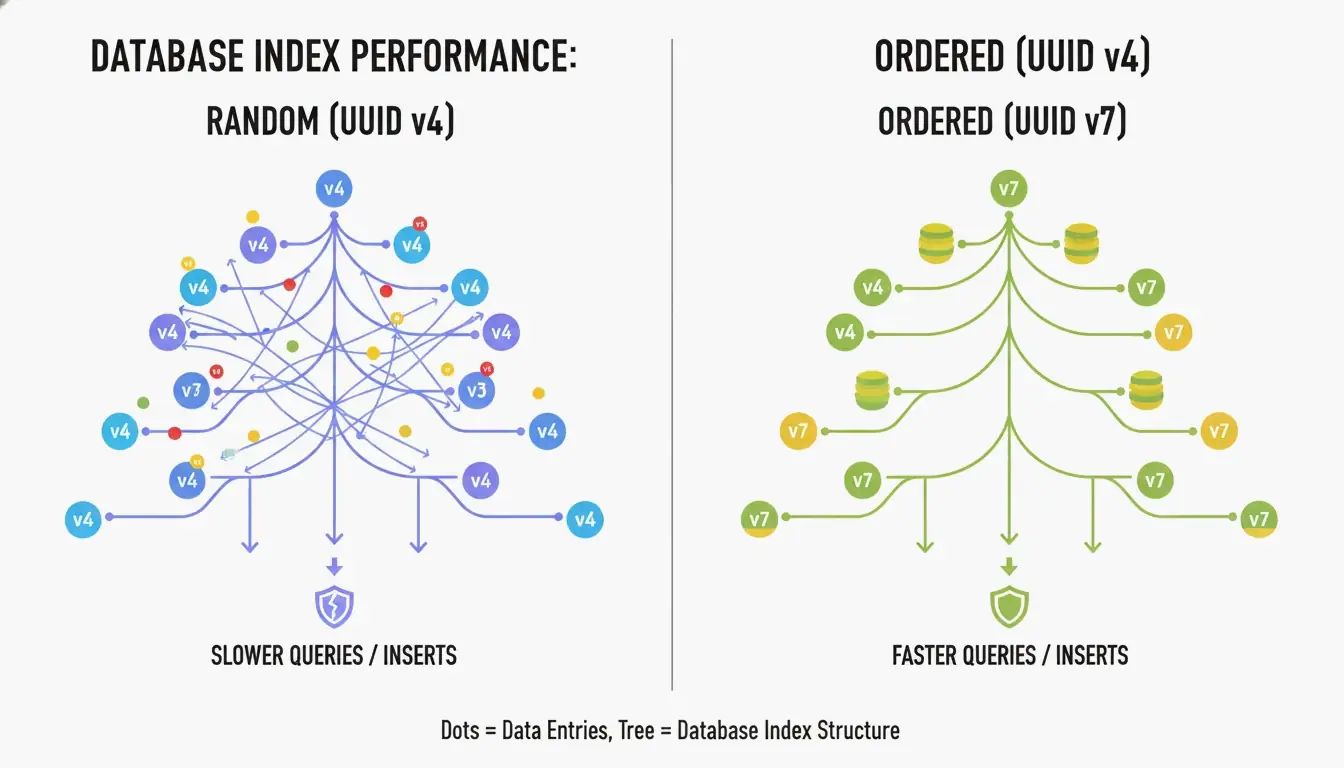
UUID v7 如何平衡时间与熵
UUID v7 使用 CSPRNG(密码学安全伪随机数生成器) 填充剩余的 74 位。根据 维基百科,你需要以每秒约 10 亿个 UUID 的速度生成 85 年才能达到 50% 的冲突概率。对于任何实际应用,UUID v7 实际上是防冲突的。
存储最佳实践:Binary(16) vs String(36)
如何存储 UUID 与使用哪个版本同样重要:
| 存储格式 | 空间 | 索引性能 | 建议 |
|---|---|---|---|
| Binary(16) | 16 字节 | 高(紧凑) | 最佳实践 |
| 原生 UUID 类型 | 16 字节 | 高(优化) | 最适合 PostgreSQL |
| 字符串(Char 36) | 36–72 字节 | 低(碎片化) | 避免 |
SnapUtils 建议始终使用原生类型而非字符串。在 PostgreSQL 中,原生 uuid 类型以紧凑的 16 字节二进制格式存储数据,同时仍支持标准的基于字符串的查询。
UUID vs GUID:有区别吗?
GUID(全局唯一标识符,Globally Unique Identifier) 是微软对 UUID 标准的实现。从历史上看,字节顺序(端序)存在差异——早期微软 GUID 的前三个字段使用小端序,而标准 UUID 使用大端序(网络字节顺序)(SnapUtils)。
到 2026 年,这主要是一个命名约定。在 RFC 9562 下,它们的工作方式完全相同。.NET 中的 Guid.NewGuid() 与 Python 中的 uuid.uuid4() 完全兼容。你会在 Windows/Azure 圈子听到 “GUID”,而在 Linux 和开源社区听到 “UUID”。
实现现代 UUID:逐语言说明
| 语言 | UUID v4 | UUID v7 |
|---|---|---|
| Python | 内置 uuid 模块 |
uuid6 或 uuid7 包 |
| JavaScript | crypto.randomUUID() |
uuid npm 包(v10+) |
| PostgreSQL | gen_random_uuid()(PG 13+) |
原生 uuidv7()(PG 17+)或扩展 |
| .NET | Guid.NewGuid() |
社区包 |
| Rust | uuid crate(v1.7+) |
带 v7 feature 的 uuid crate |
确定性 ID:UUID v5
如果你需要为给定输入(如 URL 或用户名)每次都生成 相同的 ID,请使用 UUID v5。它使用 SHA-1 对命名空间 UUID 和名称字符串进行哈希——当你无法查询中央数据库时,非常适合用于去重。
UUID v1 的隐私教训
UUID v1 使用时间戳和计算机的 MAC 地址。它已基本被废弃,因为它会泄露硬件信息。一个著名的例子:Melissa 病毒的制造者之所以被抓,是因为受感染 Word 文档中的 UUID 包含了他特定的 MAC 地址。
进阶 RFC 9562:v6、v8 和特殊 UUID
RFC 9562 为小众分布式系统需求添加了专用版本:
| 版本 | 用途 | 何时使用 |
|---|---|---|
| v6 | 重新排序的 v1 时间戳——可排序同时保留 v1 的精度 | 迁移旧版 v1 系统 |
| v8 | 自定义——122 位用于开发者定义的数据 | 实验性或厂商专用方案 |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
空占位符 |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
范围端点标记 |
结论
RFC 9562 为现代云时代更新了唯一标识符。实用建议:
- 数据库主键 → 使用 UUID v7,实现时间有序、无碎片化的插入
- 一般随机性 → UUID v4 仍然完全没问题
- 去重 → UUID v5 给你确定性的 ID
- 存储 → 始终使用 Binary(16) 或原生 UUID 类型,绝不用字符串
行动项: 检查你的数据库 schema。如果你在拥有数百万行的表中使用 UUID v4 作为主键,迁移到 UUID v7 是一个简单的改动,可以显著减少索引碎片化并加快查询速度。
常见问题
UUID 和 GUID 一样吗?
功能上,是的。GUID 是微软对 UUID 标准的实现。在 RFC 9562 下,它们的行为完全相同——你可以在 .NET、Java 和 Python 应用中互换使用。
在现实场景中两个 UUID 会冲突吗?
数学上可能,实际上不可能。对于 UUID v4,你需要生成大约 2.71 百亿亿(quintillion) 个 ID 才能达到 50% 的冲突概率。根据 Generate-Random.org,以每秒 10 亿个 UUID 的速度生成 85 年,你只有 50% 的机会出现单次冲突。
我应该在数据库中把 UUID 存为字符串还是二进制?
始终优先使用 Binary(16) 或 原生 UUID 类型(PostgreSQL 中可用)。36 字符的字符串消耗超过两倍的空间,并显著拖慢索引查找和连接。SnapUtils 指出,当存储保持紧凑时,RFC 9562 的性能优势才能最大化。
什么时候该用 UUID v5 而不是 UUID v4?
当你需要确定性 ID 时使用 v5——相同的输入总是产生相同的 UUID,无需查询数据库。当你需要完全随机性并希望确保标识符无法被逆向工程回其来源时,使用 v4。
发表回复