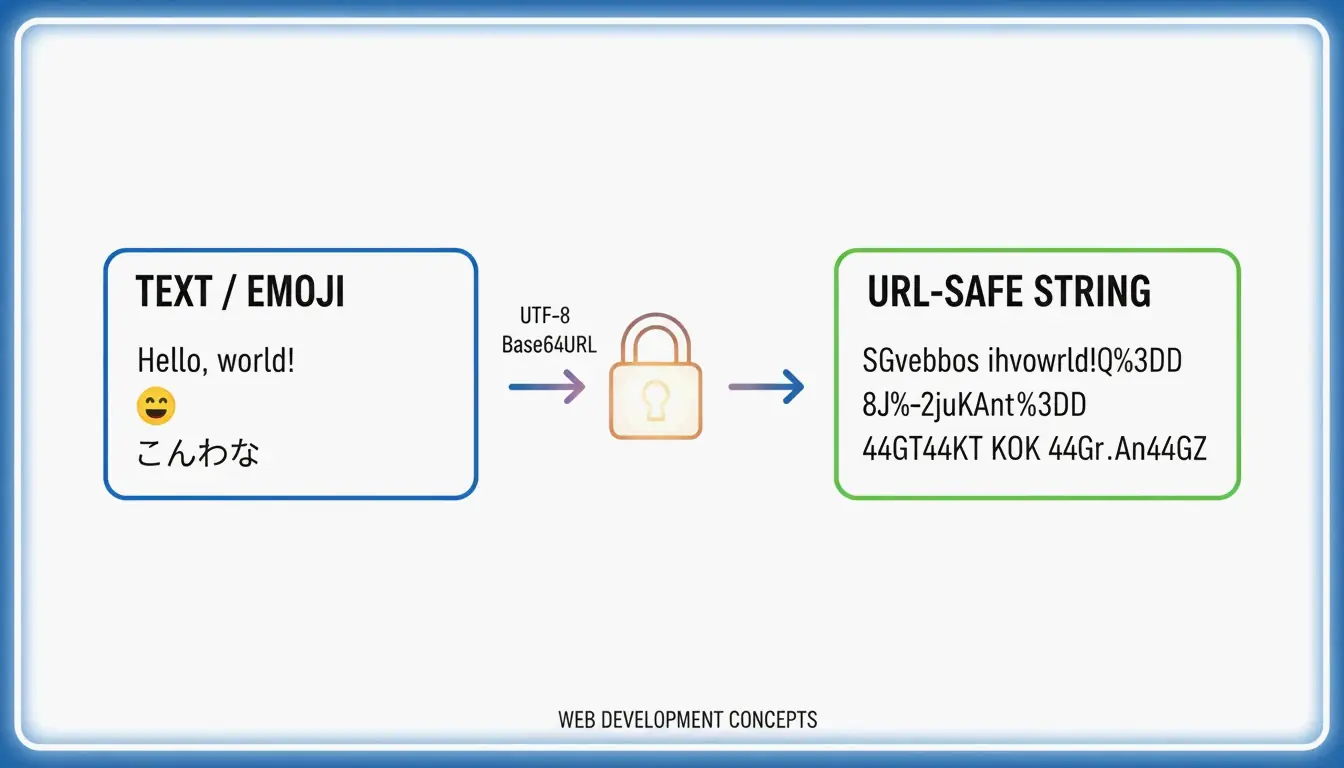
Para converter UTF-8 para Base64URL, siga 4 etapas: (1) codifique o texto em bytes UTF-8, (2) aplique o Base64 padrão, (3) substitua + → - e / → _, (4) remova o preenchimento = final. Isso produz uma string segura para URLs conforme a RFC 4648, usada em JWTs e cabeçalhos de API.
Base64 Padrão vs. Base64URL
| Caractere | Base64 Padrão | Base64URL | Motivo |
|---|---|---|---|
| 62.º caractere | + |
- |
+ significa espaço em URLs |
| 63.º caractere | / |
_ |
/ é um separador de caminho em URLs |
| Preenchimento | = obrigatório |
Omitido | = torna-se %3D em URLs |
| Seguro para URLs | Não | Sim | Uso direto em strings de consulta e nomes de arquivos |
Conforme a RFC 4648 §5, este “Alfabeto Seguro para URLs e Nomes de Arquivos” garante compatibilidade entre sistemas.

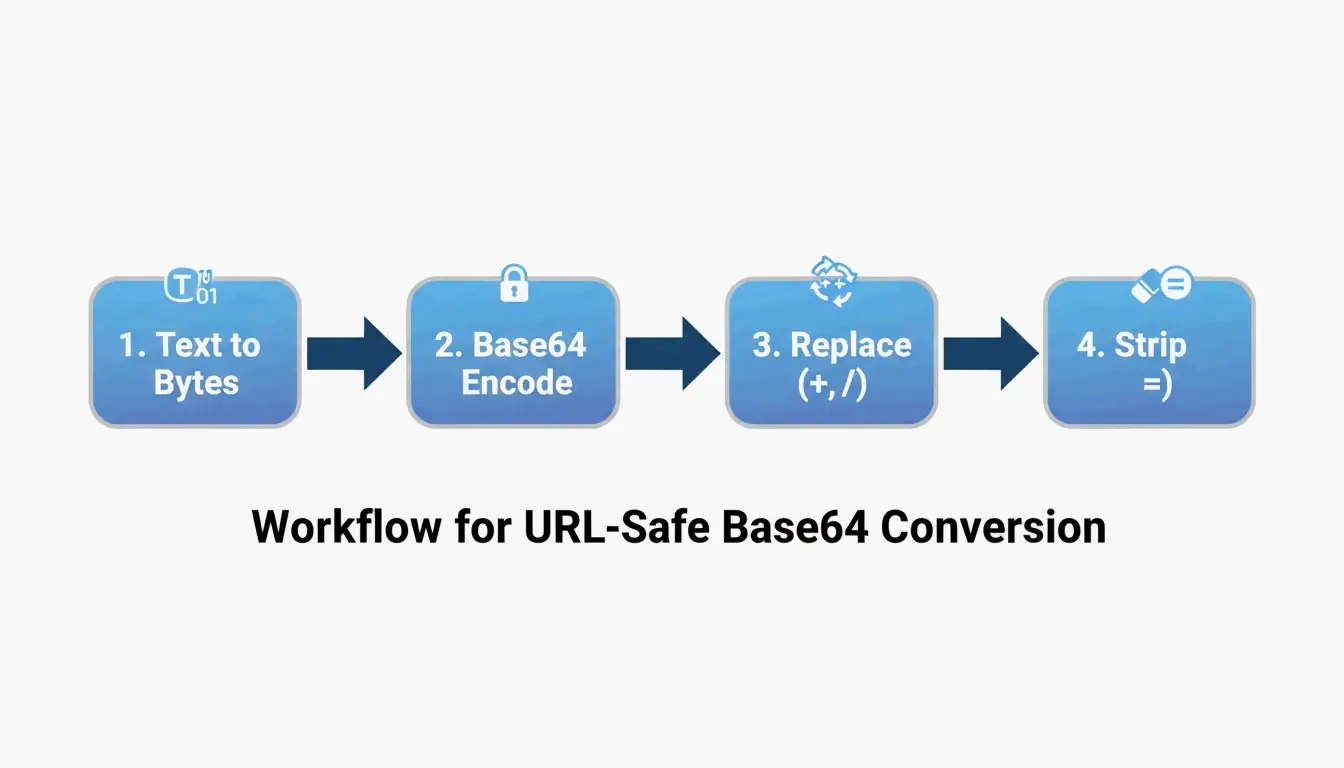
O Processo de Conversão em 4 Etapas
| Etapa | Operação | Exemplo (“Hello”) |
|---|---|---|
| 1 | Texto UTF-8 → bytes | H e l l o → array de bytes |
| 2 | Bytes → Base64 padrão | SGVsbG8= |
| 3 | Substituir + → -, / → _ |
Nenhuma alteração necessária aqui |
| 4 | Remover o preenchimento = final |
SGVsbG8 |
A codificação Base64 aumenta o tamanho dos dados em ~33% conforme a Wikipédia.
Tratamento de Unicode e Emojis
Conforme o NextUtils, Base64 é codificação, não criptografia — ele move dados através de canais exclusivamente de texto. Para lidar com Unicode/emojis sem problemas (“Mojibake”), sempre use TextEncoder para converter primeiro em bytes UTF-8.
| Entrada | Sem TextEncoder | Com TextEncoder |
|---|---|---|
Hello 世界! 🌍 |
Mojibake / TypeError | Base64URL correto |
Exemplos de Código
JavaScript (Navegador) — Seguro para Unicode
function toBase64Url(str) {
const bytes = new TextEncoder().encode(str);
const base64 = btoa(String.fromCharCode(...bytes));
return base64.replace(/\+/g, '-').replace(/\//g, '_').replace(/=+$/, '');
}
Python 3 — Biblioteca Padrão
Conforme o AskPython:
import base64
data = "Hello 世界! 🌍"
encoded = base64.urlsafe_b64encode(data.encode('utf-8')).decode('utf-8').rstrip('=')
print(encoded)
Node.js — Conversão com Buffer
const str = "API_Payload_Data";
const base64url = Buffer.from(str, 'utf8')
.toString('base64')
.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '');
Solução de Problemas: Erros de Preenchimento
| Erro | Causa | Solução |
|---|---|---|
binascii.Error: Incorrect padding |
Preenchimento = ausente |
Adicione = até que o comprimento seja múltiplo de 4 |
TypeError com atob() |
Caracteres não-ASCII | Use TextEncoder primeiro |
| Saída ilegível | Codificação UTF-8 ignorada | Sempre codifique para bytes antes do Base64 |
Conforme o AskPython, calcule o preenchimento ausente: padding_needed = (4 - len(data) % 4) % 4 e adicione essa quantidade de caracteres =.
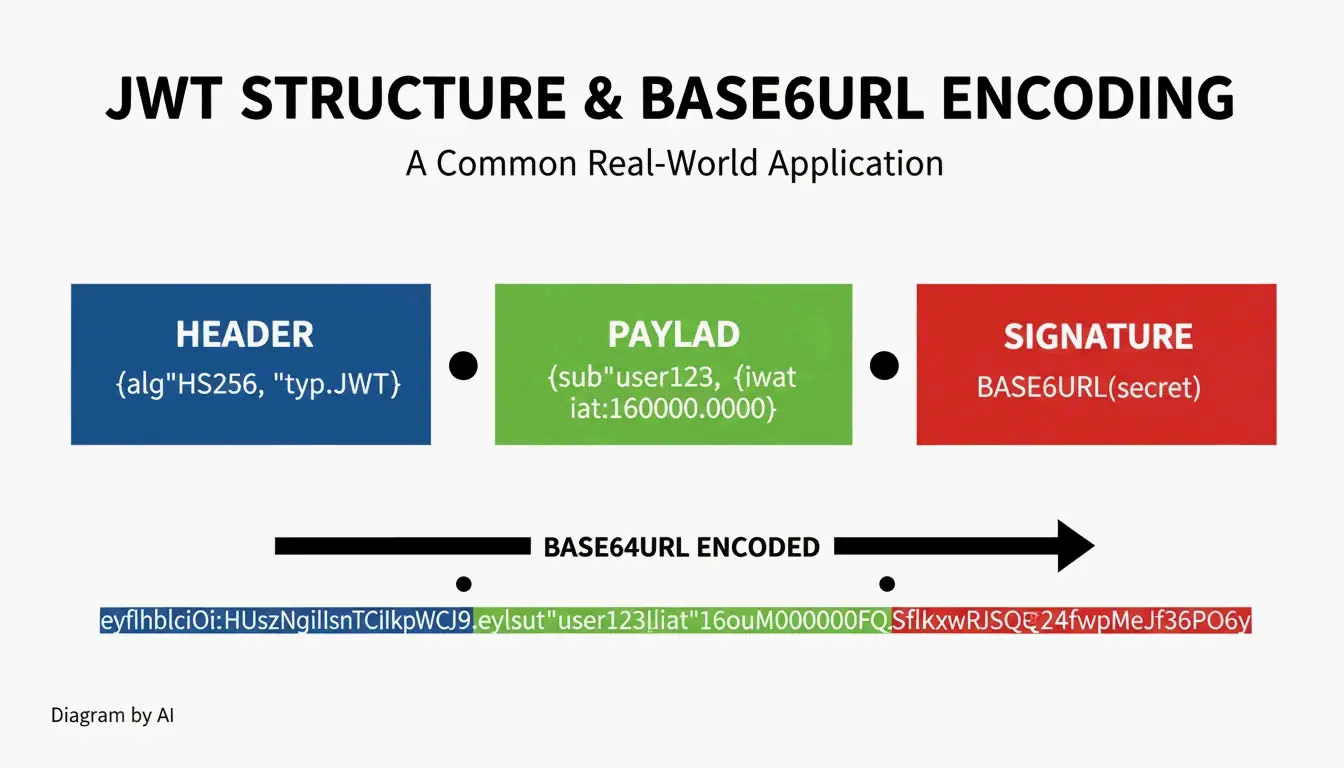
Casos de Uso: JWT e URIs de Dados
Estrutura do JWT (JSON Web Token)
| Parte | Conteúdo | Codificação |
|---|---|---|
| Cabeçalho | Algoritmo + tipo do token | Base64URL |
| Payload | Declarações (dados do usuário, expiração) | Base64URL |
| Assinatura | Assinatura HMAC ou RSA | Base64URL |
JWTs frequentemente começam com eyJ — a codificação Base64URL de { (abertura de colchete JSON).
Base64 vs. Base64URL por Caso de Uso
| Caso de Uso | Codificação | Preenchimento |
|---|---|---|
| Tokens JWT | Base64URL | Omitido |
| URIs de dados (imagens incorporadas) | Base64 Padrão | Obrigatório |
| Autenticação HTTP Basic | Base64 Padrão | Obrigatório |
| Parâmetros de consulta em URLs | Base64URL | Omitido |
Conclusão
4 etapas: bytes UTF-8 → Base64 → substituir +/ por -_ → remover preenchimento. Use TextEncoder em JavaScript, base64.urlsafe_b64encode() em Python, Buffer em Node.js. Siga a RFC 4648 para compatibilidade entre sistemas. Base64URL é codificação, não criptografia — use AES-256 ou TLS para segurança.
Perguntas Frequentes
Base64URL é o mesmo que criptografia?
Não. Base64URL é uma codificação reversível — qualquer pessoa pode decodificá-la sem uma chave. Use AES-256 ou TLS/SSL para proteger dados sensíveis.
Por que o Base64URL falha em um decodificador Base64 padrão?
Decodificadores padrão esperam +, / e o preenchimento =. O Base64URL usa -, _ e omite o preenchimento. Reverta as substituições de caracteres e restaure o preenchimento antes de decodificar.
Por que o preenchimento é omitido em JWTs?
O caractere = torna-se %3D em URLs, tornando as strings mais longas e difíceis de ler. A RFC 4648 permite a omissão porque os decodificadores podem reconstruir o comprimento original sem marcadores de preenchimento.
Deixe um comentário