매장에서 제품을 집어 들면 포장 어딘가에서 바코드를 발견할 수 있습니다. 대부분의 경우 그것은 EAN-13 — 친숙한 검은색과 흰색 막대로 이어진 13자리 숫자입니다. 하지만 가끔 껌 한 통이나 립밤 같이 아주 작은 제품에서는 더 짧고 컴팩트한 바코드인 EAN-8을 보게 됩니다.
두 포맷은 모두 같은 역할을 합니다 — 각 제품에 고유하고 스캔 가능한 ID를 부여하는 것 — 하지만 서로 다른 상황에 맞게 설계되었습니다. 이 가이드는 EAN-13과 EAN-8 사이의 실질적인 차이점, 각각을 언제 사용해야 하는지, 그리고 이들이 더 넓은 GS1 바코드 생태계에 어떻게 들어맞는지 살펴봅니다.
EAN-13 vs EAN-8: 핵심 차이점 한눈에 보기
이 두 포맷의 가장 큰 차이는 몇 자리의 숫자를 담고 있는지와 라벨에서 물리적으로 얼마나 많은 공간을 차지하는지로 요약됩니다.
| 항목 | EAN-13 | EAN-8 |
|---|---|---|
| 자릿수 | 13 | 8 |
| 모듈 너비 | 95 modules | 67 modules |
| 최소 인쇄 너비 | ~1.5 inches (38 mm) | ~1 inch (26 mm) |
| 일반적 용도 | 일반 소매 상품 | 매우 작은 포장 |
| 관리 주체 | GS1 | GS1 |
Wikipedia에 따르면, EAN-13 바코드는 13자리를 인코딩하며 95개의 동일한 너비의 모듈로 구성됩니다. EAN-8은 8자리만 인코딩하므로 훨씬 더 좁은 바코드가 만들어지며, 너비는 대략 3분의 2 수준입니다.
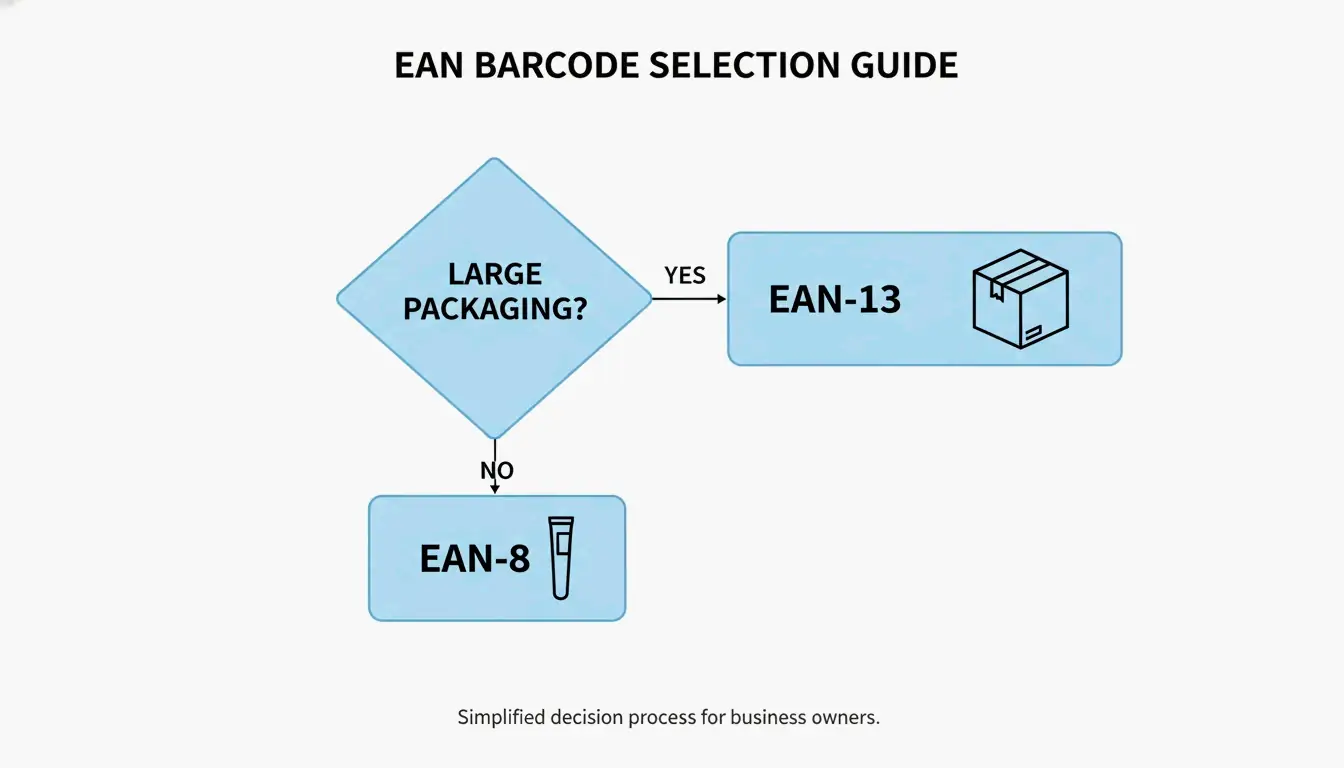
선택 방법: 간단한 의사결정 트리
어떤 포맷을 사용할지 결정해야 하는 사람이라면, 그 논리는 단순합니다.
- 일반 제품 — 포장에 최소 1.5 inches 너비의 바코드를 넣을 공간이 있다면 EAN-13을 선택하세요. 전 세계 소매업의 기본 요구사항입니다.
- 작은 제품 — 제품의 인쇄 가능 영역이 EAN-13을 넣기에 너무 좁다면 EAN-8을 신청할 수 있습니다.
사람들이 자주 간과하는 것이 바로 Quiet Zone — 바코드 양쪽의 빈 여백입니다. Wikipedia에 따르면, EAN-13 바코드에는 흔히 오른쪽에 Quiet Zone이 시작되는 지점을 표시하는 > 기호가 포함됩니다. 이 시각적 표시는 스캐너가 근처의 그래픽이나 텍스트에 혼동되지 않고 바코드의 가장자리를 찾는 데 도움을 줍니다.
EAN-8이 맞는 경우: 표면적 규칙
EAN-8은 무료 대안이 아닙니다 — 표준 바코드를 넣을 수 없는 제품을 위한 특화된 포맷입니다. Barcodes South Africa가 설명하듯, 사용 가능한 자릿수가 8자리뿐이므로(13자리보다 훨씬 적은 고유 조합 수), GS1 회원 기구는 포장이 EAN-13을 담기에 너무 작다는 것을 증명하는 제조사에게만 EAN-8 번호를 할당합니다.
실제로는, EAN-8을 다음과 같은 제품에서 보게 됩니다:
– 개별 캔디바나 껌 팩
– 작은 화장품(립밤, 마스카라)
– 씨앗이나 향신료 봉지
– 소형 전자제품 액세서리
제품에 충분한 공간이 있다면 EAN-13이 항상 기본 선택입니다.
기술 사양: EAN 포맷은 어떻게 구성되어 있을까?
막대 너머로, EAN 포맷은 GS1 (Global Standards 1) 시스템을 통해 모든 제품이 전 세계적으로 고유한 ID를 받을 수 있도록 보장하는 정밀한 구조를 따릅니다.
EAN-13 구조:
- GS1 Prefix (3자리): 어느 GS1 회원 기구가 코드를 발행했는지 식별합니다. 예를 들어,
590은 폴란드,400–440은 독일입니다. - 제조사 코드 (가변 길이): 회사에 할당된 고유 식별자입니다.
- 제품 코드 (가변 길이): 회사가 특정 품목에 할당하는 구체적인 번호(본질적으로 SKU)입니다.
- 체크 디지트 (1자리): 스캐닝 오류를 잡아내기 위해 이전 모든 자릿수로부터 계산된 마지막 자릿수입니다.
EAN-8 구조:
EAN-8은 다르게 동작합니다 — 가변 길이 제조사 코드가 없습니다. 번호 할당 기관이 제품 코드를 직접 할당합니다. Oracle에 따르면, 이미 EAN-13 prefix를 보유한 회사라도 EAN-8을 요청할 수 있지만, 두 번호는 서로 수학적 관계가 없습니다.

두 포맷 모두 오류 감지에 있어 놀라울 정도로 신뢰할 수 있습니다. Wikipedia에 따르면, EAN-13은 단일 자릿수 오류의 100%와 전치 오류(인접한 두 자릿수가 뒤바뀌는 경우)의 90%를 감지합니다. 즉, 스캐너가 단 하나의 막대라도 잘못 읽으면 체크 디지트가 거의 항상 이를 표시합니다.
미국에서 EAN-13이 통용될까? UPC-A와의 비교
국제적으로 판매하는 회사에게 흔한 우려는, 역사적으로 자체 12자리 UPC-A 포맷을 사용했던 미국에서 EAN-13이 작동하는지 여부입니다.
짧은 대답은 네, 완전히 통용됩니다. “2005 Sunrise” 이니셔티브 — 이미 오래전에 정책이 된 — 는 미국과 캐나다의 모든 POS(Point-of-Sale) 시스템이 EAN-13과 UPC-A를 모두 수용하도록 요구합니다. 사실, EAN-13은 기술적으로 UPC-A의 상위 집합입니다. UPC-A 바코드는 단순히 첫 자리가 0인 EAN-13입니다.
실무에서 이것이 의미하는 바:
– 글로벌 브랜드라면, 어디서든 EAN-13을 사용할 수 있습니다 — 별도의 UPC-A 코드가 필요 없습니다.
– 미국 소매업체는 설정 변경 없이도 여러분의 EAN-13 제품을 스캔할 수 있습니다.
EAN-13 시스템 내에 알아둘 만한 특수 prefix도 있습니다. Bookland prefix(978과 979)는 ISBN을 EAN-13에 직접 삽입하여, 어디서 출판되었든 관계없이 모든 표준 소매 체크아웃에서 도서를 스캔할 수 있게 합니다.
GTIN 통합과 데이터베이스 정규화
EAN-13과 EAN-8 모두 Global Trade Item Number (GTIN) 패밀리의 일부입니다. 서로 다른 바코드 길이를 가진 제품이 동일한 데이터베이스 — 예를 들어 창고 관리 시스템 — 에 들어가게 되면, 일관된 포맷이 필요합니다. 그 역할을 GTIN-14가 합니다.
정규화는 단순합니다. 짧은 코드를 앞쪽의 0으로 채웁니다(pad).
| 바코드 | GTIN-14 |
|---|---|
EAN-13: 4006381333931 |
04006381333931 (앞쪽 0 하나) |
EAN-8: 96385074 |
00000096385074 (앞쪽 0 여섯 개) |
Oracle WMS 같은 시스템에서는 모든 GTIN이 오른쪽 정렬되어 14자리로 채워지므로, 단일 데이터베이스 필드가 립밤 한 통부터 풀 팔레트까지 모든 것을 처리할 수 있습니다.

체크 디지트(Modulo-10) 계산 방법, 단계별 가이드
모든 EAN 바코드의 마지막 자릿수는 임의의 숫자가 아닙니다 — Modulo-10 알고리즘으로 계산됩니다. 최신 소프트웨어는 이를 자동으로 처리하지만, 바코드를 프로그래밍 방식으로 생성하거나 스캐닝 문제를 해결할 때는 수학을 이해하는 것이 유용합니다.
예시: EAN-13 400638133393?의 체크 디지트 검증
1단계 — 오른쪽(체크 디지트 제외)에서 시작하여 3과 1을 번갈아 가며 가중치를 할당합니다:
| 위치 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 자릿수 | 4 | 0 | 0 | 6 | 3 | 8 | 1 | 3 | 3 | 3 | 9 | 3 |
| 가중치 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 |
| 곱 | 4 | 0 | 0 | 18 | 3 | 24 | 1 | 9 | 3 | 9 | 9 | 9 |
2단계 — 모든 곱을 더합니다: 4 + 0 + 0 + 18 + 3 + 24 + 1 + 9 + 3 + 9 + 9 + 9 = 89
3단계 — 다음 10의 배수(90)를 찾습니다. 뺍니다: 90 − 89 = 1.
체크 디지트는 1 이며, 전체 바코드는 4006381333931이 됩니다.
이것은 라벨 디자인 중에 수행하기 좋은 정합성 검사(sanity check)입니다 — 수천 장의 라벨을 인쇄하기 전에 잘못된 체크 디지트를 잡아내면 시간과 비용을 모두 절약할 수 있습니다.
결론
EAN-13은 소매 바코드 분야의 글로벌 핵심(workhorse)입니다 — 대다수 제품에 사용하는 포맷입니다. EAN-8은 컴팩트한 대안으로, 포장 공간이 표준 바코드를 담기에 진정으로 너무 좁은 품목에만 사용됩니다. 두 포맷 모두 GS1이 관리하며, 동일한 Modulo-10 체크 디지트 시스템을 사용하고, 미국과 캐나다를 포함한 전 세계 모든 최신 POS 시스템에서 안정적으로 스캔됩니다.
결정은 표면적 문제로 귀결됩니다. 포장이 최소 1.5 inches 너비의 바코드를 수용할 수 있다면 EAN-13을 사용하세요. 수용할 수 없다면, 현지 GS1 사무소를 통해 EAN-8을 신청하세요. 어느 쪽이든, 귀하의 제품은 전체 공급망에 걸쳐 올바르게 스캔될 것입니다.
FAQ
EAN-8 코드를 EAN-13 코드로 변환할 수 있나요?
아니요 — 이들은 완전히 별개의 식별자입니다. EAN-8 번호는 GS1이 직접 할당하며 귀하의 EAN-13 제조사 prefix와 아무런 연결이 없습니다. EAN-13 코드가 필요하다면, 할당받은 EAN-13 블록의 번호를 사용해야 합니다.
미국과 캐나다에서 EAN-13이 통용되나요?
네. 2005 Sunrise 합의 이후, 북미의 모든 최신 POS 시스템은 문제없이 UPC-A와 EAN-13을 모두 스캔합니다. 대부분의 글로벌 브랜드는 이제 모든 시장에서 관리를 단순화하기 위해 EAN-13만 단독으로 사용합니다.
14자리를 기대하는 시스템에서 EAN-8 바코드를 스캔하면 어떻게 되나요?
시스템은 GTIN-14 필드를 채우기 위해 6개의 앞쪽 0을 추가하여 8자리 코드를 zero-pad 합니다(예: 000000XXXXXXXX). 이것은 Oracle WMS 같은 시스템에서 서로 다른 제품 크기에 걸쳐 데이터베이스 레코드의 일관성을 유지하기 위한 표준 관행입니다.