Your API call just failed with JSONDecodeError: Expecting property name enclosed in double quotes. The clock is ticking. The data came from an LLM, and somewhere in that 2,000-token response, a single trailing comma killed your entire pipeline.
As of May 2026, the fastest way to fix malformed JSON files is to use automated libraries like json_repair (Python) or jsonrepair (npm). These tools are purpose-built to fix LLM-generated syntax errors instantly. For manual repairs, the usual suspects are trailing commas, single quotes, or unquoted keys — the three most common violations of the RFC 8259 standard.
The Fastest Fix: json_repair for LLM Outputs
Standard parsers like Python’s json.loads() are strict by design. One misplaced character triggers a JSONDecodeError and everything stops. This is a daily problem in 2026 because LLMs routinely wrap JSON in conversational text, truncate responses mid-sentence, or sprinkle in comments that break the spec.
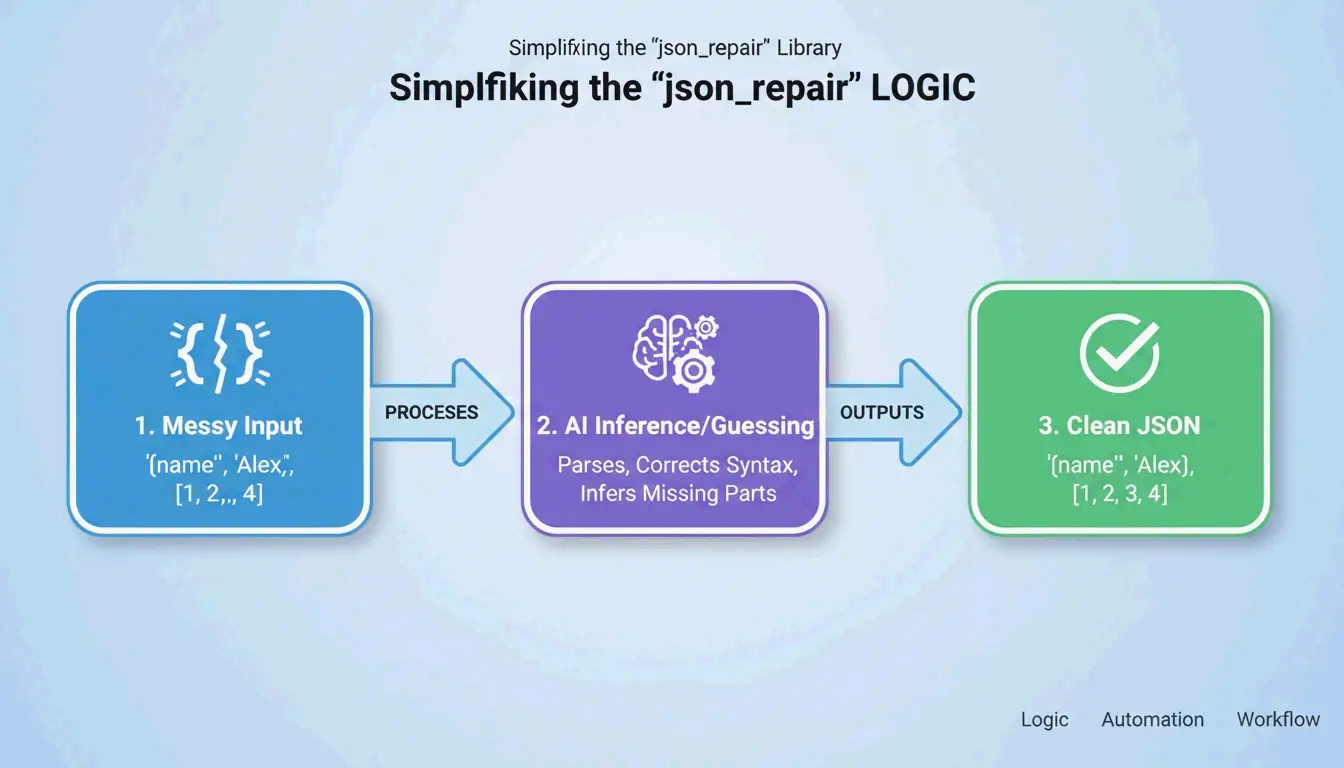
The json_repair library is the go-to solution. According to GitHub, this project has over 4,700 stars as of 2026. It works by “guessing” the intent of the string — closing missing brackets, adding quotes, and stripping extra text surrounding the JSON block.
Python: Before and After
Install: pip install json-repair
The broken input:
import json_repair
bad_json = '{"user": "Alice", "status": tru'
decoded_object = json_repair.loads(bad_json)
# Output: {'user': 'Alice', 'status': True}
What happened behind the scenes: json_repair saw that tru was likely true, added the missing closing brace, and returned a valid Python dictionary. Zero manual intervention.
Salvage Mode: When the Data Is Really Ugly
For tougher cases, json_repair (v0.59.5+) includes a Salvage Mode. As noted in the project documentation, this mode is built specifically for truncated AI responses or corrupted logs. It can force arrays into objects or drop items that are too broken to save, ensuring the output fits your schema.
import json_repair
# Salvage mode for severely truncated data
result = json_repair.loads(
'{"items": [{"id": 1, "name": "Widget"}, {"id": 2, "na',
salvage_mode=True
)
# Result: {'items': [{'id': 1, 'name': 'Widget'}, {'id': 2}]}
# Dropped the incomplete 'na' but saved everything else
npm Alternative
For Node.js projects, the jsonrepair CLI handles the same job:
# Fix a file in place
npx jsonrepair broken.json > fixed.json
# Fix a string in a script
const { jsonrepair } = require('jsonrepair');
const fixed = jsonrepair('{"name": "test",}');
Manual Debugging: Finding What Broke the Spec
When automation does not cut it, you need to find exactly where the file violates RFC 8259. JSON is far less forgiving than YAML or JavaScript. As the JSONParser Diagnostics Team explains, “The parser fails at the first character it cannot make sense of, which is often a downstream symptom of a problem several lines earlier.”
The Three JSON Killers
Killer 1: Trailing Commas
According to DEV Community, trailing commas are the #1 cause of parse failures. They are fine in JavaScript but illegal after the last item in a JSON array or object.
// BROKEN - trailing comma after "active"
{
"name": "Alice",
"status": "active",
}
// FIXED - no comma before closing brace
{
"name": "Alice",
"status": "active"
}
Killer 2: Single Quotes
JSON requires double quotes (") for both keys and string values. Many Python and JavaScript developers accidentally use single quotes ('). As TidyCode notes, this is a mandatory fix.
// BROKEN - single quotes
{'name': 'Alice'}
// FIXED - double quotes
{"name": "Alice"}
Killer 3: Unquoted Keys
In JavaScript you can write { name: "Alice" }. In JSON, every key needs double quotes.
// BROKEN - unquoted key
{name: "Alice"}
// FIXED - quoted key
{"name": "Alice"}

The “Unexpected Token” Error
When a validator flags “Unexpected Token,” it means the parser hit NaN, Infinity, or undefined — JavaScript constants that JSON does not support. JSON only allows null, true, false, and numbers.
// BROKEN - NaN is not valid JSON
{"score": NaN, "result": Infinity}
// FIXED - replace with null or valid values
{"score": null, "result": null}
Strict Parsing vs. Repair Parsing: When to Use Which
The right approach depends on where your data comes from. Human-edited config files deserve strict parsing to force the author to fix mistakes. Machine-generated data from LLMs or API logs needs repair-based parsing.
| Feature | Strict (json.loads) |
Repair (json_repair) |
|---|---|---|
| Trailing Commas | Raises JSONDecodeError |
Automatically removed |
| Single Quotes | Fails | Converted to double quotes |
| Truncated Data | Fails | Closes open brackets/quotes |
| Comments | Fails | Automatically stripped |
| Best Use Case | Human-edited config files | LLM outputs, API logs |
Schema-Guided Repairs with Pydantic
You can guide the repair process using Pydantic v2 or JSON Schema. By giving json_repair a schema, the tool does more than fix syntax — it can correct types (turning string "1" into number 1) and fill missing required fields with defaults.
from pydantic import BaseModel
import json_repair
class User(BaseModel):
id: int
name: str
active: bool = True
# Broken JSON with wrong types
raw = '{"id": "42", "name": "Alice"}'
repaired = json_repair.loads(raw)
# Validate against schema
user = User(**repaired)
# user.id is now int(42), user.active defaults to True
As Stefano Baccianella noted in his 2025 project citation, this approach is optimized for the “mostly correct but technically invalid” JSON that language models tend to produce.
Handling Multi-Gigabyte Files Without Crashing
Repairing a 10KB snippet is easy. Fixing a 2GB file requires a strategy that will not eat all your RAM. Loading the entire file into memory causes Out-of-Memory (OOM) errors.
Strategy 1: Streaming with ijson
For massive datasets, use ijson to process data piece by piece. As Scrapfly mentions, ijson processes data incrementally. Pair it with a cleanup script that fixes issues line-by-line before parsing.
import ijson
# Stream through a large JSON file
with open('huge_broken.json', 'r') as f:
for item in ijson.items(f, 'records.item'):
# Process each item individually
process(item)
Strategy 2: CLI Pipe for Maximum Efficiency
The most memory-efficient approach for large files is to use the jsonrepair CLI and pipe output directly to a new file:
# Streams repair, never loads full file into memory
jsonrepair large_broken.json > fixed.json
This is significantly more memory-efficient than loading the file into Python or a browser.
Conclusion
Fixing malformed JSON is no longer a manual chore thanks to AI-aware libraries like json_repair. You still need to understand RFC 8259 basics — no trailing commas, no single quotes, no unquoted keys — but automation is the only practical approach for data at scale in 2026.
The workflow is simple: try a repair library first. If that fails, use a validator to pinpoint the exact syntax error. This keeps your applications running even when incoming data is less than perfect.
FAQ
Can JSON officially support comments or single quotes?
No. The RFC 8259 standard strictly forbids comments. Single quotes are also invalid — only double quotes are allowed for keys and strings. However, tools like json_repair can strip comments and convert quotes automatically to make files parseable by standard libraries.
How do I handle very large malformed JSON files without crashing?
Use a streaming parser like ijson to process data in chunks. Avoid loading the entire malformed string into a single variable. For the fastest results, use CLI repair tools that pipe output directly to a new file on disk without holding everything in memory.
What is the difference between malformed JSON and invalid JSON?
Malformed JSON violates syntax rules — missing brackets, unquoted keys, trailing commas — making it impossible to parse. Invalid JSON follows all syntax rules but fails to match a specific JSON Schema (e.g., a field is a string when the schema expects an integer). Fixing malformed JSON is structural repair; fixing invalid JSON is about data integrity.
Can I use json_repair with Pydantic validation?
Yes. Run json_repair.loads() first to fix syntax errors, then pass the repaired dictionary to your Pydantic model for type validation and schema enforcement. This two-step approach handles both structural and semantic issues.
What about JSON with JavaScript-style comments?
Standard JSON does not support comments, but json_repair can strip // and /* */ comments automatically. If you need comments in your config files, consider using JSONC (JSON with Comments) format and a compatible parser like json5 for Python.