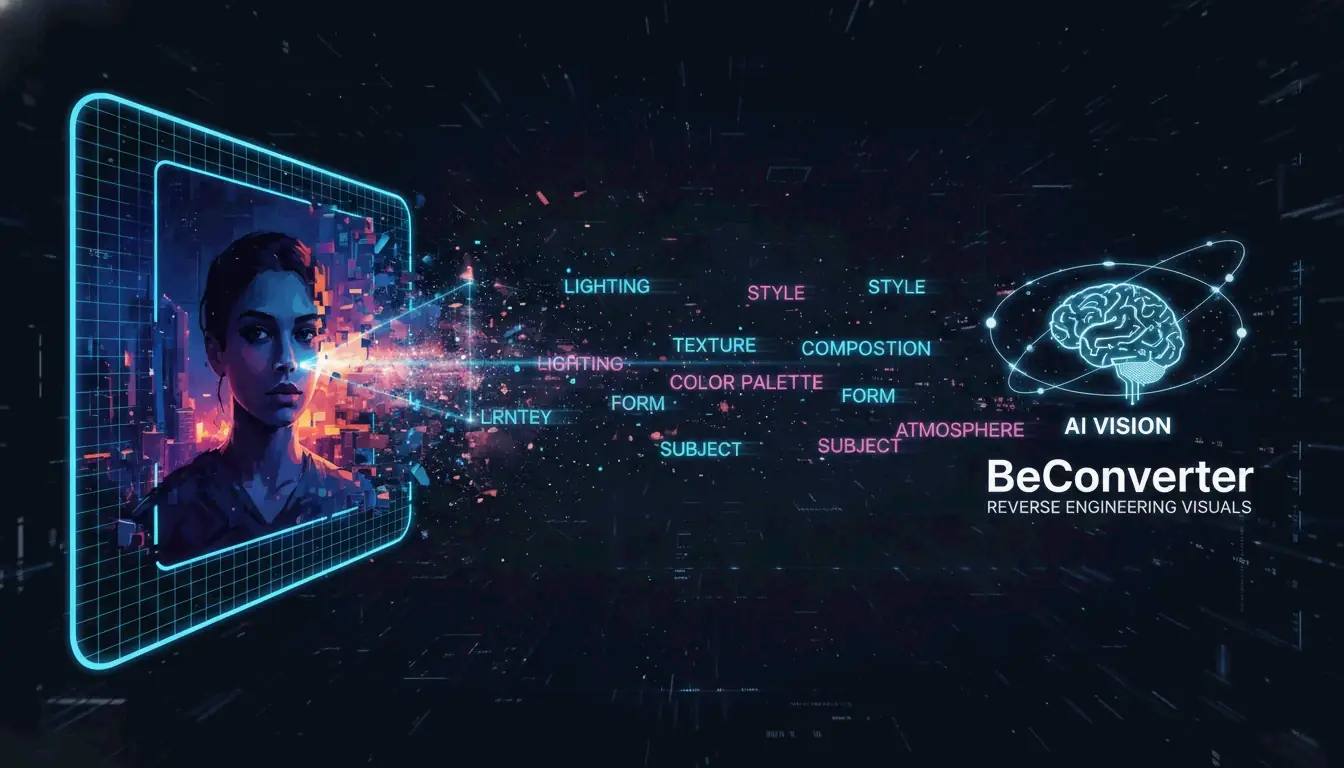
Unggah gambar ke BeConverter, biarkan Vision-Language Model (VLM) menguraikan visual menjadi token gaya, lalu tempelkan prompt yang diekstrak ke Midjourney, Stable Diffusion, atau FLUX. Itulah alur kerja lengkap untuk mengubah visual apa pun menjadi prompt AI yang dapat direproduksi—tanpa perlu menerka-neka.
Apa Itu Reverse Prompting dan Bagaimana BeConverter Bekerja?
Reverse prompting mengubah piksel kembali menjadi teks yang dapat dipahami oleh model generatif. Alih-alih menulis prompt dari awal dan berharap hasilnya sesuai dengan referensi, Anda memulai dari gambar jadi dan mengekstrak kata kunci, kondisi pencahayaan, dan tag estetika yang mendefinisikan tampilannya.
BeConverter menggunakan Vision-Language Model (VLM) untuk menganalisis properti artistik sebuah gambar. Model ini membandingkan foto Anda dengan data pelatihannya untuk mengklasifikasikan atribut seperti gaya rendering (3D vs. lukisan cat minyak), pengaturan pencahayaan (volumetrik vs. ambient), dan komposisi. Hasilnya adalah prompt teks terstruktur yang dapat Anda masukkan ke generator gambar mana pun.
VLM vs. OCR: Mengapa Pemindaian Standar Tidak Dapat Membaca Seni
Optical Character Recognition (OCR) membaca teks—huruf, angka, struk belanja. VLM membaca arah seni. Seperti yang dijelaskan oleh PromptsEra, di mana OCR melihat kata “STOP” pada rambu, VLM mendeteksi bentuk segi delapan, cat merah yang pudar, kedalaman bidang, dan sudut matahari—detail yang penting untuk reproduksi visual.
| Kemampuan | OCR | VLM |
|---|---|---|
| Membaca teks | Ya | Terbatas |
| Mengidentifikasi pencahayaan | Tidak | Ya |
| Mendeteksi gaya komposisi | Tidak | Ya |
| Mengekstrak color grading | Tidak | Ya |
| Menghasilkan teks siap prompt | Tidak | Ya |
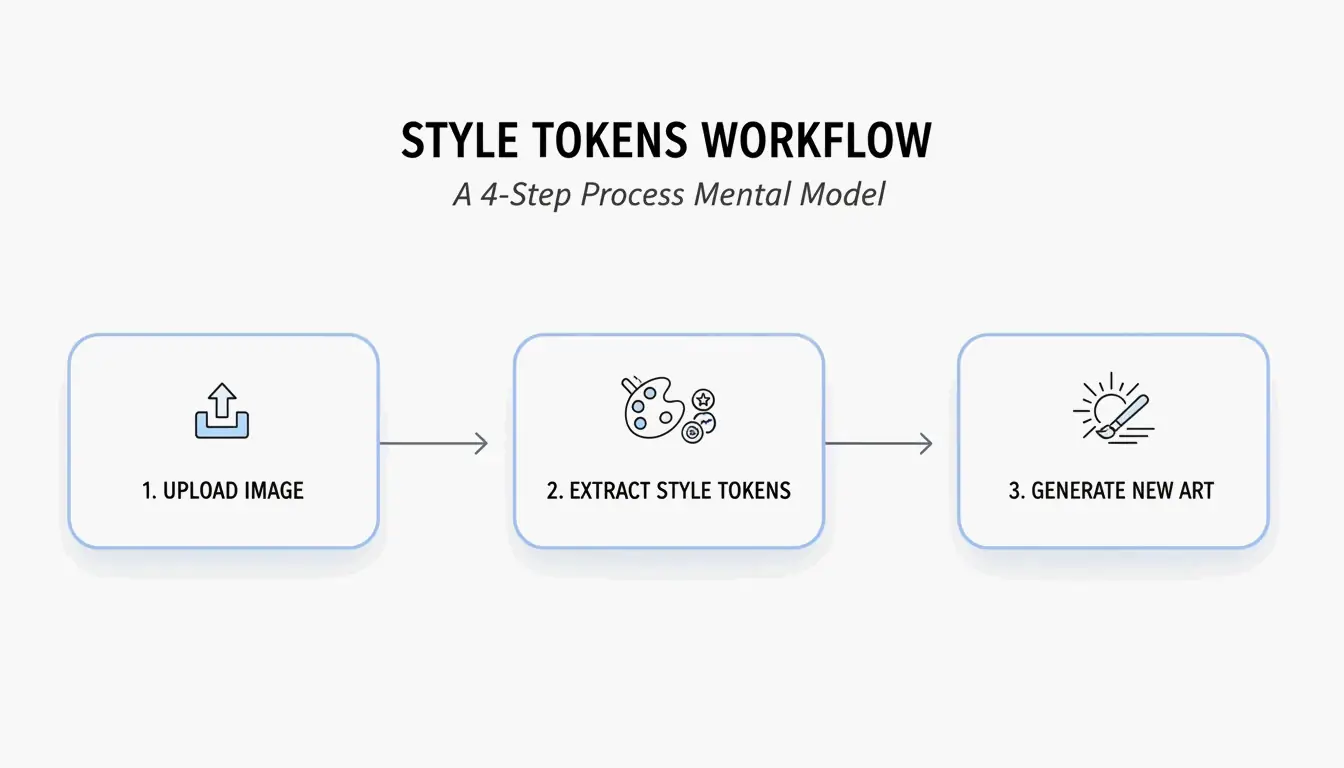
Alur Kerja 4 Langkah: Cara Membuat Prompt AI dengan BeConverter
Berdasarkan Style Token Isolation Strategy dari PromptsEra, ikuti urutan berikut:
- Unggah gambar sumber Anda — Gunakan file beresolusi tinggi. VLM membutuhkan piksel yang jelas untuk mendeteksi atribut halus seperti “volumetric lighting” atau “35mm lens grain.”
- Pilih interrogator Anda — Pilih CLIP Interrogator untuk prompt deskriptif dan puitis (ideal untuk Midjourney) atau DeepDanbooru untuk tag yang dipisahkan koma (ideal untuk Stable Diffusion).
- Isolasi token gaya — Hapus token subjek (misalnya, “seekor kucing”) dan pertahankan hanya penanda gaya (misalnya, “cyberpunk, neon rim lighting, 8k, cinematic depth of field”).
- Tempelkan ke generator Anda — Salin token yang sudah dibersihkan ke Midjourney v7, Stable Diffusion, atau FLUX dan hasilkan.
Mengadaptasi Prompt untuk Model 2026: FLUX vs. Midjourney
Setiap model menafsirkan prompt secara berbeda. PromptsEra mencatat bahwa deskripsi abstrak seperti “suasana melankolis” bekerja baik di Midjourney tetapi gagal di FLUX, yang membutuhkan deskripsi spasial literal seperti “ruangan gelap dengan hujan mengenai jendela, lampu neon di atas kepala menghasilkan bayangan panjang.”
| Gaya Prompt | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| Abstrak/puitis | Kuat | Lemah | Sedang |
| Literal/spasial | Sedang | Kuat | Sedang |
| Tag dipisahkan koma | Sedang | Sedang | Kuat |
| Prompt negatif | Didukung (--no) |
Didukung | Didukung |
Strategi Frankenstein: Menggabungkan Gaya dari Beberapa Gambar
Teknik rekayasa balik yang paling efektif menggabungkan token gaya dari sumber yang berbeda. Gunakan BeConverter untuk mengekstrak pencahayaan dari Gambar A dan rendering subjek dari Gambar B, lalu gabungkan menjadi satu prompt.
Kontrol utama untuk penggabungan yang konsisten:
- Rasio Aspek — Atur secara eksplisit (misalnya,
--ar 16:9untuk Midjourney) karena alat reverse tidak dapat menyimpulkan kanvas yang Anda inginkan. - Prompt Negatif — Selalu tambahkan pengecualian seperti “blurry, deformed, low quality.” Alat reverse hanya mendeteksi apa yang ada; mereka tidak dapat mengidentifikasi apa yang seharusnya tidak ada.
Seperti yang disarankan oleh Andrew Lo, Direktur Laboratory for Financial Engineering MIT: “Selalu tanyakan pada LLM, apa yang tidak Anda yakini? Informasi apa yang Anda lewatkan?” Terapkan prinsip yang sama—identifikasi celah dalam prompt yang Anda rekonstruksi sebelum menghasilkan.
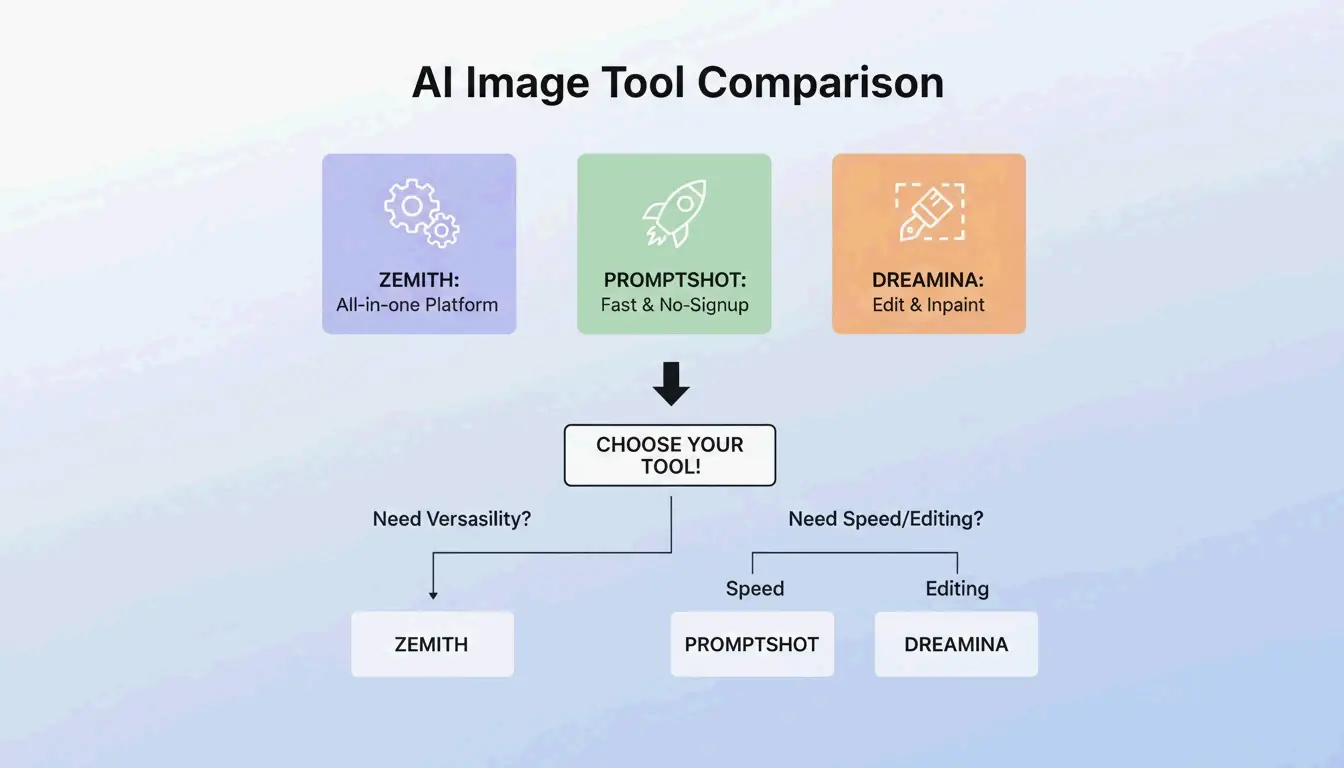
BeConverter vs. Zemith vs. PromptShot: Perbandingan Alat (2026)
| Fitur | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| Mode interrogator | CLIP + DeepDanbooru | Multi-model (25+) | Sekali jalan |
| Kredit gratis harian | Ya | 100 | Tidak terbatas |
| Perlu mendaftar | Tidak | Ya | Tidak |
| Cocok untuk | Isolasi token | Alur kerja all-in-one | Ekstraksi cepat |
| Format output | Deskriptif + tag | Spesifik model | String prompt |
Opsi tambahan yang perlu diperhatikan:
- Zemith — Lebih dari 30.000 pengguna per 2026. Menurut Zemith, platform ini mendukung 25+ model termasuk GPT-5.5 dengan 100 kredit harian.
- PromptShot AI — Tidak perlu akun. PromptShot AI menawarkan proses 5 langkah yang dirancang untuk kreator yang perlu “membuat ulang dan meningkatkan” karya AI dengan cepat.
- Dreamina (GPT Image 2) — Hasilkan dan edit dalam satu jendela. Menurut Dailyhunt, model GPT Image 2 mendukung inpainting dan penyesuaian pencahayaan langsung setelah pembuatan prompt.
Kesimpulan
Reverse prompting dengan BeConverter mengubah gambar referensi apa pun menjadi prompt AI terstruktur dan dapat digunakan kembali dalam hitungan detik. Unggah gambar Anda, ekstrak token gaya dengan CLIP atau DeepDanbooru, isolasi atribut artistik, dan tempelkan ke generator pilihan Anda. Untuk hasil terbaik, sesuaikan format prompt dengan model target Anda—abstrak untuk Midjourney, literal untuk FLUX, berbasis tag untuk Stable Diffusion—dan selalu sertakan prompt negatif untuk menjaga kualitas output.
FAQ
Apakah reverse prompting dapat memulihkan prompt asli yang digunakan oleh kreator lain?
Tidak. Teknik ini merekonstruksi perkiraan deskriptif berdasarkan analisis visual. Model VLM yang berbeda memprioritaskan atribut yang berbeda, sehingga outputnya adalah rekonstruksi berkualitas tinggi—bukan metadata tersembunyi atau pemulihan keystroke.
Apakah teknologi image-to-prompt bekerja pada foto smartphone asli?
Ya. PromptsEra mencatat bahwa VLM dapat mengidentifikasi atribut dunia nyata seperti “golden hour lighting” atau lensa kamera tertentu dan menerjemahkan tekstur tersebut menjadi prompt untuk reinterpretasi artistik.
Apakah legal menggunakan prompt yang diekstrak dari karya seni berhak cipta?
Prompt adalah string teks pendek dan biasanya tidak dilindungi oleh hak cipta. Pendekatan etis adalah mengekstrak token gaya untuk menginformasikan karya orisinal Anda sendiri. Seperti yang ditunjukkan oleh PromptsEra, mencoba mereplikasi secara tepat karakter yang dilindungi dapat menimbulkan masalah hukum—gunakan alat ini untuk mempelajari teknik, bukan untuk menyalin.
Tinggalkan Balasan