画像をBeConverterにアップロードし、Vision-Language Model(VLM)でビジュアルをスタイルトークンに分解し、抽出されたプロンプトをMidjourney、Stable Diffusion、またはFLUXに貼り付ける。これが、あらゆるビジュアルを再現可能なAIプロンプトに変換する完全なワークフローである。推測は一切不要だ。
リバースプロンプトとは何か、BeConverterはどのように機能するのか?
リバースプロンプトは、ピクセルを生成モデルが理解できるテキストに変換する技術である。ゼロからプロンプトを書き、出力が参照画像と一致することを期待する代わりに、完成した画像から出発し、その見た目を定義するキーワード、照明条件、美学タグを正確に抽出する。
BeConverterはVision-Language Model(VLM)を使用して、画像の芸術的属性を分析する。モデルは画像を訓練データと比較し、レンダリングスタイル(3Dか油絵か)、照明セットアップ(ボリュメトリックかアンビエントか)、構図などの属性を分類する。その結果、任意の画像生成ツールに入力できる構造化されたテキストプロンプトが得られる。
VLMとOCRの違い:なぜ従来のスキャンではアートを読み取れないのか
光学式文字認識(OCR)はテキスト(文字、数字、レシートなど)を読み取る。一方、VLMは_アートディレクション_を読み取る。PromptsEraが説明しているように、OCRが標識上の「STOP」という文字を読み取るのに対し、VLMは八角形の形状、色あせた赤い塗料、被写界深度、太陽の角度などを検出する。これらはビジュアルの再現に不可欠な要素である。
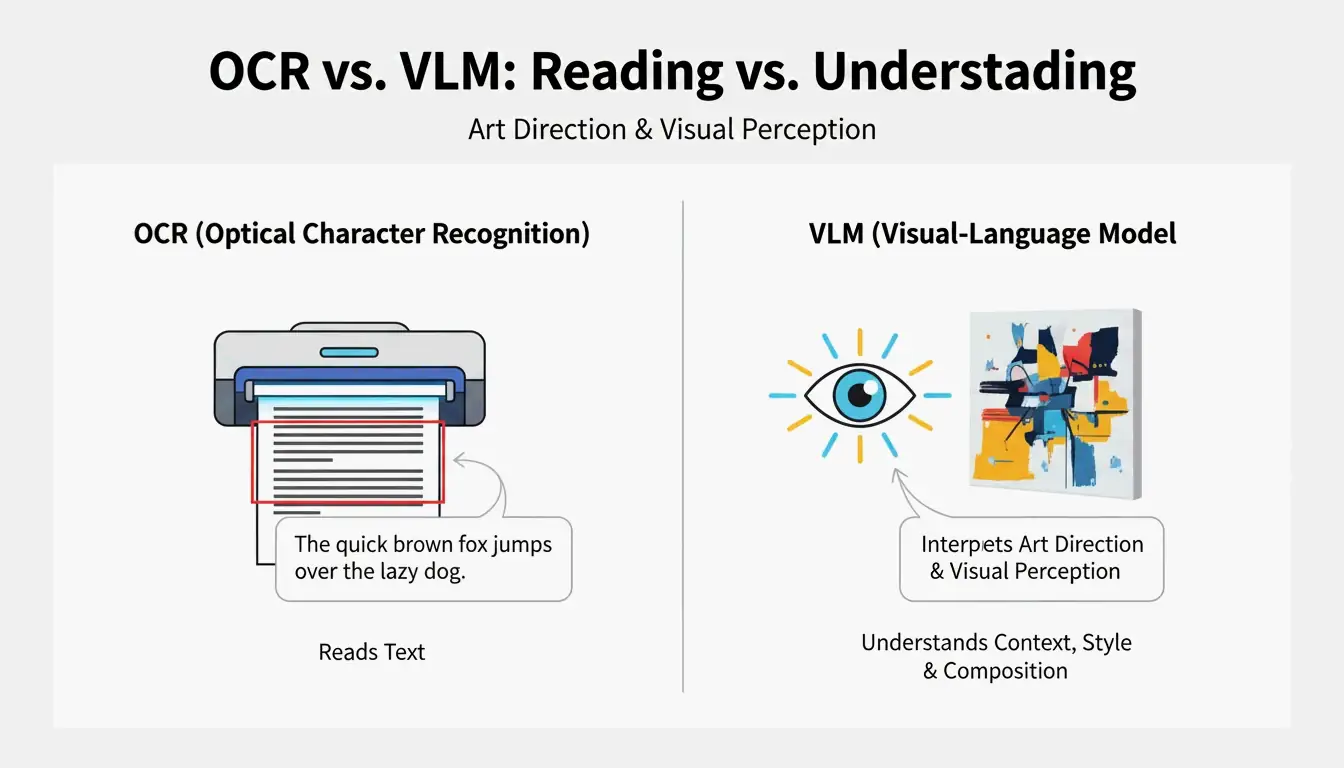
| 機能 | OCR | VLM |
|---|---|---|
| テキストの読み取り | 〇 | 限定付き |
| 照明の識別 | × | 〇 |
| 構図スタイルの検出 | × | 〇 |
| カラーグレーディングの抽出 | × | 〇 |
| プロンプト対応テキストの出力 | × | 〇 |
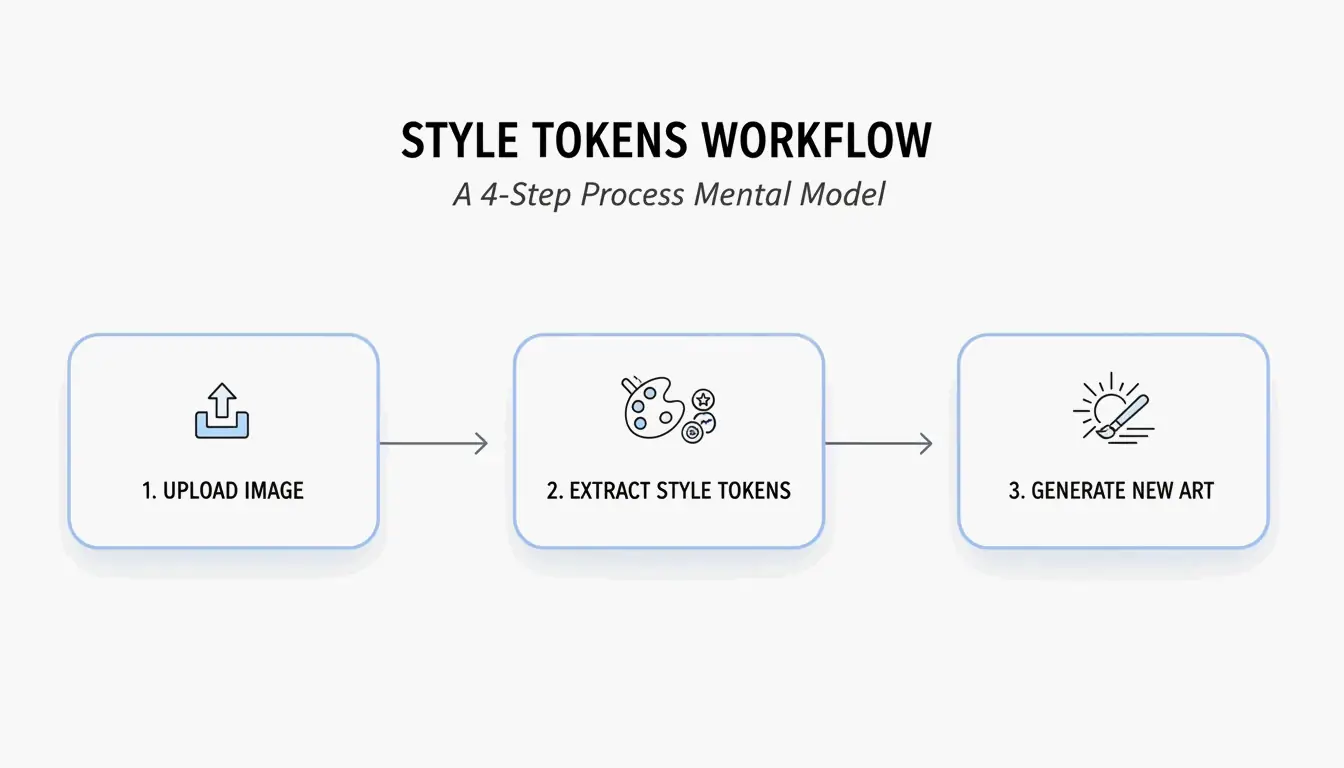
4ステップのワークフロー:BeConverterでAIプロンプトを作成する方法
PromptsEraのスタイルトークン分離戦略に基づき、以下の手順に従う:
- ソース画像をアップロードする — 高解像度のファイルを使用する。VLMが「ボリュメトリックライティング」や「35mmレンズの粒子感」といった微妙な属性を検出するには、鮮明なピクセルが必要である。
- インタロゲーターを選択する — 説明的で詩的なプロンプトにはCLIP Interrogatorを選択(Midjourneyに最適)、カンマ区切りのタグにはDeepDanbooruを選択(Stable Diffusionに最適)。
- スタイルトークンを分離する — 被写体トークン(例:「a cat」)を削除し、スタイルマーカー(例:「cyberpunk, neon rim lighting, 8k, cinematic depth of field」)のみを保持する。
- ジェネレーターに貼り付ける — クリーンアップされたトークンをMidjourney v7、Stable Diffusion、またはFLUXにコピーして生成する。
2026年モデル向けのプロンプト適応:FLUX vs. Midjourney
各モデルはプロンプトを異なる方法で解釈する。PromptsEraによると、「メランコリックな雰囲気」のような抽象的な説明はMidjourneyでうまく機能するが、FLUXでは機能しない。FLUXには「雨が窓を打つ暗い部屋、頭上の蛍光灯が長い影を落とす」のような具体的な空間的説明が必要である。
| プロンプトスタイル | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| 抽象/詩的 | 強い | 弱い | 普通 |
| 具体的/空間的 | 普通 | 強い | 普通 |
| カンマ区切りタグ | 普通 | 普通 | 強い |
| ネガティブプロンプト | 対応(--no) |
対応 | 対応 |
フランケンシュタイン戦略:複数画像からのスタイル統合
最も効果的なリバースエンジニアリング手法は、異なるソースからスタイルトークンを組み合わせることである。BeConverterを使って画像Aから照明を抽出し、画像Bから被写体のレンダリングを抽出し、それらを1つのプロンプトに統合する。
一貫した統合のための主要な制御項目:
- アスペクト比 — リバースツールは意図したキャンバスサイズを推測できないため、明示的に設定する(例:Midjourneyの場合
--ar 16:9)。 - ネガティブプロンプト — 常に「blurry, deformed, low quality」などの除外項目を追加する。リバースツールは_存在するもの_しか検出できない。欠落させるべきものを特定することはできない。
MIT金融工学研究所の所長であるAndrew Lo氏は次のように助言している:「常にLLMに、あなたは何について不確かですか?どんな情報が不足していますか?と問いなさい。」同じ原則を適用し、再構築したプロンプトの欠落を生成前に特定することが重要である。
BeConverter vs. Zemith vs. PromptShot:ツール比較(2026年)
| 機能 | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| インタロゲーターモード | CLIP + DeepDanbooru | マルチモデル(25種以上) | シングルパス |
| 無料デイリークレジット | あり | 100 | 無制限 |
| サインアップ必須 | なし | あり | なし |
| 最適な用途 | トークン分離 | オールインワンワークフロー | クイック抽出 |
| 出力形式 | 説明的 + タグ | モデル別 | プロンプト文字列 |
注目すべき追加オプション:
- Zemith — 2026年時点で30,000人以上のユーザー。Zemithによると、GPT-5.5を含む25種以上のモデルをサポートし、1日100クレジットを提供している。
- PromptShot AI — アカウント不要。PromptShot AIは、AIアートを素早く「再作成・改善」する必要があるクリエイター向けに5ステップのプロセスを提供している。
- Dreamina(GPT Image 2) — 1つのウィンドウで生成と編集が可能。Dailyhuntによると、GPT Image 2モデルはプロンプト生成直後にインペイントと照明調整をサポートしている。
まとめ
BeConverterを使ったリバースプロンプトは、あらゆる参照画像を数秒で構造化された再利用可能なAIプロンプトに変換する。画像をアップロードし、CLIPまたはDeepDanbooruでスタイルトークンを抽出し、芸術的属性を分離し、選択したジェネレーターに貼り付ける。最良の結果を得るには、ターゲットモデルに合わせてプロンプト形式を調整すること。Midjourneyには抽象的、FLUXには具体的、Stable Diffusionにはタグベースの形式を使い、出力品質を維持するために必ずネガティブプロンプトを含めること。
FAQ
リバースプロンプトで他のクリエイターが使用した元のプロンプトを正確に復元できるか?
いいえ。ビジュアル分析に基づく説明的な近似値を再構築するにすぎない。異なるVLMモデルは異なる属性を優先するため、出力は高品質な再構築であって、隠されたメタデータやキーストロークの復元ではない。
画像からプロンプトへの技術は、スマートフォンの実写写真でも機能するか?
はい。PromptsEraによると、VLMは「ゴールデンアワーの照明」や特定のカメラレンズなどの実世界の属性を識別し、それらのテクスチャを芸術的な再解釈のためのプロンプトに変換できる。
著作権で保護されたアートワークから抽出したプロンプトを使用することは合法か?
プロンプトは短いテキスト文字列であり、通常は著作権の対象とはならない。倫理的なアプローチは、スタイルトークンを抽出して自身のオリジナル作品の制作に活用することである。PromptsEraが指摘しているように、保護されたキャラクターを正確に複製しようとすると法的な問題が生じる可能性がある。これらのツールは技術を学ぶために使用し、コピーのために使用すべきではない。
コメントを残す