將圖片上傳至 BeConverter,讓其視覺語言模型(VLM)將視覺內容拆解為風格 token,再將擷取出的提示詞貼入 Midjourney、Stable Diffusion 或 FLUX。這就是將任何視覺作品轉化為可重現 AI 提示詞的完整流程——無需任何猜測。
什麼是反向提示詞?BeConverter 如何運作?
反向提示詞(Reverse Prompting)是將像素還原為生成模型能理解的文字描述。與其從零開始撰寫提示詞並期盼輸出結果匹配參考圖,你改從成品圖片出發,擷取定義其視覺風格的關鍵詞、光線條件與美學標籤。
BeConverter 使用視覺語言模型(VLM)來分析圖片的藝術屬性。模型會將你的照片與其訓練資料進行比對,分類各項屬性,例如渲染風格(3D 與油畫)、光線設定(體積光與環境光)以及構圖方式。最終產出的是一段結構化的文字提示詞,可直接輸入任何圖像生成器。
VLM 與 OCR:為什麼標準掃描無法解讀藝術?
光學字元辨識(OCR)讀取的是文字——字母、數字、收據。而 VLM 讀取的是藝術方向。正如 PromptsEra 所解釋的,當 OCR 看到路牌上的「STOP」字樣時,VLM 能偵測到八角形的形狀、褪色的紅漆、景深效果,以及陽光的角度——這些都是視覺重現不可或缺的細節。
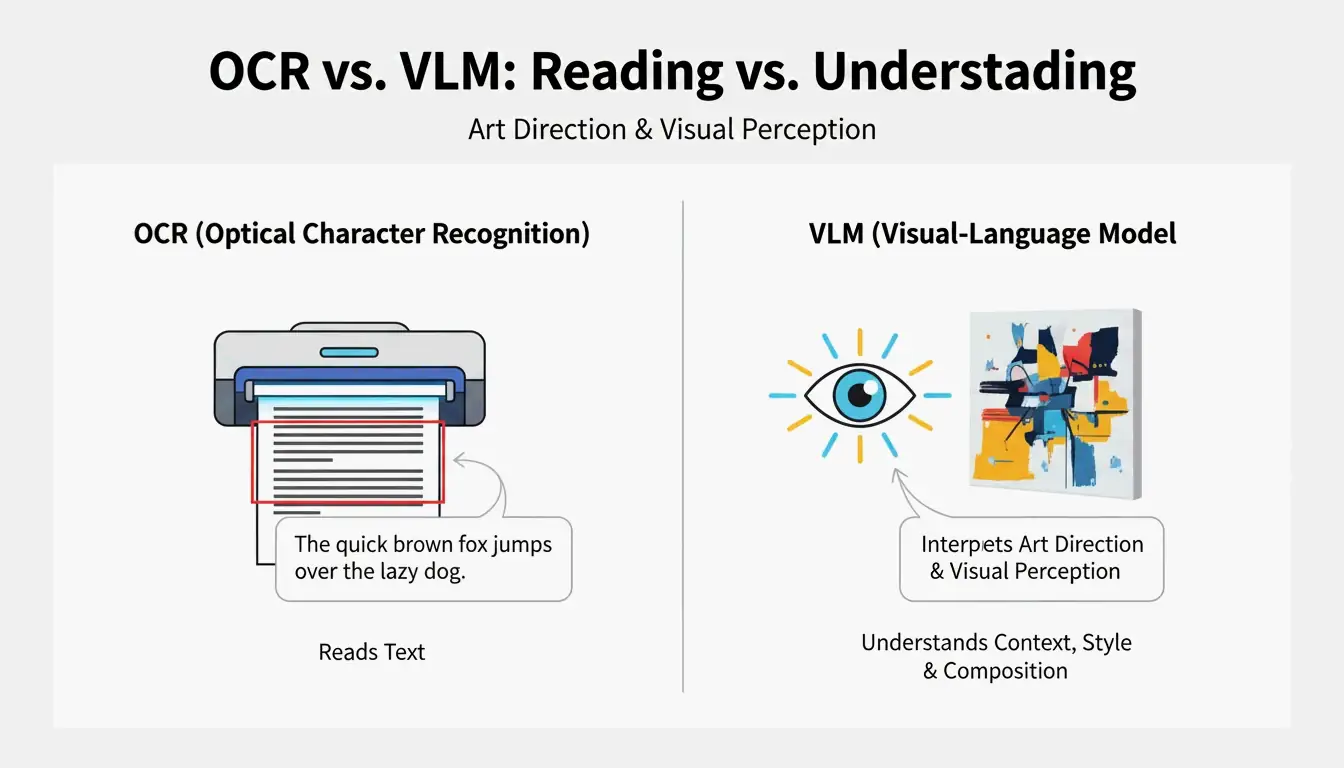
| 能力 | OCR | VLM |
|---|---|---|
| 讀取文字 | 是 | 有限 |
| 辨識光線 | 否 | 是 |
| 偵測構圖風格 | 否 | 是 |
| 擷取色彩分級 | 否 | 是 |
| 輸出可作為提示詞的文字 | 否 | 是 |
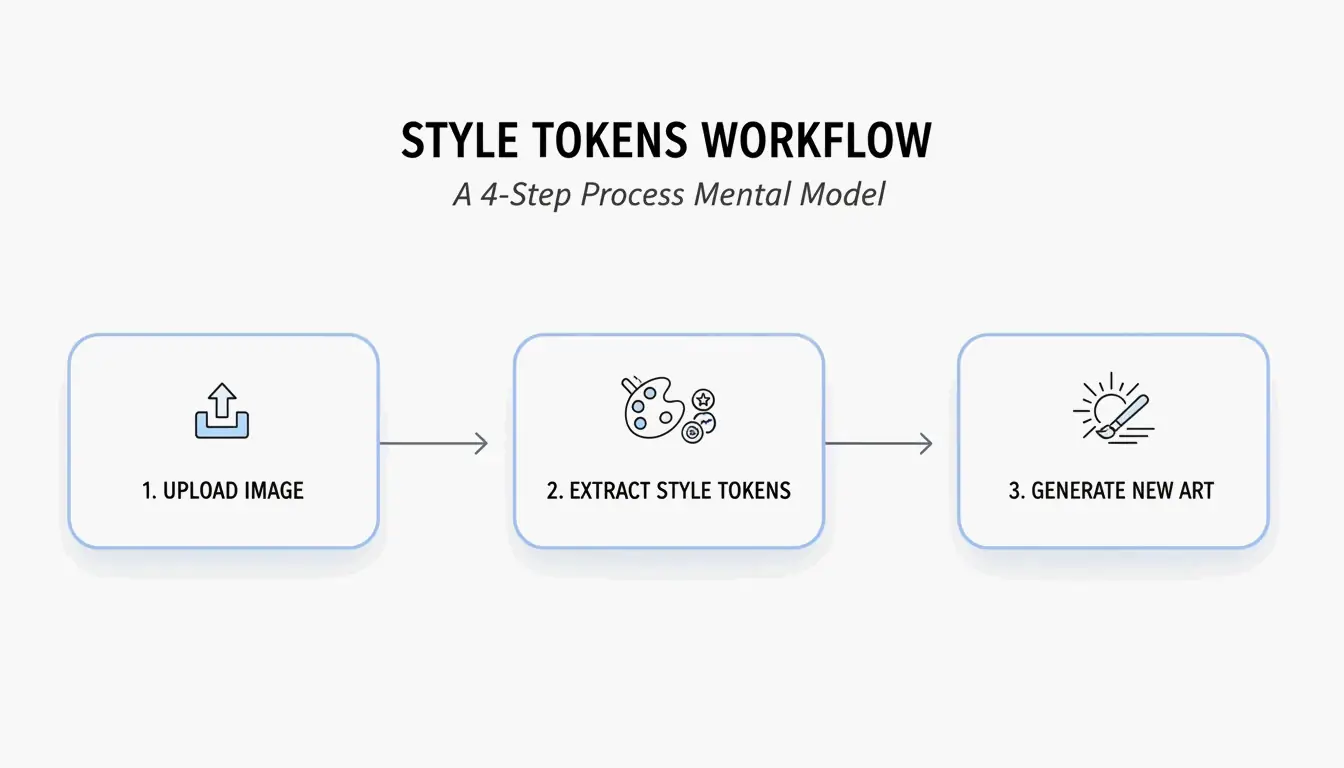
4 步驟流程:如何使用 BeConverter 進行 AI 提示詞工程
根據 PromptsEra 提出的風格 Token 隔離策略,請依序執行以下步驟:
- 上傳來源圖片 — 使用高解析度檔案。VLM 需要清晰的像素才能偵測「體積光」或「35mm 鏡頭顆粒感」等細微屬性。
- 選擇你的解析器 — 選擇 CLIP Interrogator 以取得描述性、詩意的提示詞(適用於 Midjourney),或選擇 DeepDanbooru 以取得逗號分隔的標籤(適用於 Stable Diffusion)。
- 隔離風格 token — 刪除主體 token(例如「一隻貓」),只保留風格標記(例如「cyberpunk, neon rim lighting, 8k, cinematic depth of field」)。
- 貼入你的生成器 — 將清理後的 token 複製到 Midjourney v7、Stable Diffusion 或 FLUX 並開始生成。
針對 2026 年模型的提示詞調適:FLUX 與 Midjourney 的差異
每個模型對提示詞的解讀方式不同。PromptsEra 指出,像「憂鬱氛圍」這類抽象描述在 Midjourney 中效果良好,但在 FLUX 中則無法生效——FLUX 需要字面的空間描述,例如「昏暗房間中雨水拍打窗戶,頭頂螢光燈投下長長的陰影」。
| 提示詞風格 | Midjourney v7 | FLUX | Stable Diffusion |
|---|---|---|---|
| 抽象/詩意 | 強 | 弱 | 中等 |
| 字面/空間描述 | 中等 | 強 | 中等 |
| 逗號分隔標籤 | 中等 | 中等 | 強 |
| 負向提示詞 | 支援(--no) |
支援 | 支援 |
科學怪人策略:合併多張圖片的風格
最有效的反向工程技巧,是將來自不同來源的風格 token 進行合併。使用 BeConverter 從圖片 A 擷取光線風格,從圖片 B 擷取主體渲染方式,然後將兩者合併為單一提示詞。
確保合併一致性的關鍵控制項:
- 長寬比 — 明確設定(例如 Midjourney 使用
--ar 16:9),因為反向工具無法推斷你預期的畫布尺寸。 - 負向提示詞 — 務必加入排除條件,例如「blurry, deformed, low quality」。反向工具只能偵測存在的元素,無法判斷應該排除什麼。
正如 MIT 金融工程實驗室主任 Andrew Lo 所建議的:「永遠要問 LLM:你不確定的是什麼?你缺少了什麼資訊?」將同樣的原則應用於此——在生成之前,先找出你重建的提示詞中的缺口。
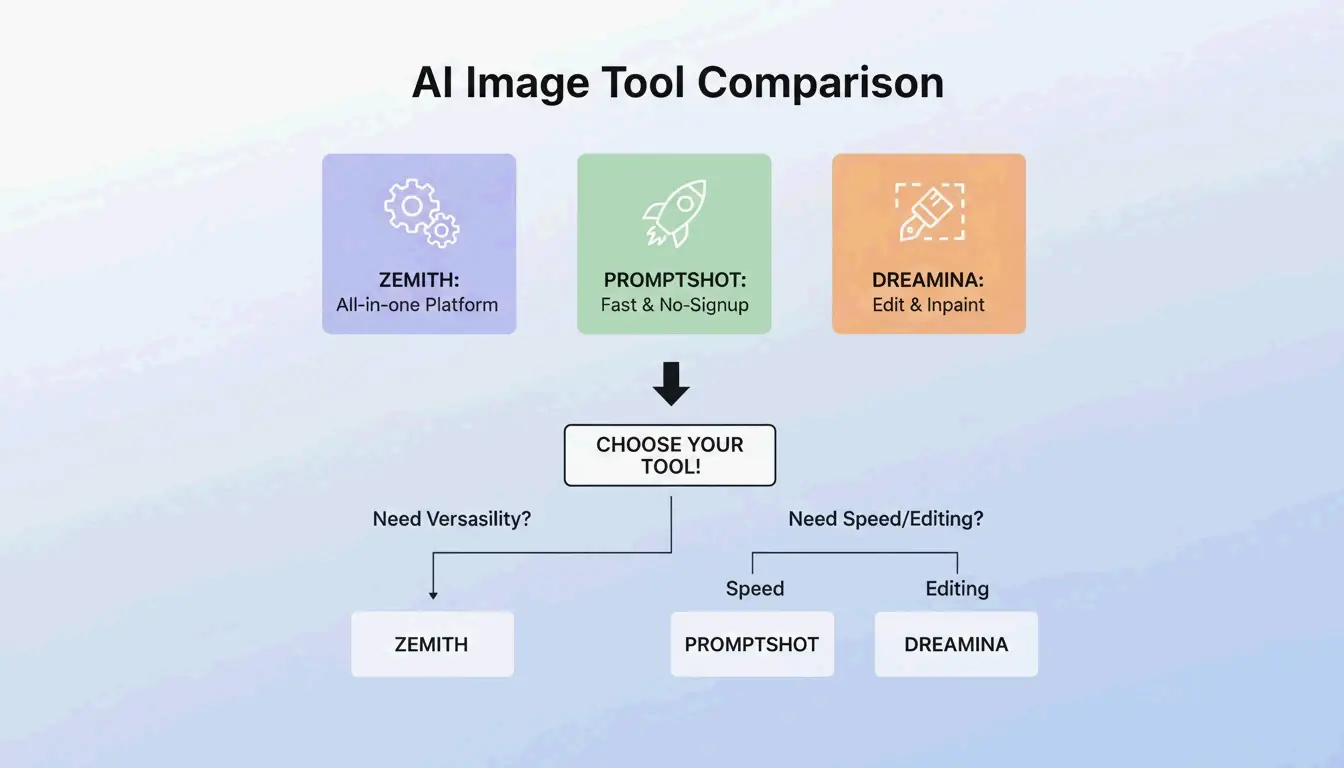
BeConverter 與 Zemith 與 PromptShot:工具比較(2026)
| 功能 | BeConverter | Zemith | PromptShot AI |
|---|---|---|---|
| 解析器模式 | CLIP + DeepDanbooru | 多模型(25+ 以上) | 單次掃描 |
| 每日免費額度 | 有 | 100 | 無限 |
| 需要註冊 | 否 | 是 | 否 |
| 最適合 | Token 隔離 | 一站式工作流程 | 快速擷取 |
| 輸出格式 | 描述 + 標籤 | 依模型客製化 | 提示詞字串 |
其他值得留意的選項:
- Zemith — 截至 2026 年擁有超過 30,000 名用戶。根據 Zemith 的資料,它支援 25 種以上的模型,包括 GPT-5.5,並提供每日 100 點免費額度。
- PromptShot AI — 不需帳號即可使用。PromptShot AI 提供一套 5 步驟流程,專為需要快速「重現與改進」AI 藝術作品的創作者設計。
- Dreamina(GPT Image 2) — 在同一視窗中生成與編輯。根據 Dailyhunt 的報導,GPT Image 2 模型支援在提示詞生成後直接進行內部修補與光線調整。
結論
透過 BeConverter 進行反向提示詞工程,能在數秒內將任何參考圖片轉化為結構化、可重複使用的 AI 提示詞。上傳圖片、使用 CLIP 或 DeepDanbooru 擷取風格 token、隔離藝術屬性,再貼入你選擇的生成器即可。為獲得最佳效果,請根據目標模型調整提示詞格式——Midjourney 用抽象描述、FLUX 用字面描述、Stable Diffusion 用標籤格式——並務必加入負向提示詞以維持輸出品質。
常見問題
反向提示詞能還原其他創作者使用的原始提示詞嗎?
不能。它根據視覺分析重建一段描述性的近似內容。不同的 VLM 模型側重不同的屬性,因此輸出結果是高品質的重建,而非隱藏的元資料或按鍵記錄還原。
圖片轉提示詞技術適用於真實的手機照片嗎?
適用。PromptsEra 指出,VLM 能辨識真實世界的屬性,例如「黃金時刻光線」或特定相機鏡頭,並將這些質感轉化為可供藝術重新詮釋的提示詞。
使用從受版權保護的藝術作品中擷取的提示詞合法嗎?
提示詞是簡短的文字字串,通常不受版權保護。合乎道德的做法是擷取風格 token 來啟發你自己的原創作品。正如 PromptsEra 所指出的,試圖完全複製受保護的角色可能引發法律問題——請將這些工具用於學習技術,而非抄襲。
發佈留言