क्या आपको किसी स्प्रेडशीट, CSV या JSON फ़ाइल को साफ़ Markdown टेबल में बदलना है? 2026 में यह प्रक्रिया काफी सरल हो गई है — सही टूल का चुनाव इस बात पर निर्भर करता है कि आप केवल एक बार का कन्वर्ज़न कर रहे हैं या पैमाने पर डॉक्यूमेंटेशन को ऑटोमेट कर रहे हैं।
यह गाइड हर स्थिति के लिए सर्वश्रेष्ठ टूल्स को कवर करती है: मैन्युअल काम के लिए विज़ुअल एडिटर, ऑटोमेशन के लिए CLI टूल्स, और आपके कोडबेस के साथ डॉक्यूमेंटेशन को सिंक रखने के लिए CI/CD इंटीग्रेशन।
एक नज़र में टॉप टूल्स
| Tool | Best For | Type | Key Strength |
|---|---|---|---|
| TableGenerator.com | Quick visual edits | Web (client-side) | Grid-based editor, alignment controls |
| AnywayData | Messy JSON files | Web / library | Flattening nested structures, AST parsing |
| MarkItDown (Microsoft) | Excel/Word automation | Python CLI | Preserves headers and table grids from Office files |
| Pandoc | Multi-format conversion | CLI | Supports dozens of formats, stable at scale |
| EaseCloud | Excel → GFM | Web | Simple browser-based converter |
| GoConverter | Excel → GFM | Web | Fast conversion with alignment options |
DasRoot (2026) के अनुसार, आधुनिक Markdown टूल्स मध्यम आकार वाले डेटासेट के लिए 15–30 टेबल प्रति सेकंड प्रोसेस कर सकते हैं — और सबसे अच्छे टूल्स क्लाइंट-साइड प्रोसेसिंग का उपयोग करते हैं, यानी आपका डेटा कभी आपका ब्राउज़र नहीं छोड़ता।
GFM कम्प्लायंस क्यों मायने रखता है
GitHub Flavored Markdown (GFM) वह विशिष्ट डायलेक्ट है जिसका उपयोग GitHub, GitLab और Discord करते हैं। मूल Markdown स्पेक में टेबल का समर्थन ही नहीं था — GFM ने ही वह परिचित “pipe-and-dash” सिंटैक्स जोड़ा। GFM-कम्प्लायंट जनरेटर यह सुनिश्चित करता है कि आपकी टेबल्स बोल्ड हेडर्स और अलाइन कॉलम के साथ सही ढंग से रेंडर हों, न कि कच्चे टेक्स्ट की तरह दिखें।

Excel और CSV को GFM में कैसे बदलें
यह प्रक्रिया दो चरणों में होती है:
- CSV में एक्सपोर्ट करें — अपनी Excel या Google Sheets फ़ाइल को CSV के रूप में सेव करें। यह भारी फ़ॉर्मेटिंग हटा देता है लेकिन डेटा ग्रिड को बनाए रखता है।
- कन्वर्ट करें — GFM कोड जनरेट करने के लिए EaseCloud या GoConverter जैसे ब्राउज़र-आधारित टूल का उपयोग करें।
कॉलम अलाइनमेंट
GFM अलाइनमेंट को सेपरेटर रो (हेडर के नीचे की लाइन) के ज़रिए कंट्रोल करता है:
| Syntax | Alignment |
|---|---|
:--- |
Left-aligned (default) |
---: |
Right-aligned |
:---: |
Center-aligned |
पाइप कैरेक्टर को एस्केप करना
Markdown कॉलम के किनारों को चिह्नित करने के लिए | का उपयोग करता है। यदि आपके डेटा में पाइप है (जैसे किसी कोड स्निपेट या फॉर्मूले में), तो यह टेबल को तोड़ देगा। इसे इन तरीकों से एस्केप करें:
- HTML entity:
| - Backslash:
\| - Code backticks:
`|`
बड़े डेटासेट को हैंडल करना (100+ Rows)
100 पंक्तियों से अधिक वाले डेटासेट के लिए वेब-आधारित विज़ुअल एडिटर लैग कर सकते हैं। आधुनिक कन्वर्टर रिस्पॉन्सिव बने रहने के लिए इंक्रीमेंटल पार्सिंग का उपयोग करते हैं। AnywayData के अनुसार, “युग्मक क्रमचयी डेटा लॉजिक” का उपयोग आवश्यक टेस्ट केसेस को 90–99% तक कम कर सकता है, जो जटिल कॉन्फ़िगरेशन को डॉक्यूमेंट करते समय मददगार है।
वास्तव में बड़े डेटासेट के लिए, कई टेबल्स में विभाजित करने या Markdown वर्ज़न के साथ-साथ डाउनलोडेबल CSV लिंक देने पर विचार करें।
JSON को GFM में बदलना: नेस्टेड डेटा को फ्लैट करना
JSON हायरार्किकल होता है — डेटा रूसी गुड़िया की तरह नेस्टेड होता है। Markdown टेबल्स फ्लैट 2D ग्रिड होती हैं। कन्वर्ज़न के लिए फ्लैटनिंग लॉजिक चाहिए:
user.address.city → "User Address City" (single column header)
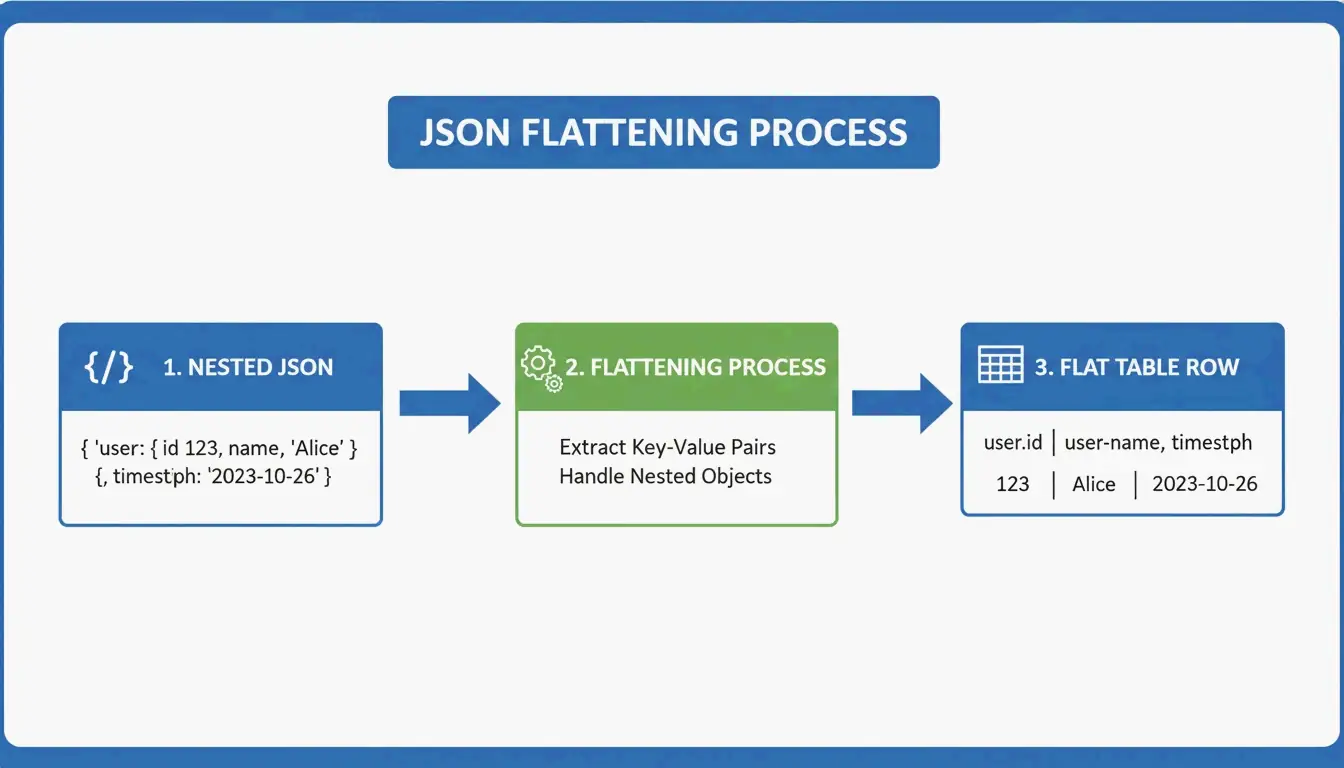
AnywayData का Grid Table Editor यहाँ बेहतरीन है — यह आपको JSON इंपोर्ट करने और नेस्टेड लेयर्स को फ्लैट करने का तरीका मैन्युअली कंट्रोल करने देता है। कन्वर्ज़न की क्वालिटी इस बात पर निर्भर करती है कि टूल साधारण टेक्स्ट पैटर्न मैचिंग के बजाय AST (Abstract Syntax Tree) कंस्ट्रक्शन का उपयोग करता है या नहीं। AST-आधारित पार्सर डेटा स्ट्रक्चर का लॉजिकल मैप बनाते हैं, जो गहरी नेस्टिंग और असंगत स्कीमा को कहीं अधिक सटीकता से हैंडल करते हैं।
CI/CD के साथ ऑटोमेट करना
इंजीनियरिंग टीमों के लिए, मैन्युअल कन्वर्ज़न समय की बर्बादी है। टेबल जनरेशन को अपने CI/CD pipeline में इंटीग्रेट करना सुनिश्चित करता है कि README फ़ाइलें अपने आप अपडेट रहें:
- बिल्ड प्रक्रिया के दौरान JSON API रिस्पॉन्स को GFM में बदलें
- डॉक्यूमेंटेशन को कोड की तरह ट्रीट करें — यह आपके डेटा के बदलने पर अपडेट होता है
- अपने रेपो में पुरानी या गलत जानकारी वाली आम समस्या को रोकें
Terraform-docs v0.17.0 (2026) जैसे टूल्स सीधे README फ़ाइलों में रिसोर्स टेबल्स अपने आप इंजेक्ट करते हैं — यह साबित करता है कि इंफ्रास्ट्रक्चर-लेवल डॉक्यूमेंटेशन के लिए CLI टूल्स अक्सर वेब इंटरफ़ेस से बेहतर होते हैं।
MarkItDown बनाम Pandoc: आपको किसका उपयोग करना चाहिए?
| Factor | MarkItDown (Microsoft) | Pandoc |
|---|---|---|
| Optimized for | Office files (Excel, Word) | Universal document conversion |
| Markdown flavors | GFM-focused | CommonMark, GFM, and many others |
| Best for | Quick XLSX → GitHub table | Multi-format, high-volume CLI work |
| Latest version | 2026 | 3.9.0.2 (stable) |
| Speed | Faster for single Office files | Better for batch processing |
| Use when | You need one Excel file converted | You need to convert between dozens of formats |
ज़्यादातर डेवलपर्स के लिए, MarkItDown सामान्य स्थिति (Excel → GitHub table) के लिए तेज़ है। Pandoc तब बेहतर विकल्प है जब आप कई डॉक्यूमेंट फ़ॉर्मेट के साथ जुगाड़ कर रहे हों या बड़े पैमाने पर बैच कन्वर्ज़न चला रहे हों।
निष्कर्ष
2026 में डेटा को GFM टेबल्स में बदलना मात्रा और वर्कफ़्लो का मामला है:
- एक बार के एडिट → विज़ुअल कंट्रोल के लिए TableGenerator.com या AnywayData
- आवर्ती Office कन्वर्ज़न → अपने Python वर्कफ़्लो में इंटीग्रेटेड MarkItDown
- मल्टी-फ़ॉर्मेट या हाई-वॉल्यूम → CLI बैच प्रोसेसिंग के लिए Pandoc
- इंफ्रास्ट्रक्चर डॉक्स → terraform-docs या कस्टम स्क्रिप्ट्स के साथ CI/CD ऑटोमेशन
मुख्य सिद्धांत: डॉक्यूमेंटेशन तब अपडेट होना चाहिए जब आपका डेटा अपडेट हो। कन्वर्ज़न को ऑटोमेट करना पुरानी टेबल्स को रोकता है और आपके प्रोजेक्ट के डॉक्यूमेंटेशन को भरोसेमंद बनाए रखता है।
FAQ
Markdown टेबल सेल के भीतर पाइप कैरेक्टर (|) को कैसे एस्केप करें?
लिटरल पाइप के बजाय HTML entity | का उपयोग करें। वैकल्पिक रूप से, यदि आपका GFM पार्सर सपोर्ट करता है तो बैकस्लैश एस्केप \| का उपयोग करें, या कंटेंट को कोड बैकटिक्स में रैप करें। तीनों तरीके पाइप को कॉलम सेपरेटर के रूप में इंटरप्रेट होने से रोकते हैं।
क्या GFM मर्ज्ड सेल्स या मल्टी-लाइन कंटेंट को सपोर्ट करता है?
नहीं। स्टैंडर्ड GFM colspan या rowspan को सपोर्ट नहीं करता। हर सेल स्वतंत्र होना चाहिए। किसी सेल के भीतर मल्टी-लाइन कंटेंट के लिए, डेटा को एक ही रो में रखते हुए लाइन ब्रेक थोपने के लिए HTML <br> टैग का उपयोग करें।
100 पंक्तियों से अधिक वाले डेटासेट के लिए सबसे अच्छा तरीका क्या है?
वेब-आधारित विज़ुअल एडिटर छोड़ दें (ये लैग करेंगे)। इसके बजाय MarkItDown या Pandoc जैसे CLI टूल्स का उपयोग करें। यदि परिणामी टेबल एक ही पेज के लिए बहुत बड़ी है, तो उसे कई टेबल्स में विभाजित करें या पढ़ने की सुविधा बनाए रखने के लिए डाउनलोडेबल CSV फ़ाइल का लिंक दें।
प्रातिक्रिया दे