
Hver moderne database, distribuerte system og API bruker unike identifikatorer — og i 2026 har standarden som styrer dem endret seg fundamentalt. En UUID (Universally Unique Identifier, universelt unik identifikator) er en 128-bits etikett som kan identifisere informasjon på tvers av datasystemer uten noen sentral koordinering. Under den nye RFC 9562 (som erstattet RFC 4122 i mai 2024) har landskapet endret seg: UUID v4 er fortsatt det førstevalget for tilfeldige ID-er, men UUID v7 er nå den anbefalte standarden for primærnøkler i databaser, fordi dens tidsordnede struktur forhindrer fragmentering av B-tre-indekser.
Denne guiden dekker hele bildet: hvordan UUID-er fungerer, hvilken versjon som bør brukes når, og hvordan de implementeres riktig.
Forstå RFC 9562: den moderne UUID-standarden
En UUID er et 128-bits tall som praktisk talt er garantert unikt — uten noen sentral autoritet. Ifølge Wikipedia er sjansen for at to UUID-er kolliderer så nær null at det anses umulig for virkelige applikasjoner. Ulike team kan merke data uavhengig, trygge på at ID-ene deres ikke vil krasje.
I mai 2024 publiserte IETF RFC 9562 og pensjonerte den gamle RFC 4122. Oppdateringen var et svar på kravene fra moderne distribuerte systemer, som trengte ID-er som både var unike og sorterbare etter tid. Tre nye versjoner ble introdusert: v6, v7 og v8.
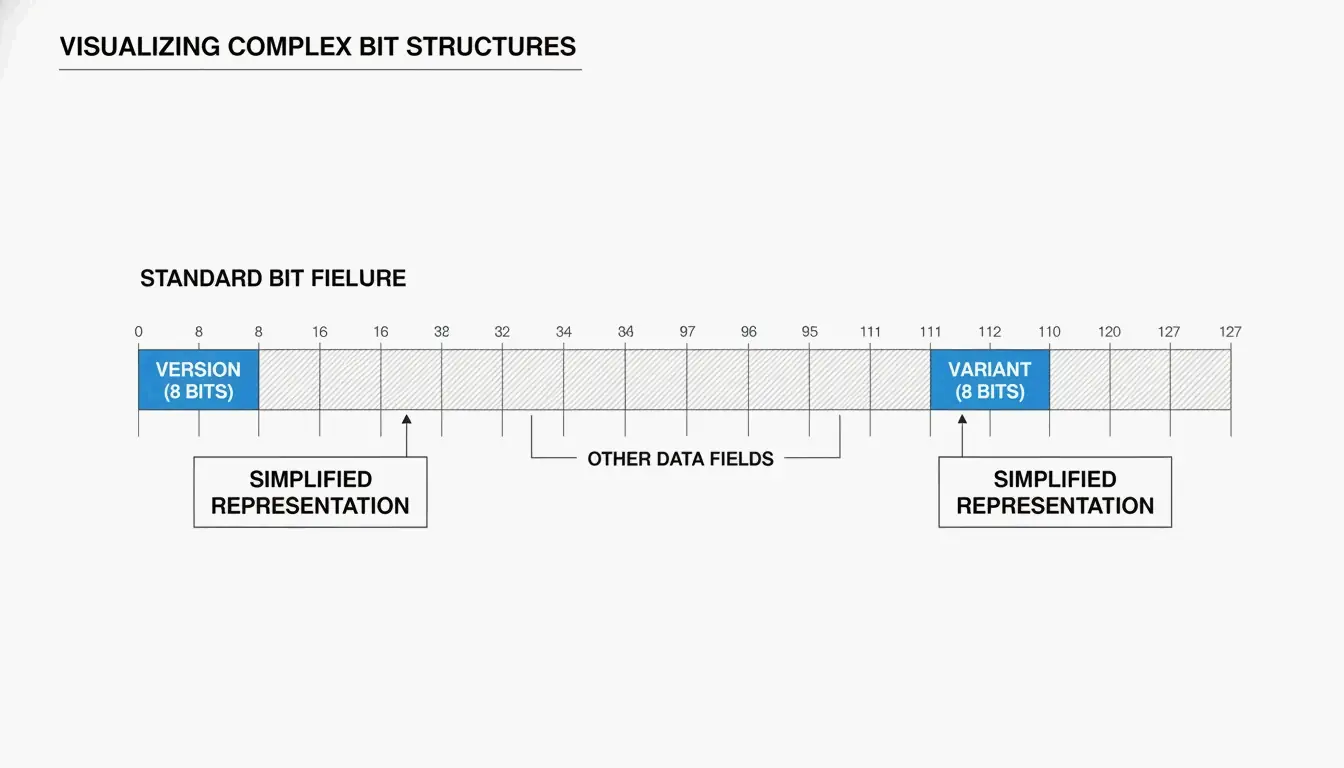
Anatomien til en UUID: versjoner og varianter
Du vil typisk se en UUID som 32 heksadesimale tegn delt inn i fem grupper med bindestreker (8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
To nøkkelfelt forteller deg hvordan UUID-en ble generert:
| Felt | Plassering | Hva det forteller deg |
|---|---|---|
| Versjonsbiter | De første 4 bitene i den 7. byten (første tegn i den 3. gruppen) | Hvilken algoritme som ble brukt (f.eks. «4» = v4, «7» = v7) |
| Variantbiter | 9. byte | UUID-varianten — RFC 9562 bruker et 10-bitmønster |
Som SnapUtils forklarer, skiller variantbitene moderne RFC 9562-UUID-er fra eldre Apollo- eller Microsoft-formater.
Hvorfor UUID v7 er den nye gullstandarden for databaser
Den største ulempen med UUID v4 er at den er helt tilfeldig. Når den brukes som primærnøkkel i en B-tre-indeks, må databasen sette inn nye rader på uforutsigbare posisjoner. Ifølge CreateUUID forårsaker dette «sidesplitting» (page splits) — databasen må stadig reorganisere data for å gjøre plass, noe som gir tregere skriving og bortkastet minne.
UUID v7 løser dette ved å plassere et 48-bits Unix Epoch-tidsstempel (millisekundpresisjon) i starten av ID-en. Dette gjør ID-ene monotont økende — nye er alltid større enn gamle. Databasen kan ganske enkelt legge til på slutten av indeksen, noe som gir deg ytelsen til et sekvensielt heltall kombinert med den globale unikheten til en UUID.
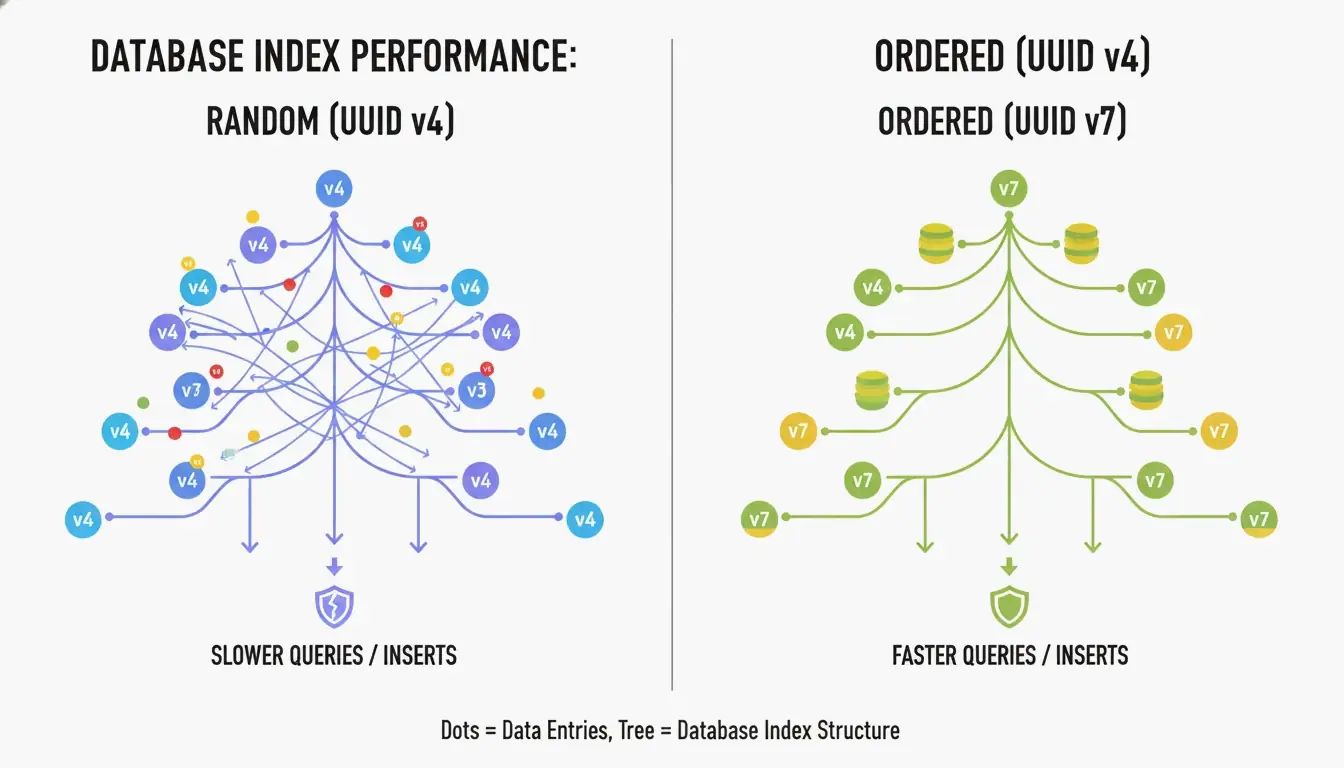
Hvordan UUID v7 balanserer tid og entropi
UUID v7 fyller de resterende 74 bitene med en CSPRNG (kryptografisk sikker pseudotilfeldig tallgenerator). Ifølge Wikipedia måtte du generere omtrent 1 milliard UUID-er per sekund i 85 år for å nå en 50 % sannsynlighet for kollisjon. For enhver virkelig applikasjon er UUID v7 i praksis kollisjonsfri.
Beste praksis for lagring: Binary(16) vs. String(36)
Hvordan du lagrer UUID-er er like viktig som hvilken versjon du bruker:
| Lagringsformat | Plass | Indeksytelse | Anbefaling |
|---|---|---|---|
| Binary(16) | 16 byte | Høy (kompakt) | Beste praksis |
| Innebygd UUID-type | 16 byte | Høy (optimalisert) | Best for PostgreSQL |
| Streng (Char 36) | 36–72 byte | Lav (fragmentert) | Unngå |
SnapUtils anbefaler å alltid bruke innebygde typer i stedet for strenger. I PostgreSQL lagrer den innebygde uuid-typen data i et kompakt 16-bytes binærformat, samtidig som den fortsatt støtter standard strengbaserte spørringer.
UUID vs. GUID: Er det en forskjell?
En GUID (Globally Unique Identifier, globalt unik identifikator) er Microsofts implementasjon av UUID-standarden. Historisk var det en forskjell i byte-rekkefølge (endianness) — tidlige Microsoft GUID-er brukte little-endian for de tre første feltene, mens standard UUID-er brukte big-endian (nettverksbyte-rekkefølge) (SnapUtils).
I 2026 er dette for det meste en navnekonvensjon. Under RFC 9562 fungerer de identisk. En Guid.NewGuid() i .NET er fullt ut kompatibel med en uuid.uuid4() i Python. Du vil høre «GUID» i Windows/Azure-kretser og «UUID» i Linux- og åpen kildekode-miljøer.
Implementere moderne UUID-er: språk for språk
| Språk | UUID v4 | UUID v7 |
|---|---|---|
| Python | Innebygd uuid-modul |
uuid6– eller uuid7-pakke |
| JavaScript | crypto.randomUUID() |
uuid npm-pakke (v10+) |
| PostgreSQL | gen_random_uuid() (PG 13+) |
Innebygd uuidv7() (PG 17+) eller utvidelser |
| .NET | Guid.NewGuid() |
Fellespakker |
| Rust | uuid-crate (v1.7+) |
uuid-crate med v7-funksjon |
Deterministiske ID-er: UUID v5
Hvis du trenger samme ID hver gang for en gitt inndata (som en URL eller et brukernavn), bruk UUID v5. Den hasher et navnerom-UUID og en navnestreng med SHA-1 — perfekt for deduplisering når du ikke kan spørre en sentral database.
Personvernbringen fra UUID v1
UUID v1 bruker et tidsstempel og datamaskinens MAC-adresse. Den har i stor grad blitt forlatt fordi den lekker maskinvareinformasjon. Et kjent eksempel: skaperen av Melissa-viruset ble tatt fordi UUID-ene i infiserte Word-dokumenter inneholdt hans spesifikke MAC-adresse.
Avansert RFC 9562: v6, v8 og spesial-UUID-er
RFC 9562 la til spesialiserte versjoner for nisjebehov i distribuerte systemer:
| Versjon | Formål | Når den skal brukes |
|---|---|---|
| v6 | Omordnet v1-tidsstempel — sorterbar samtidig som v1s presisjon beholdes | Migrering av eldre v1-systemer |
| v8 | Tilpasset — 122 biter for utviklerdefinerte data | Eksperimentelle eller leverandørspesifikke skjemaer |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Null-plassholder |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
Marke-er for endepunkt for område |
Konklusjon
RFC 9562 har oppdatert unike identifikatorer for den moderne sky-æraen. Den praktiske veiledningen:
- Database-primærnøkler → Bruk UUID v7 for tidsordnede, fragmenteringsfrie innsettinger
- Generell tilfeldighet → UUID v4 er fortsatt helt i orden
- Deduplisering → UUID v5 gir deg deterministiske ID-er
- Lagring → Bruk alltid Binary(16) eller innebygde UUID-typer, aldri strenger
Tiltak: Sjekk databaseskjemaene dine. Hvis du bruker UUID v4 som primærnøkkel i tabeller med millioner av rader, er migrering til UUID v7 en enkel endring som kan redusere indeksfragmenteringen betydelig og gjøre spørringer raskere.
Ofte stilte spørsmål
Er en UUID det samme som en GUID?
Funksjonelt, ja. En GUID er Microsofts implementasjon av UUID-standarden. Under RFC 9562 opptrer de identisk — du kan bruke dem om hverandre på tvers av .NET-, Java- og Python-applikasjoner.
Kan to UUID-er noen gang kollidere i et virkelig scenario?
Matematisk mulig, praktisk talt umulig. For UUID v4 måtte du generert omtrent 2,71 kvintillioner ID-er for å nå en 50 % sannsynlighet for kollisjon. Ifølge Generate-Random.org gir generering av 1 milliard UUID-er per sekund i 85 år deg kun 50 % sjanse for én enkelt kollisjon.
Bør jeg lagre UUID-er som strenger eller binært i databasen min?
Prioriter alltid Binary(16) eller innebygd UUID-type (tilgjengelig i PostgreSQL). En 36-tegns streng forbruker mer enn dobbelt så mye plass og bremser indeksoppslag og joins betydelig.SnapUtils påpeker at ytelsesfordelene i RFC 9562 maksimeres når lagringen forblir kompakt.
Når bør jeg bruke UUID v5 i stedet for UUID v4?
Bruk v5 når du trenger deterministiske ID-er — samme inndata gir alltid samme UUID, uten å spørre en database. Bruk v4 når du trenger full tilfeldighet og vil sikre at identifikatoren ikke kan tilbakeutvikles til sin kilde.
Legg igjen en kommentar