
모든 현대 데이터베이스, 분산 시스템, API는 고유 식별자를 사용합니다——그리고 2026년, 이들을 규정하는 표준이 근본적으로 바뀌었습니다. UUID(범용 고유 식별자, Universally Unique Identifier) 는 어떠한 중앙 조정 없이도 컴퓨터 시스템 전반에 걸쳐 정보를 식별할 수 있는 128비트 레이블입니다. 새로운 RFC 9562(2024년 5월 RFC 4122를 대체) 하에서 환경이 바뀌었습니다: UUID v4 는 여전히 무작위 ID의 대표적인 선택이지만, UUID v7 은 이제 시간 정렬 구조가 B-트리 인덱스 단편화를 방지하기 때문에 데이터베이스 기본 키의 권장 표준이 되었습니다.
이 가이드는 전체 그림을 다룹니다: UUID의 작동 방식, 언제 어느 버전을 쓸지, 그리고 올바른 구현 방법.
RFC 9562 이해: 현대 UUID 표준
UUID는 실질적으로 고유함이 보장되는 128비트 숫자입니다——중앙 기관이 필요 없습니다. 위키백과 에 따르면, 두 UUID가 충돌할 확률은 0에 가까워 현실 응용에서는 불가능한 것으로 간주됩니다. 서로 다른 팀이 독립적으로 데이터에 레이블을 붙이면서도 ID가 충돌하지 않을 것임을 확신할 수 있습니다.
2024년 5월, IETF는 RFC 9562 를 발표하며 구형 RFC 4122를 폐지했습니다. 이번 업데이트는 고유 하면서 시간으로 정렬 가능한 ID가 필요한 현대 분산 시스템의 요구에 대한 응답이었습니다. 세 가지 새 버전이 도입되었습니다: v6, v7, v8.
UUID의 해부: 버전과 배리언트
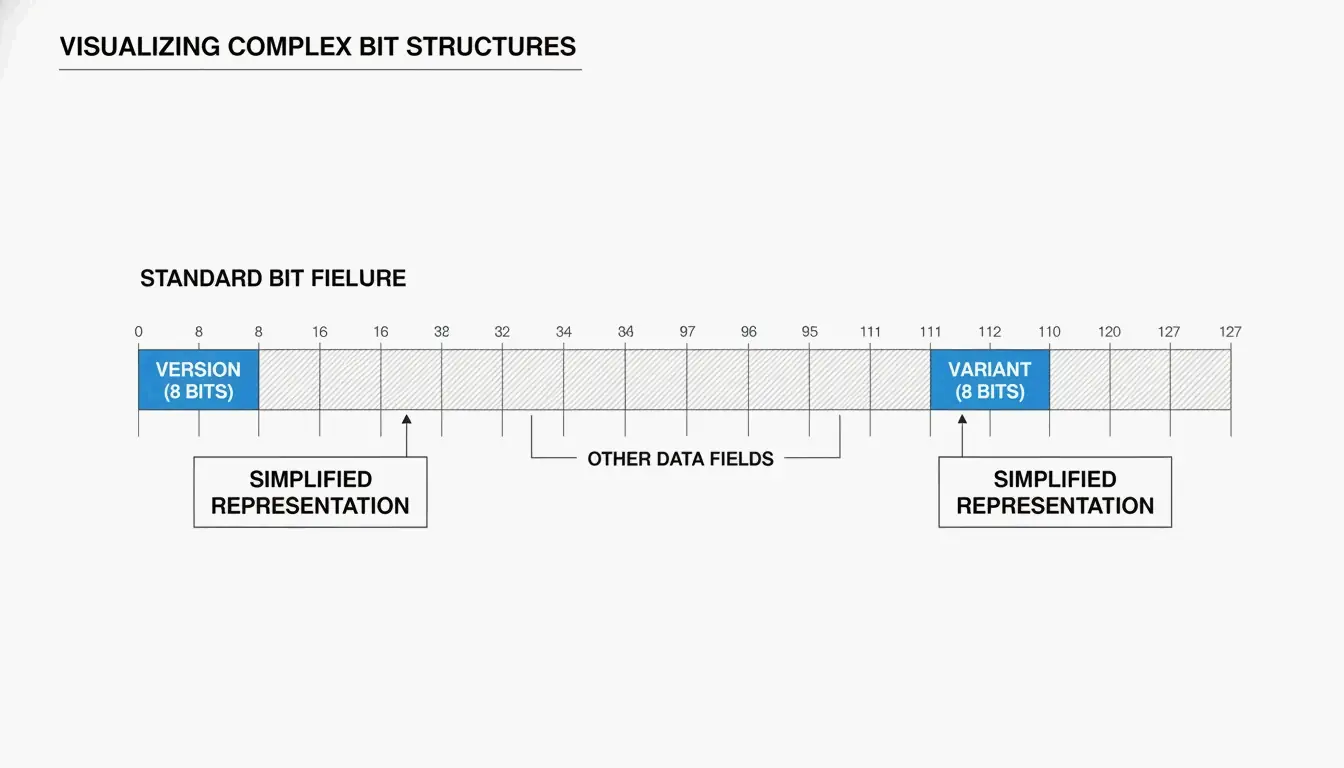
UUID는 일반적으로 32개의 16진수 문자가 하이픈으로 다섯 그룹으로 나뉜 형태(8-4-4-4-12)로 보입니다:
550e8400-e29b-41d4-a716-446655440000
^
version
두 핵심 필드가 UUID가 어떻게 생성되었는지 알려줍니다:
| 필드 | 위치 | 알려주는 것 |
|---|---|---|
| 버전 비트 | 7번째 바이트의 앞 4비트(세 번째 그룹의 첫 문자) | 어떤 알고리즘이 사용되었는지(예: “4” = v4, “7” = v7) |
| 배리언트 비트 | 9번째 바이트 | UUID 배리언트——RFC 9562는 10 비트 패턴을 사용 |
SnapUtils 가 설명하듯, 배리언트 비트는 현대 RFC 9562 UUID를 구형 Apollo나 Microsoft 형식과 구분합니다.
UUID v7이 데이터베이스의 새로운 황금 표준인 이유
UUID v4 의 가장 큰 단점은 완전히 무작위라는 점입니다. B-트리 인덱스 의 기본 키로 사용하면, 데이터베이스는 예측 불가능한 위치에 새 행을 삽입해야 합니다. CreateUUID 에 따르면, 이는 “페이지 분할(page splits)” 을 유발합니다——데이터베이스가 공간을 만들기 위해 데이터를 끊임없이 재구성해야 하여 쓰기가 느려지고 메모리가 낭비됩니다.
UUID v7 은 ID 시작 부분에 48비트 Unix 에포크 타임스탬프(밀리초 정밀도)를 배치해 이를 해결합니다. 이로 인해 ID는 단조 증가하게 됩니다——새 것이 항상 이전 것보다 큽니다. 데이터베이스는 인덱스 끝에 단순히 추가하기만 하면 되어, 순차 정수의 성능과 UUID의 전역 고유성을 동시에 얻을 수 있습니다.
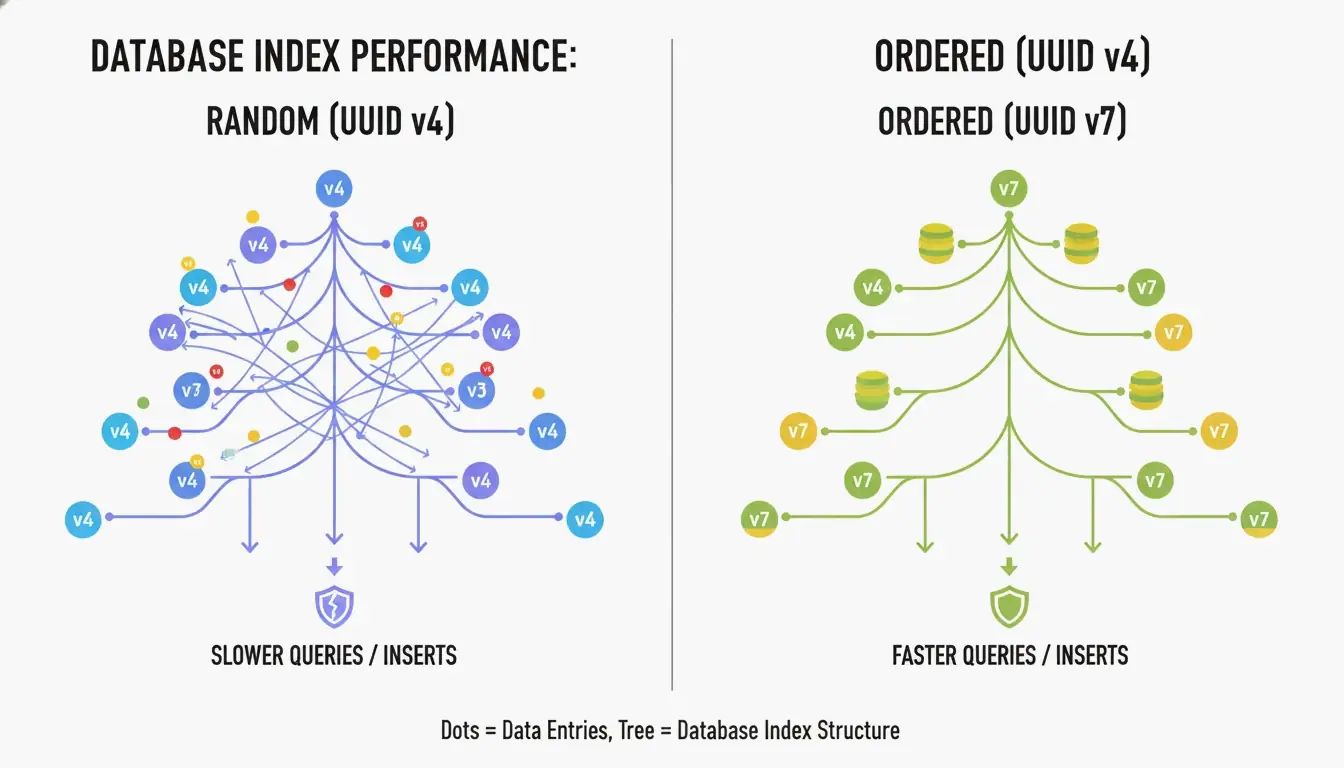
UUID v7이 시간과 엔트로피를 어떻게 균형 있게 하는가
UUID v7은 나머지 74비트를 CSPRNG(암호학적으로 안전한 의사 난수 생성기) 로 채웁니다. 위키백과 에 따르면, 50% 충돌 확률에 도달하려면 초당 약 10억 개의 UUID를 85년간 생성해야 합니다. 현실의 어떤 응용에서도 UUID v7은 사실상 충돌하지 않습니다.
저장 모범 사례: Binary(16) vs String(36)
UUID를 어떻게 저장하느냐는 어떤 버전을 쓰느냐만큼이나 중요합니다:
| 저장 형식 | 공간 | 인덱스 성능 | 권장 |
|---|---|---|---|
| Binary(16) | 16바이트 | 높음(컴팩트) | 모범 사례 |
| 네이티브 UUID 타입 | 16바이트 | 높음(최적화됨) | PostgreSQL에 최적 |
| 문자열(Char 36) | 36–72바이트 | 낮음(단편화) | 사용 금지 |
SnapUtils 는 문자열보다 항상 네이티브 타입을 사용할 것을 권장합니다. PostgreSQL 에서는 네이티브 uuid 타입이 표준 문자열 기반 쿼리를 지원하면서도 데이터를 컴팩트한 16바이트 바이너리 형식으로 저장합니다.
UUID vs GUID: 차이가 있나요?
GUID(전역 고유 식별자, Globally Unique Identifier) 는 UUID 표준의 Microsoft 구현입니다. 역사적으로 바이트 순서(엔디언)에 차이가 있었습니다——초기 Microsoft GUID는 처음 세 필드에 리틀 엔디언을 사용했고, 표준 UUID는 빅 엔디언(네트워크 바이트 순서)을 사용했습니다(SnapUtils).
2026년이 되면서 이는 주로 명명 관례가 되었습니다. RFC 9562 하에서 두 표준은 동일하게 동작합니다. .NET의 Guid.NewGuid()는 Python의 uuid.uuid4()와 완전히 호환됩니다. Windows/Azure 진영에서는 “GUID”를, Linux와 오픈소스 커뮤니티에서는 “UUID”를 듣게 됩니다.
현대 UUID 구현: 언어별
| 언어 | UUID v4 | UUID v7 |
|---|---|---|
| Python | 내장 uuid 모듈 |
uuid6 또는 uuid7 패키지 |
| JavaScript | crypto.randomUUID() |
uuid npm 패키지(v10+) |
| PostgreSQL | gen_random_uuid()(PG 13+) |
네이티브 uuidv7()(PG 17+) 또는 확장 |
| .NET | Guid.NewGuid() |
커뮤니티 패키지 |
| Rust | uuid 크레이트(v1.7+) |
v7 기능을 켠 uuid 크레이트 |
결정적 ID: UUID v5
주어진 입력(예: URL이나 사용자 이름)에 대해 매번 같은 ID 가 필요하다면 UUID v5 를 사용하세요. 네임스페이스 UUID와 이름 문자열을 SHA-1으로 해시합니다——중앙 데이터베이스를 조회할 수 없을 때 중복 제거에 완벽합니다.
UUID v1의 프라이버시 교훈
UUID v1 은 타임스탬프와 컴퓨터의 MAC 주소를 사용합니다. 하드웨어 정보를 누출하기 때문에 대부분 폐기되었습니다. 유명한 사례: 멜리사 바이러스 제작자는 감염된 Word 문서의 UUID에 그의 특정 MAC 주소가 포함되어 있어 적발되었습니다.
고급 RFC 9562: v6, v8, 특수 UUID
RFC 9562는 틈새 분산 시스템 요구를 위한 특화 버전을 추가했습니다:
| 버전 | 목적 | 사용 시기 |
|---|---|---|
| v6 | 재정렬된 v1 타임스탬프——정렬 가능하면서 v1의 정밀도 유지 | 레거시 v1 시스템 마이그레이션 |
| v8 | 커스텀——122비트를 개발자 정의 데이터에 사용 | 실험적 또는 벤더별 방식 |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
Null 자리 표시자 |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
범위 끝점 표시자 |
결론
RFC 9562는 현대 클라우드 시대를 위한 고유 식별자를 업데이트했습니다. 실용적 가이드:
- 데이터베이스 기본 키 → UUID v7 을 사용해 시간 정렬, 단편화 없는 삽입 구현
- 일반 무작위성 → UUID v4는 여전히 문제없음
- 중복 제거 → UUID v5가 결정적 ID 제공
- 저장 → 항상 Binary(16) 또는 네이티브 UUID 타입 사용, 문자열은 금지
실행 항목: 데이터베이스 스키마를 점검하세요. 수백만 행이 있는 테이블에서 UUID v4를 기본 키로 사용 중이라면, UUID v7로 마이그레이션하는 것은 간단한 변경으로 인덱스 단편화를 크게 줄이고 쿼리를 가속할 수 있습니다.
자주 묻는 질문
UUID와 GUID가 같은가요?
기능적으로는 그렇습니다. GUID는 UUID 표준의 Microsoft 구현입니다. RFC 9562 하에서 동작은 동일합니다——.NET, Java, Python 애플리케이션에서 서로 교환해 사용할 수 있습니다.
현실 시나리오에서 두 UUID가 충돌할 수 있나요?
수학적으로 가능하지만 현실적으로는 불가능합니다. UUID v4의 경우 50% 충돌 확률에 도달하려면 약 2.71 퀸틸리언 개의 ID를 생성해야 합니다. Generate-Random.org 에 따르면, 초당 10억 개의 UUID를 85년간 생성해도 단일 충돌이 일어날 확률은 50%에 불과합니다.
데이터베이스에서 UUID를 문자열로 저장해야 하나요, 바이너리로 저장해야 하나요?
항상 Binary(16) 또는 네이티브 UUID 타입(PostgreSQL에서 사용 가능)을 우선하세요. 36자 문자열은 2배 이상의 공간을 소비하고 인덱스 조회와 조인을 현저히 느리게 합니다. SnapUtils 는 저장을 컴팩트하게 유지할 때 RFC 9562의 성능 이점이 극대화된다고 지적합니다.
UUID v4 대신 UUID v5를 써야 할 때는 언제인가요?
결정적 ID가 필요할 때, 즉 같은 입력이 항상 같은 UUID를 생성하고 데이터베이스 조회 없이 그렇게 하고 싶을 때 v5 를 사용하세요. 완전한 무작위성이 필요하고 식별자를 출처로 역추적할 수 없게 만들고 싶을 때 v4 를 사용하세요.
답글 남기기