
每一個現代資料庫、分散式系統和 API 都在使用唯一識別碼——而在 2026 年,規範它們的標準已經發生了根本性變化。UUID(通用唯一識別碼,Universally Unique Identifier) 是一個 128 位元的標籤,可以在沒有任何中央協調的情況下跨電腦系統識別資訊。根據新的 RFC 9562(於 2024 年 5 月取代了 RFC 4122),格局已經改變:UUID v4 仍然是隨機 ID 的首選,但 UUID v7 現在是資料庫主鍵的推薦標準,因為其時間有序的結構能防止 B 樹索引碎片化。
本指南涵蓋全貌:UUID 如何運作、何時使用哪個版本,以及如何正確實作它們。
理解 RFC 9562:現代 UUID 標準
UUID 是一個 128 位元的數字,幾乎可以保證唯一——無需任何中央機構。根據 維基百科,兩個 UUID 發生碰撞的機率接近於零,在實際應用中被認為是不可能的。不同團隊可以獨立標記資料,確信他們的 ID 不會衝突。
2024 年 5 月,IETF 發布了 RFC 9562,廢止了舊的 RFC 4122。這次更新回應了現代分散式系統的需求,它們需要既唯一_又_可按時間排序的 ID。三個新版本被引入:v6、v7 和 v8。
UUID 的解剖:版本與變體
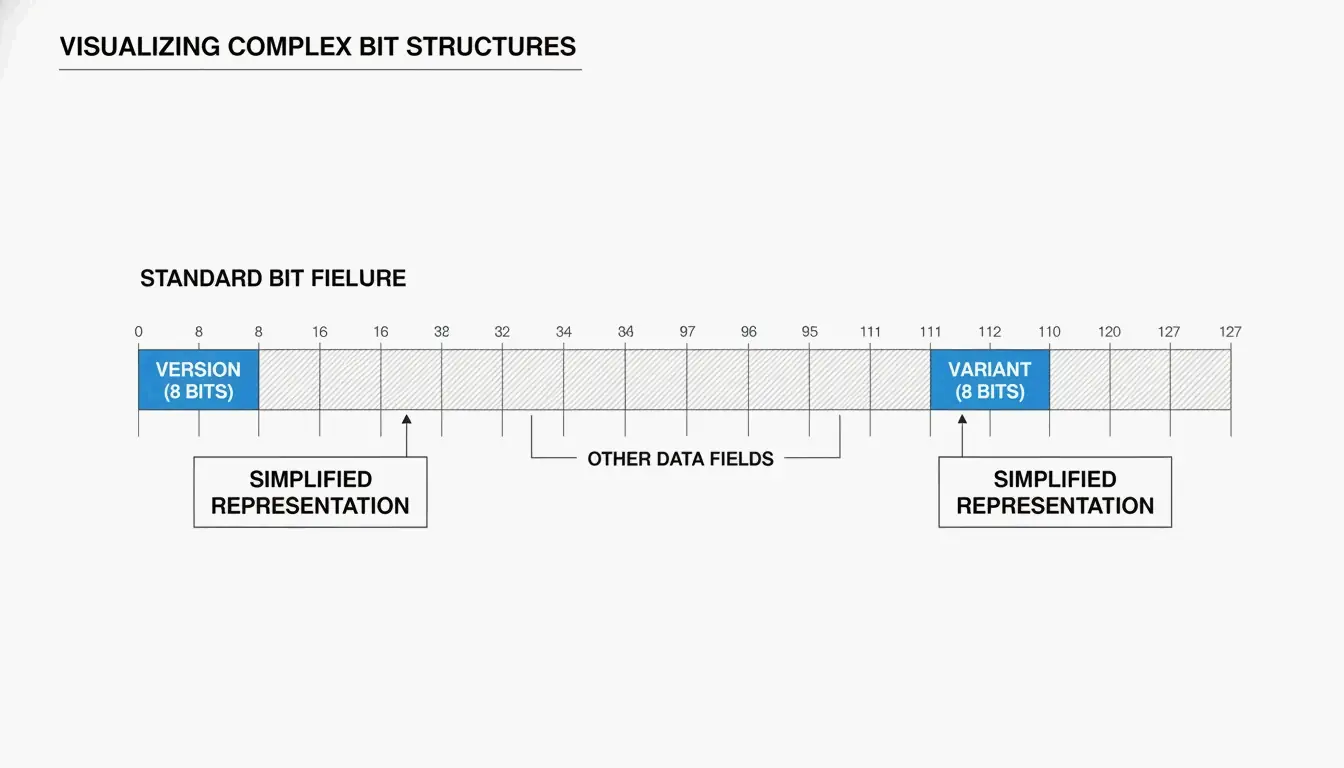
你通常會把 UUID 看作 32 個十六進位字元,用連字號分成五組(8-4-4-4-12):
550e8400-e29b-41d4-a716-446655440000
^
version
兩個關鍵欄位告訴你 UUID 是如何產生的:
| 欄位 | 位置 | 它告訴你什麼 |
|---|---|---|
| 版本位元 | 第 7 個位元組的前 4 位元(第 3 組的第一個字元) | 使用了哪種演算法(例如 “4” = v4,”7″ = v7) |
| 變體位元 | 第 9 個位元組 | UUID 變體——RFC 9562 使用 10 位元模式 |
正如 SnapUtils 所解釋的,變體位元將現代 RFC 9562 UUID 與早期的 Apollo 或微軟格式區分開來。
為什麼 UUID v7 是資料庫的新黃金標準
UUID v4 最大的缺點是它完全隨機。當用作 B 樹索引 的主鍵時,資料庫不得不在不可預測的位置插入新列。根據 CreateUUID 的說法,這會導致 「分頁分裂」(page splits)——資料庫必須不斷重組資料騰出空間,導致寫入變慢並浪費記憶體。
UUID v7 透過在 ID 開頭放置一個 48 位元 Unix 紀元時間戳記(毫秒精度)來解決這個問題。這使得 ID 單調遞增——新的總是比舊的大。資料庫只需追加到索引末尾,就能給你順序整數般的效能加上 UUID 的全域唯一性。
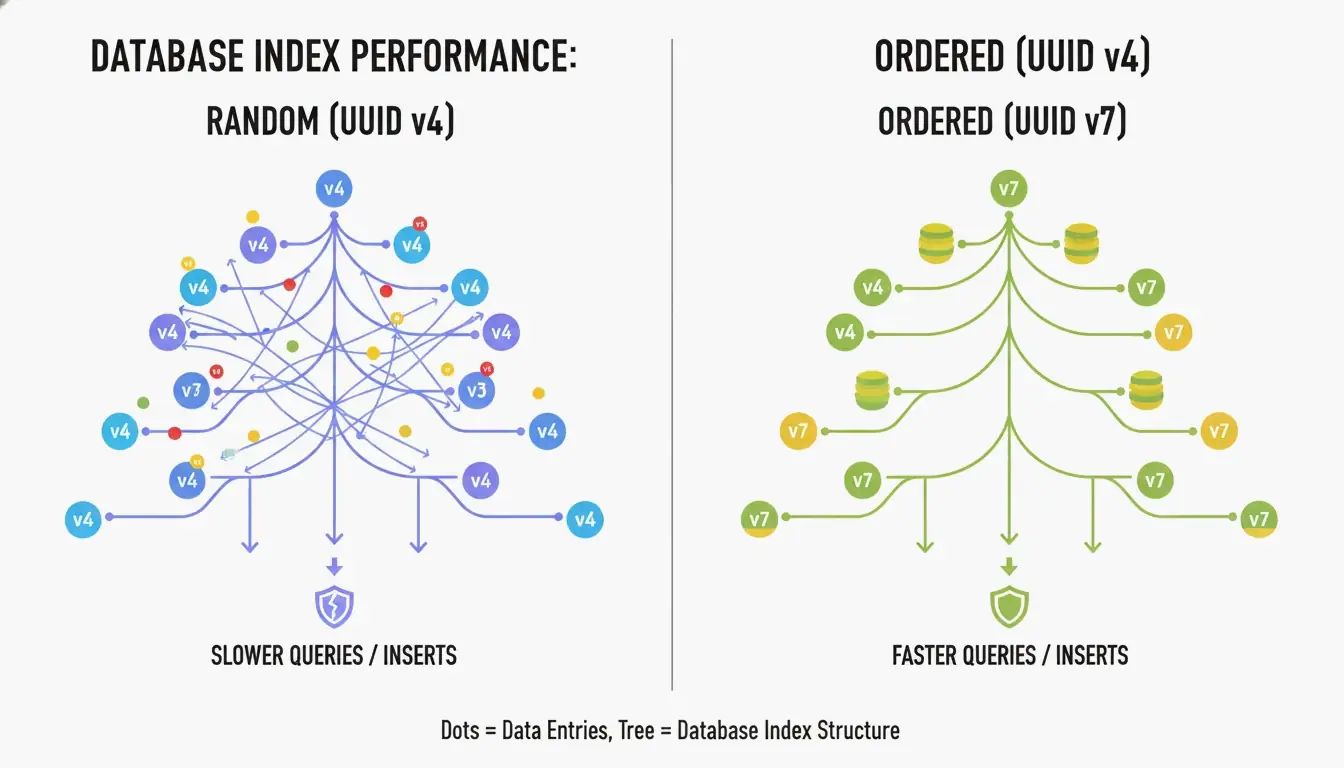
UUID v7 如何平衡時間與熵
UUID v7 使用 CSPRNG(密碼學安全偽隨機數產生器) 填充剩餘的 74 位元。根據 維基百科,你需要以每秒約 10 億個 UUID 的速度產生 85 年才能達到 50% 的碰撞機率。對於任何實際應用,UUID v7 實際上是防碰撞的。
儲存最佳實踐:Binary(16) vs String(36)
如何儲存 UUID 與使用哪個版本同樣重要:
| 儲存格式 | 空間 | 索引效能 | 建議 |
|---|---|---|---|
| Binary(16) | 16 位元組 | 高(緊湊) | 最佳實踐 |
| 原生 UUID 型別 | 16 位元組 | 高(最佳化) | 最適合 PostgreSQL |
| 字串(Char 36) | 36–72 位元組 | 低(碎片化) | 避免 |
SnapUtils 建議始終使用原生型別而非字串。在 PostgreSQL 中,原生 uuid 型別以緊湊的 16 位元組二進位格式儲存資料,同時仍支援標準的基於字串的查詢。
UUID vs GUID:有差異嗎?
GUID(全域唯一識別碼,Globally Unique Identifier) 是微軟對 UUID 標準的實作。從歷史上看,位元組順序(端序)存在差異——早期微軟 GUID 的前三個欄位使用小端序,而標準 UUID 使用大端序(網路位元組順序)(SnapUtils)。
到 2026 年,這主要是一個命名慣例。在 RFC 9562 下,它們的運作方式完全相同。.NET 中的 Guid.NewGuid() 與 Python 中的 uuid.uuid4() 完全相容。你會在 Windows/Azure 圈子聽到「GUID」,而在 Linux 和開源社群聽到「UUID」。
實作現代 UUID:逐語言說明
| 語言 | UUID v4 | UUID v7 |
|---|---|---|
| Python | 內建 uuid 模組 |
uuid6 或 uuid7 套件 |
| JavaScript | crypto.randomUUID() |
uuid npm 套件(v10+) |
| PostgreSQL | gen_random_uuid()(PG 13+) |
原生 uuidv7()(PG 17+)或擴充功能 |
| .NET | Guid.NewGuid() |
社群套件 |
| Rust | uuid crate(v1.7+) |
帶 v7 feature 的 uuid crate |
確定性 ID:UUID v5
如果你需要為給定輸入(如 URL 或使用者名稱)每次都產生 相同的 ID,請使用 UUID v5。它使用 SHA-1 對命名空間 UUID 和名稱字串進行雜湊——當你無法查詢中央資料庫時,非常適合用於去重。
UUID v1 的隱私教訓
UUID v1 使用時間戳記和電腦的 MAC 位址。它已基本被廢棄,因為它會洩露硬體資訊。一個著名的例子:Melissa 病毒的製造者之所以被抓,是因為受感染 Word 文件中的 UUID 包含了他特定的 MAC 位址。
進階 RFC 9562:v6、v8 和特殊 UUID
RFC 9562 為小眾分散式系統需求加入了專用版本:
| 版本 | 用途 | 何時使用 |
|---|---|---|
| v6 | 重新排序的 v1 時間戳記——可排序同時保留 v1 的精度 | 遷移舊版 v1 系統 |
| v8 | 自訂——122 位元用於開發者定義的資料 | 實驗性或廠商專用方案 |
| Nil UUID | 00000000-0000-0000-0000-000000000000 |
空佔位符 |
| Max UUID | FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF |
範圍端點標記 |
結論
RFC 9562 為現代雲端時代更新了唯一識別碼。實用建議:
- 資料庫主鍵 → 使用 UUID v7,實現時間有序、無碎片化的插入
- 一般隨機性 → UUID v4 仍然完全沒問題
- 去重 → UUID v5 給你確定性的 ID
- 儲存 → 始終使用 Binary(16) 或原生 UUID 型別,絕不用字串
行動項: 檢查你的資料庫 schema。如果你在擁有數百萬列的資料表中使用 UUID v4 作為主鍵,遷移到 UUID v7 是一個簡單的改動,可以顯著減少索引碎片化並加快查詢速度。
常見問題
UUID 和 GUID 一樣嗎?
功能上,是的。GUID 是微軟對 UUID 標準的實作。在 RFC 9562 下,它們的行為完全相同——你可以在 .NET、Java 和 Python 應用中互換使用。
在現實場景中兩個 UUID 會碰撞嗎?
數學上可能,實際上不可能。對於 UUID v4,你需要產生大約 2.71 百億億(quintillion) 個 ID 才能達到 50% 的碰撞機率。根據 Generate-Random.org,以每秒 10 億個 UUID 的速度產生 85 年,你只有 50% 的機會出現單次碰撞。
我應該在資料庫中把 UUID 存為字串還是二進位?
始終優先使用 Binary(16) 或 原生 UUID 型別(PostgreSQL 中可用)。36 字元的字串消耗超過兩倍的空間,並顯著拖慢索引查詢和連接。SnapUtils 指出,當儲存保持緊湊時,RFC 9562 的效能優勢才能最大化。
什麼時候該用 UUID v5 而不是 UUID v4?
當你需要確定性 ID 時使用 v5——相同的輸入總是產生相同的 UUID,無需查詢資料庫。當你需要完全隨機性並希望確保識別碼無法被逆向工程回其來源時,使用 v4。
發佈留言